

Question
IN WEKA. The data set has seven attributes that are related to the health condition. They have been measured for 20 days (dayID) and four
IN WEKA. The data set has seven attributes that are related to the health condition. They have been measured for 20 days (dayID) and four times per day (sequenceID). Hrv and hr indicate heart rate variability (the specific changes in time) and heart rate, respectively.
1.Which attribute can be selected for a dependent variable of this data?
2. Which attributes are strongly related to the dependent variable? How can you decide? (InfoGainAttributeEval -> Ranker)
3.Try to train a machine using Logistic (Classify tab -> Choose -> functions -> Logistic). How is the performance of the classifiers? If you want to improve the performance, which attributes would you remove? Remove them and see the trained performance of the new logistic classifier. Is it improved?
4.Try to train a machine using J48 (Classify tab -> Choose -> trees -> J48) and compare the result with the Logistic classifier. Which one is better?
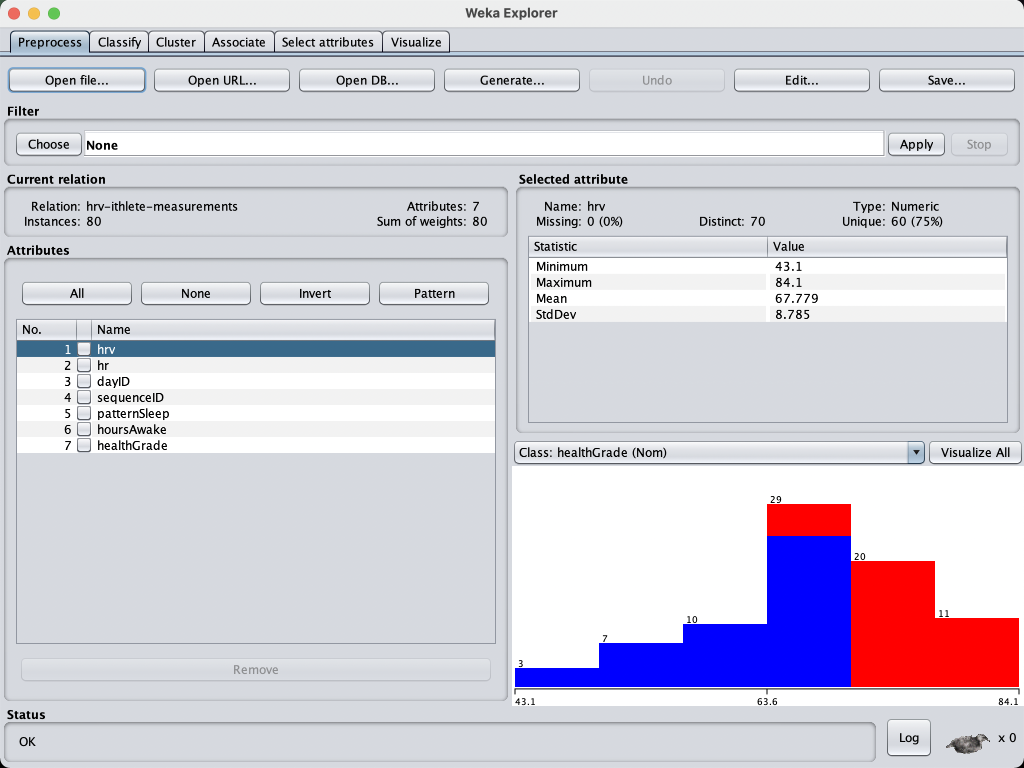
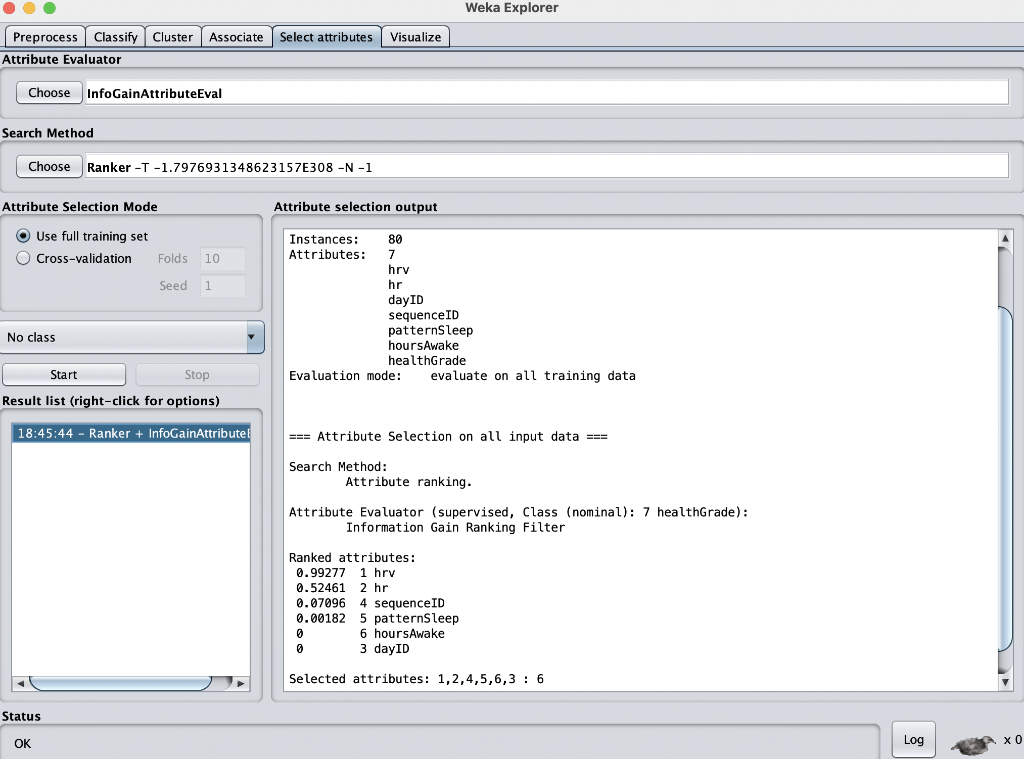
Weka Explorer \begin{tabular}{|l|l|l|l|l|l|} \hline Preprocess & Classify & Cluster & Associate & Select attributes & Visualize \\ \cline { 2 - 5 } \end{tabular} Filter Choose None Apply Stop Current relation Selected attribute Relation: Instances: Attributes 29 Remove Status OK Weka Explorer Attribute Evaluator Choose InfoGainAttributeEval Search Method Choose Ranker -T -1.7976931348623157E308 -N -1 Status OK
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Deductive And Object Oriented Databases Third International Conference Dood 93 Phoenix Arizona Usa December 6 8 1993 Proceedings Lncs 760
Authors: Stefano Ceri ,Katsumi Tanaka ,Shalom Tsur
1993rd Edition
3540575308, 978-3540575306