

Question
In this question, we will use java to implement the algorithms mentioned in this question: https://www.chegg.com/homework-help/questions-and-answers/course-algorithms-data-structure-based-question-answer-https-wwwcheggcom-homework-help-que-q107659115 Course: algorithms of data structure Send a picture of
In this question, we will use java to implement the algorithms mentioned in this question: https://www.chegg.com/homework-help/questions-and-answers/course-algorithms-data-structure-based-question-answer-https-wwwcheggcom-homework-help-que-q107659115
Course: algorithms of data structure
Send a picture of the code and write with it a comment
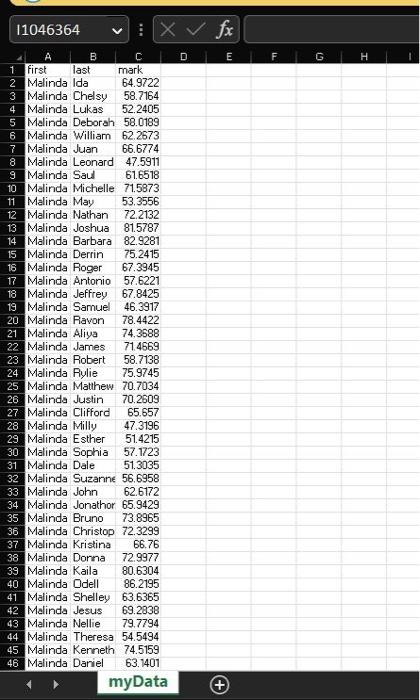
(picture attached) myData.csv: a CSV file of student marks (first name, last name, mark). excel sheet of the question, please note it contains three columns (the first column is the first name, the second column is the last name and the third column is the mark) it has also 1048576 rows. here is a part of the excel please let me know if any other is needed.
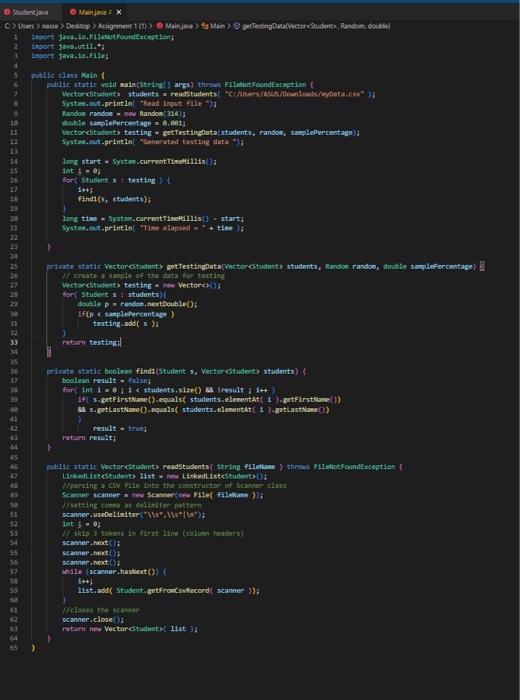
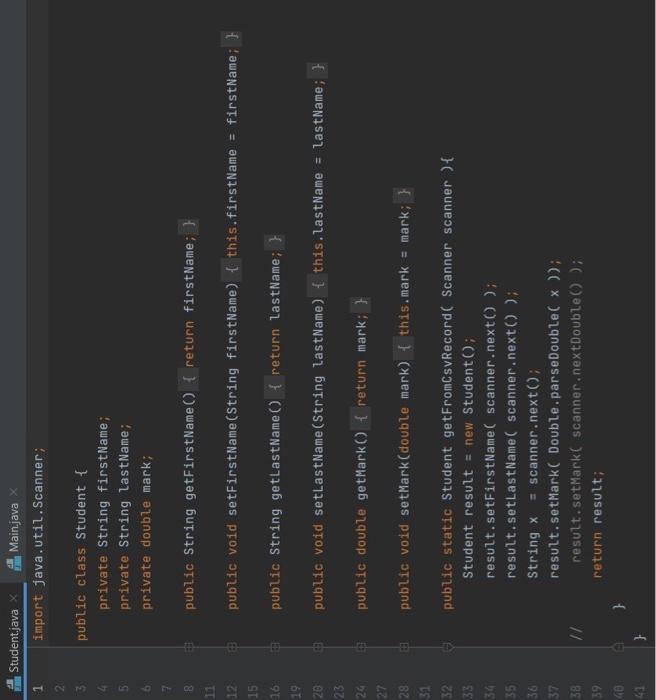
Student.jav: contains Class Student, which has 3 fields (firstName, lastName, mark) and several useful methods
Main.java: the main running file, which has the following useful functions (attached with picture)
readStudents: a function for reading the attached csv file into a Vector of class Student. (attached with picture)
getTestingData: a function for generating testing data from the original data set
find1: a function that finds a student mark using first name and last name using the naive approach (searching the full list of students one by one until it finds a student with exact first and last name)
main: a function that computes the running time of the naive approach.
Your goal is to find out which approach is the fastest for finding a student by both first and last names. You shall do the following:
implement Kimo approach
implement Shadi approach
implement a third approach that uses a hashtable where the key is class Student and the value is the mark (hint: you will need to override hashcode and equals of Student).
What are the running times of all 4 approaches (the above 3 approaches and the naive approach) following the same method outline in function main? Which one is fastest?
please make sure that the answer is correct, I will vote up and write a good review for sure if the answer is correct. needed urgently Thanks
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Introduction To Database And Knowledge Base Systems
Authors: S Krishna
1st Edition
9810206208, 978-9810206208