

Question
INTRODUCTION: QUESTION: PARSER TEMPLATE: import re import sys class Scanner: '''The interface comprises the methods lookahead and consume. Other methods should not be called from
INTRODUCTION:
QUESTION:

PARSER TEMPLATE:
import re import sys
class Scanner: '''The interface comprises the methods lookahead and consume. Other methods should not be called from outside of this class.'''
def __init__(self, input_file): '''Reads the whole input_file to input_string, which remains constant. current_char_index counts how many characters of input_string have been consumed. current_token holds the most recently found token and the corresponding part of input_string.''' # source code of the program to be compiled self.input_string = input_file.read() # index where the unprocessed part of input_string starts self.current_char_index = 0 # a pair (most recently read token, matched substring of input_string) self.current_token = self.get_token()
def skip_white_space(self): '''Consumes all characters in input_string up to the next non-white-space character.''' raise Exception('skip_white_space not implemented')
def no_token(self): '''Stop execution if the input cannot be matched to a token.''' print('lexical error: no token found at the start of ' + self.input_string[self.current_char_index:]) sys.exit()
def get_token(self): '''Returns the next token and the part of input_string it matched. The returned token is None if there is no next token. The characters up to the end of the token are consumed. TODO: Raise an exception by calling no_token() if the input contains extra non-white-space characters that do not match any token.''' self.skip_white_space() # find the longest prefix of input_string that matches a token token, longest = None, '' for (t, r) in Token.token_regexp: match = re.match(r, self.input_string[self.current_char_index:]) if match and match.end() > len(longest): token, longest = t, match.group() # consume the token by moving the index to the end of the matched part self.current_char_index += len(longest) return (token, longest)
def lookahead(self): '''Returns the next token without consuming it. Returns None if there is no next token.''' return self.current_token[0]
def unexpected_token(self, found_token, expected_tokens): '''Stop execution because an unexpected token was found. found_token contains just the token, not its value. expected_tokens is a sequence of tokens.''' print('syntax error: token in ' + repr(sorted(expected_tokens)) + ' expected but ' + repr(found_token) + ' found') sys.exit()
def consume(self, *expected_tokens): '''Returns the next token and consumes it, if it is in expected_tokens. Calls unexpected_token(...) otherwise. If the token is a number or an identifier, not just the token but a pair of the token and its value is returned.''' raise Exception('consume not implemented')
class Token: # The following enumerates all tokens. DO = 'DO' ELSE = 'ELSE' END = 'END' IF = 'IF' THEN = 'THEN' WHILE = 'WHILE' SEM = 'SEM' BEC = 'BEC' LESS = 'LESS' EQ = 'EQ' GRTR = 'GRTR' LEQ = 'LEQ' NEQ = 'NEQ' GEQ = 'GEQ' ADD = 'ADD' SUB = 'SUB' MUL = 'MUL' DIV = 'DIV' LPAR = 'LPAR' RPAR = 'RPAR' NUM = 'NUM' ID = 'ID'
# The following list gives the regular expression to match a token. # The order in the list matters for mimicking Flex behaviour. # Longer matches are preferred over shorter ones. # For same-length matches, the first in the list is preferred. token_regexp = [ (DO, 'do'), (ELSE, 'else'), (END, 'end'), (IF, 'if'), (THEN, 'then'), (WHILE, 'while'), (SEM, ';'), (BEC, ':='), (LESS, ''), (LEQ, '='), (ADD, '\\+'), # + is special in regular expressions (SUB, '-'), (LPAR, '\\('), # ( is special in regular expressions (RPAR, '\\)'), # ) is special in regular expressions (ID, '[a-z]+'), ]
def indent(s, level): return ' '*level + s + ' '
# Each of the following classes is a kind of node in the abstract syntax tree. # indented(level) returns a string that shows the tree levels by indentation.
class Program_AST: def __init__(self, program): self.program = program def __repr__(self): return repr(self.program) def indented(self, level): return self.program.indented(level)
class Statements_AST: def __init__(self, statements): self.statements = statements def __repr__(self): result = repr(self.statements[0]) for st in self.statements[1:]: result += '; ' + repr(st) return result def indented(self, level): result = indent('Statements', level) for st in self.statements: result += st.indented(level+1) return result
class If_AST: def __init__(self, condition, then): self.condition = condition self.then = then def __repr__(self): return 'if ' + repr(self.condition) + ' then ' + \ repr(self.then) + ' end' def indented(self, level): return indent('If', level) + \ self.condition.indented(level+1) + \ self.then.indented(level+1)
class While_AST: def __init__(self, condition, body): self.condition = condition self.body = body def __repr__(self): return 'while ' + repr(self.condition) + ' do ' + \ repr(self.body) + ' end' def indented(self, level): return indent('While', level) + \ self.condition.indented(level+1) + \ self.body.indented(level+1)
class Assign_AST: def __init__(self, identifier, expression): self.identifier = identifier self.expression = expression def __repr__(self): return repr(self.identifier) + ':=' + repr(self.expression) def indented(self, level): return indent('Assign', level) + \ self.identifier.indented(level+1) + \ self.expression.indented(level+1)
class Write_AST: def __init__(self, expression): self.expression = expression def __repr__(self): return 'write ' + repr(self.expression) def indented(self, level): return indent('Write', level) + self.expression.indented(level+1)
class Read_AST: def __init__(self, identifier): self.identifier = identifier def __repr__(self): return 'read ' + repr(self.identifier) def indented(self, level): return indent('Read', level) + self.identifier.indented(level+1)
class Comparison_AST: def __init__(self, left, op, right): self.left = left self.op = op self.right = right def __repr__(self): return repr(self.left) + self.op + repr(self.right) def indented(self, level): return indent(self.op, level) + \ self.left.indented(level+1) + \ self.right.indented(level+1)
class Expression_AST: def __init__(self, left, op, right): self.left = left self.op = op self.right = right def __repr__(self): return '(' + repr(self.left) + self.op + repr(self.right) + ')' def indented(self, level): return indent(self.op, level) + \ self.left.indented(level+1) + \ self.right.indented(level+1)
class Number_AST: def __init__(self, number): self.number = number def __repr__(self): return self.number def indented(self, level): return indent(self.number, level)
class Identifier_AST: def __init__(self, identifier): self.identifier = identifier def __repr__(self): return self.identifier def indented(self, level): return indent(self.identifier, level)
# The following methods comprise the recursive-descent parser.
def program(): sts = statements() return Program_AST(sts)
def statements(): result = [statement()] while scanner.lookahead() == Token.SEM: scanner.consume(Token.SEM) st = statement() result.append(st) return Statements_AST(result)
def statement(): if scanner.lookahead() == Token.IF: return if_statement() elif scanner.lookahead() == Token.WHILE: return while_statement() elif scanner.lookahead() == Token.ID: return assignment() else: # error return scanner.consume(Token.IF, Token.WHILE, Token.ID)
def if_statement(): scanner.consume(Token.IF) condition = comparison() scanner.consume(Token.THEN) then = statements() scanner.consume(Token.END) return If_AST(condition, then)
def while_statement(): scanner.consume(Token.WHILE) condition = comparison() scanner.consume(Token.DO) body = statements() scanner.consume(Token.END) return While_AST(condition, body)
def assignment(): ident = identifier() scanner.consume(Token.BEC) expr = expression() return Assign_AST(ident, expr)
operator = { Token.LESS:'', Token.LEQ:'=', Token.ADD:'+', Token.SUB:'-', Token.MUL:'*', Token.DIV:'/' }
def comparison(): left = expression() op = scanner.consume(Token.LESS, Token.EQ, Token.GRTR, Token.LEQ, Token.NEQ, Token.GEQ) right = expression() return Comparison_AST(left, operator[op], right)
def expression(): result = term() while scanner.lookahead() in [Token.ADD, Token.SUB]: op = scanner.consume(Token.ADD, Token.SUB) tree = term() result = Expression_AST(result, operator[op], tree) return result
def term(): result = factor() while scanner.lookahead() in [Token.MUL, Token.DIV]: op = scanner.consume(Token.MUL, Token.DIV) tree = factor() result = Expression_AST(result, operator[op], tree) return result
def factor(): if scanner.lookahead() == Token.LPAR: scanner.consume(Token.LPAR) result = expression() scanner.consume(Token.RPAR) return result elif scanner.lookahead() == Token.NUM: value = scanner.consume(Token.NUM)[1] return Number_AST(value) elif scanner.lookahead() == Token.ID: return identifier() else: # error return scanner.consume(Token.LPAR, Token.NUM, Token.ID)
def identifier(): value = scanner.consume(Token.ID)[1] return Identifier_AST(value)
# Initialise scanner.
scanner = Scanner(sys.stdin)
# Uncomment the following to test the scanner without the parser. # Show all tokens in the input. # # token = scanner.lookahead() # while token != None: # if token in [Token.NUM, Token.ID]: # token, value = scanner.consume(token) # print(token, value) # else: # print(scanner.consume(token)) # token = scanner.lookahead() # sys.exit()
# Call the parser.
ast = program() if scanner.lookahead() != None: print('syntax error: end of input expected but token ' + repr(scanner.lookahead()) + ' found') sys.exit()
# Show the syntax tree with levels indicated by indentation.
print(ast.indented(0), end='')
THE FOLLOWING IS THE MENTIONED "PREVIOUSLY EDITED SCANNER TEMPLATE":
import re import sys
class Scanner: '''The interface comprises the methods lookahead and consume. Other methods should not be called from outside of this class.'''
def __init__(self, input_file): '''Reads the whole input_file to input_string, which remains constant. current_char_index counts how many characters of input_string have been consumed. current_token holds the most recently found token and the corresponding part of input_string.''' # source code of the program to be compiled self.input_string = input_file.read() # index where the unprocessed part of input_string starts self.current_char_index = 0 # a pair (most recently read token, matched substring of input_string) self.current_token = self.get_token()
def skip_white_space(self): '''Consumes all characters in input_string up to the next non-white-space character.'''
while self.current_char_index
def no_token(self): '''Stop execution if the input cannot be matched to a token.''' print('lexical error: no token found at the start of ' + self.input_string[self.current_char_index:]) exit()
def get_token(self): '''Returns the next token and the part of input_string it matched. The returned token is None if there is no next token. The characters up to the end of the token are consumed. TODO: Raise an exception by calling no_token() if the input contains extra non-white-space characters that do not match any token.''' self.skip_white_space() # find the longest prefix of input_string that matches a token token, longest = None, '' for (t, r) in Token.token_regexp: match = re.match(r, self.input_string[self.current_char_index:]) if match and match.end() > len(longest): token, longest = t, match.group() if token == None and self.current_char_index
def lookahead(self): '''Returns the next token without consuming it. Returns None if there is no next token.''' return self.current_token[0]
def unexpected_token(self, found_token, expected_tokens): '''Stop execution if an unexpected token is found.''' print('syntax error: token in ' + repr(expected_tokens) + ' expected but ' + repr(found_token) + ' found') exit()
def consume(self, *expected_tokens): '''Returns the next token and consumes it, if it is in expected_tokens. Calls unexpected_token(...) otherwise. If the token is a number or an identifier, not just the token but a pair of the token and its value is returned.'''
current = self.current_token if current[0] in expected_tokens: self.current_token = self.get_token() if current[0] == 'NUM' or current[0] == 'ID': return current else: return current[0] else: self.unexpected_token(current[0], expected_tokens)
class Token: # The following enumerates all tokens. DO = 'DO' ELSE = 'ELSE' END = 'END' IF = 'IF' READ = 'READ' THEN = 'THEN' WHILE = 'WHILE' WRITE = 'WRITE' SEM = 'SEM' BEC = 'BEC' LESS = 'LESS' EQ = 'EQ' GRTR = 'GRTR' LEQ = 'LEQ' NEQ = 'NEQ' GEQ = 'GEQ' ADD = 'ADD' SUB = 'SUB' MUL = 'MUL' DIV = 'DIV' LPAR = 'LPAR' RPAR = 'RPAR' NUM = 'NUM' ID = 'ID'
# The following list gives the regular expression to match a token. # The order in the list matters for mimicking Flex behaviour. # Longer matches are preferred over shorter ones. # For same-length matches, the first in the list is preferred. token_regexp = [ (DO, 'do'), (ELSE, 'else'), (END, 'end'), (IF, 'if'), (READ, 'read'), (THEN, 'then'), (WHILE, 'while'), (WRITE, 'write'), (SEM, ';'), (BEC, ':='), (LESS, ''), (LEQ, '='), (ADD, '\\+'), # + is special in regular expressions (SUB, '-'), (MUL, '\\*'), (DIV, '\\/'), (LPAR, '\\('), # ( is special in regular expressions (RPAR, '\\)'), # ) is special in regular expressions (NUM, '\d+'), (ID, '[a-z]+'), ]
# Initialise scanner.
scanner = Scanner(sys.stdin)
# Show all tokens in the input.
token = scanner.lookahead() while token != None: if token in [Token.NUM, Token.ID]: token, value = scanner.consume(token) print(token, value) else: print(scanner.consume(token)) token = scanner.lookahead()
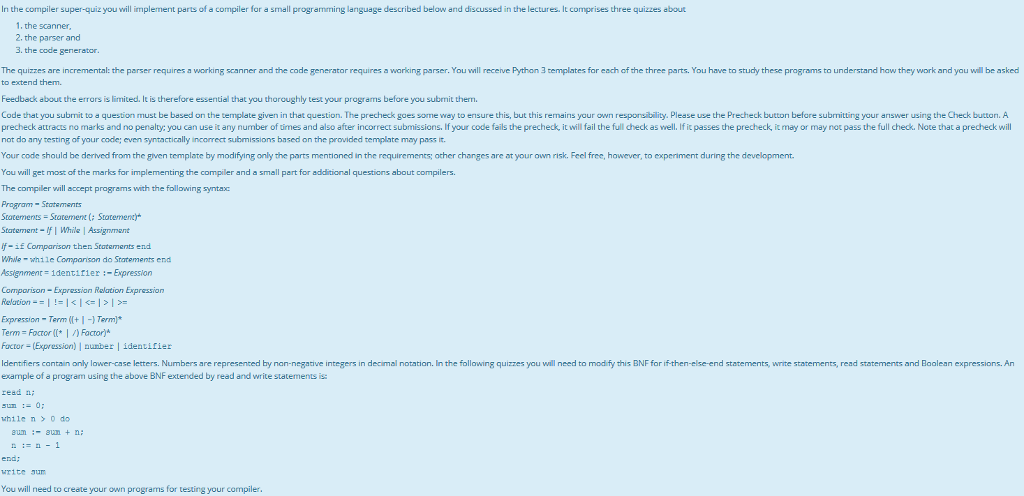
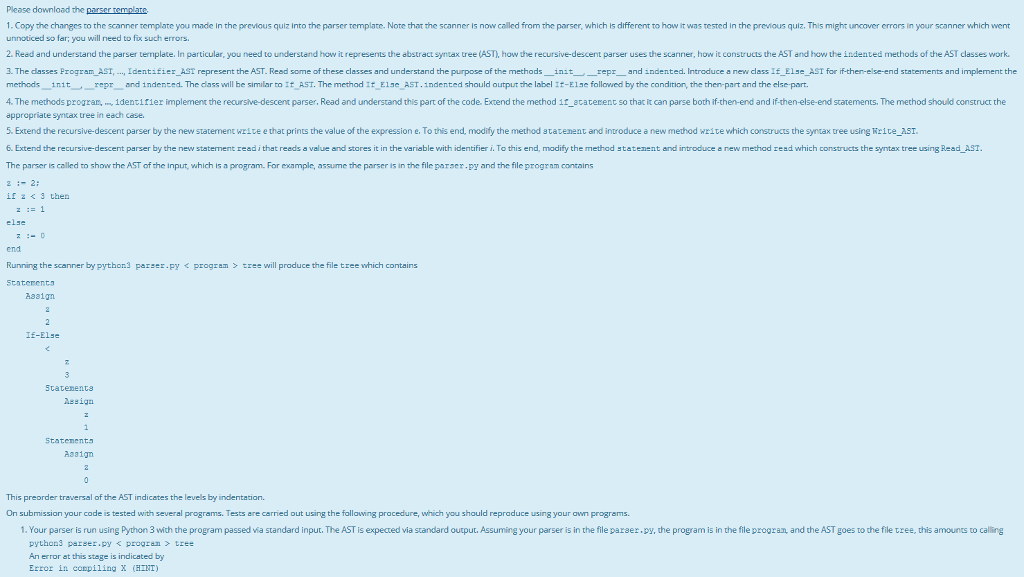
In the compiler super-quiz you will implement parts of a compiler for a small programming language described below and discussed in the lectures. It comprises three quizzes about 1, the scanner 2. the parser 3. the code generator The quizzes are incremental: the parser requires a working scanner and the code generator requires a warking parser. You will receive Python 3 templates for each of the three parts. You have to study these programs to understand haw they work and yau will be asked to extend them Feedback about the errors is limited. It is therefore essential that you thoroughly test your programs before you subrmit then Code that you submit to a question must be based on the template given in that question. The precheck goes some way to ensure this, but this remains your own resporsibility. Please use the Precheck button before submitting your answer using the Check button. A echeck attracts no marks and no penalty:you can use it any number of uimes and also after incorrect submissions. If your code fails the precheck, it will fail the full check as well. If it passes the precheck it may or may not pass the full check, Note that a precheck will not do any testing of your code; even syntactically incorrect submissions based on the provided template may pass it Your code should be derived from the given template by modifying only the parts mentioned in the requirements; ather changes are at your own risk. Feel free, however, to experiment during the development. You will get most of the marks for implementing the compiler and a small part for additional questions about compilers The compiler will accept pragrams with the following syntax Program- Statements Statements Statemene : Stotemenc* Statement If I While | Assignment f-if Comparison then Statements end Whwe-while Comparison do Statements end Assignment- 1dentifier:- Expression Comparison-Expression Relation Expression Expression-Term(I+- Term)* Term Foctor* | ) Factor* Factor -(Expression) nunber | identifier Identifiers cantain anly lower-case letters. Numbers are represented by nan-negative integers in decimal notation. In the following quizzes you will need to modify this BNF for if-then-else-end statements, write statements, read statements and Boolean expressions. An example of a program using the above BNF extended by read and write statements is read n: m0: while nodo umnn n-1 end; You will need to create your own programs for testing your compiler In the compiler super-quiz you will implement parts of a compiler for a small programming language described below and discussed in the lectures. It comprises three quizzes about 1, the scanner 2. the parser 3. the code generator The quizzes are incremental: the parser requires a working scanner and the code generator requires a warking parser. You will receive Python 3 templates for each of the three parts. You have to study these programs to understand haw they work and yau will be asked to extend them Feedback about the errors is limited. It is therefore essential that you thoroughly test your programs before you subrmit then Code that you submit to a question must be based on the template given in that question. The precheck goes some way to ensure this, but this remains your own resporsibility. Please use the Precheck button before submitting your answer using the Check button. A echeck attracts no marks and no penalty:you can use it any number of uimes and also after incorrect submissions. If your code fails the precheck, it will fail the full check as well. If it passes the precheck it may or may not pass the full check, Note that a precheck will not do any testing of your code; even syntactically incorrect submissions based on the provided template may pass it Your code should be derived from the given template by modifying only the parts mentioned in the requirements; ather changes are at your own risk. Feel free, however, to experiment during the development. You will get most of the marks for implementing the compiler and a small part for additional questions about compilers The compiler will accept pragrams with the following syntax Program- Statements Statements Statemene : Stotemenc* Statement If I While | Assignment f-if Comparison then Statements end Whwe-while Comparison do Statements end Assignment- 1dentifier:- Expression Comparison-Expression Relation Expression Expression-Term(I+- Term)* Term Foctor* | ) Factor* Factor -(Expression) nunber | identifier Identifiers cantain anly lower-case letters. Numbers are represented by nan-negative integers in decimal notation. In the following quizzes you will need to modify this BNF for if-then-else-end statements, write statements, read statements and Boolean expressions. An example of a program using the above BNF extended by read and write statements is read n: m0: while nodo umnn n-1 end; You will need to create your own programs for testing your compilerStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Logic In Databases International Workshop Lid 96 San Miniato Italy July 1 2 1996 Proceedings Lncs 1154
Authors: Dino Pedreschi ,Carlo Zaniolo
1st Edition
3540618147, 978-3540618140