

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Java dna1.txt 10 cure for cancer protein ATGCCACTATGGTAG captain sisko leadership protein ATgCCAACATGgATGCCcGATAtGGATTgA Ada Lovelace non protein CCATt-AATgATCa-CAGTt michael phelps protein ATgAG-ATC-CgtgatGTGgg-aT-CCTa-CT-CATTaa maya angelou writer
Java

 dna1.txt
dna1.txt
10 cure for cancer protein ATGCCACTATGGTAG captain sisko leadership protein ATgCCAACATGgATGCCcGATAtGGATTgA Ada Lovelace non protein CCATt-AATgATCa-CAGTt michael phelps protein ATgAG-ATC-CgtgatGTGgg-aT-CCTa-CT-CATTaa maya angelou writer protein AtgC-CaacaTGGATGCCCTAAG-ATAtgGATTagtgA jimi hendrix guitar talent protein atgataattagttttaatatcaga-ctgtaa admiral grace murray hopper protein ATGC-AATT--GC-----TCGA--------TTAG shrek's brain protein ATGATAcctatgagtaaTGTGGACCatatccaaACTATAGGCATtgtcggACCAACGATcgattggtTATACTGA mini me growth hormone AtGgGaCGCTgA smelly cat non protein CAT-CAT-CAT-CAT-CAT-CAT-CAT-CAT-CAT-CAT
dna2.txt
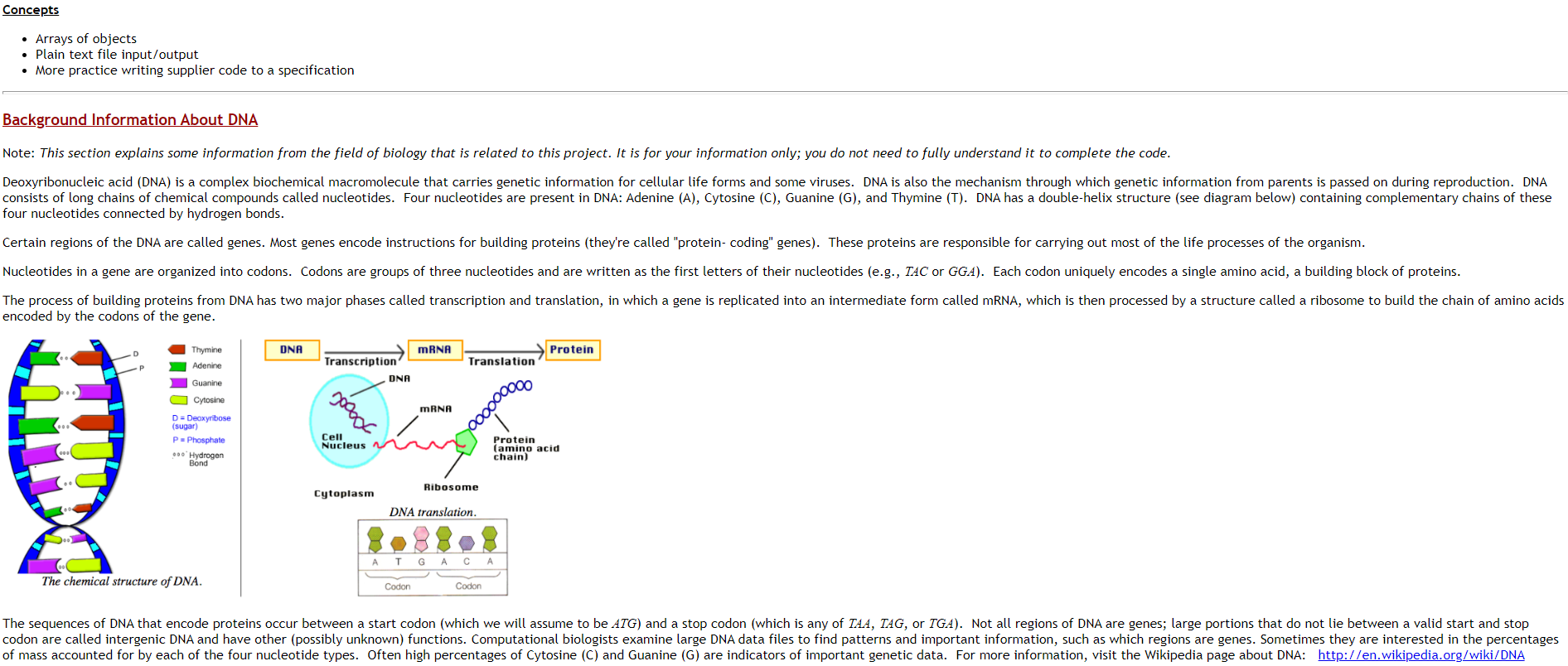
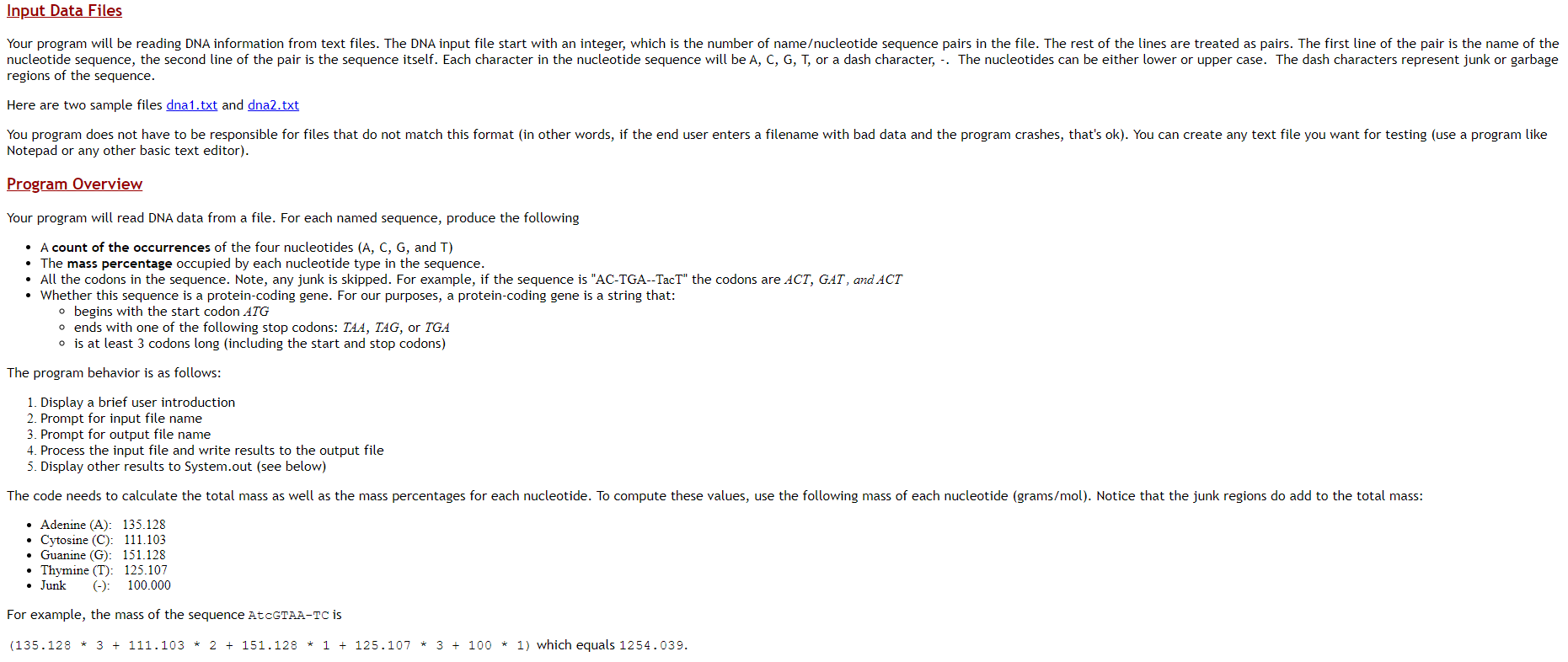
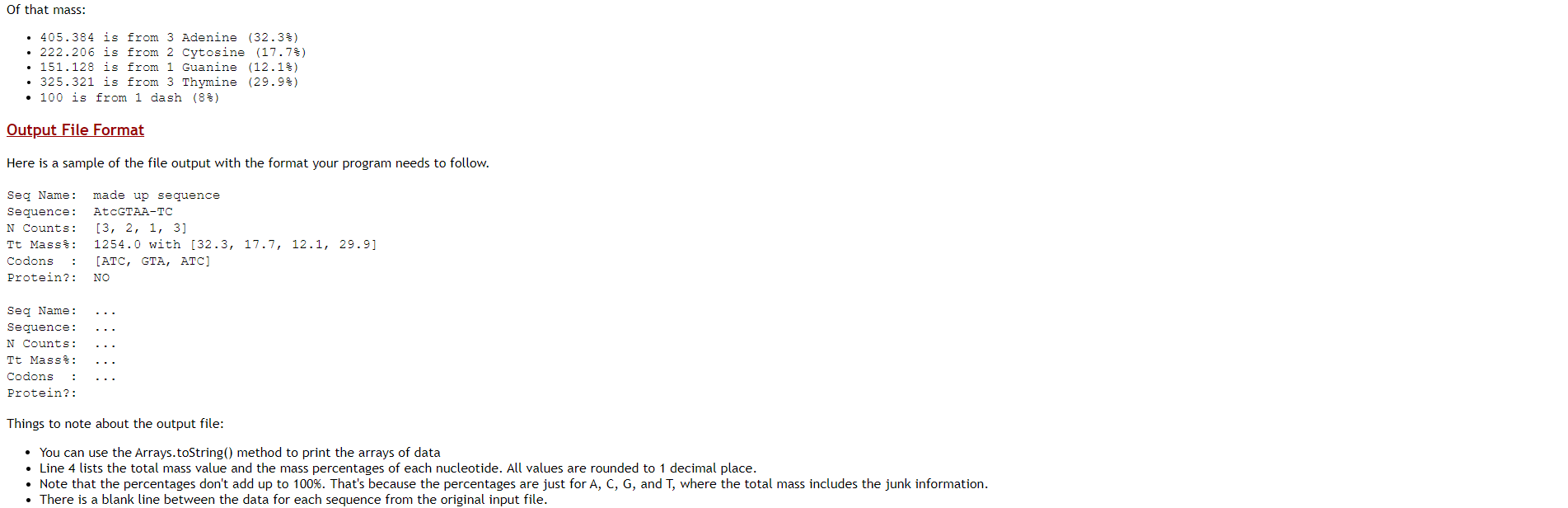
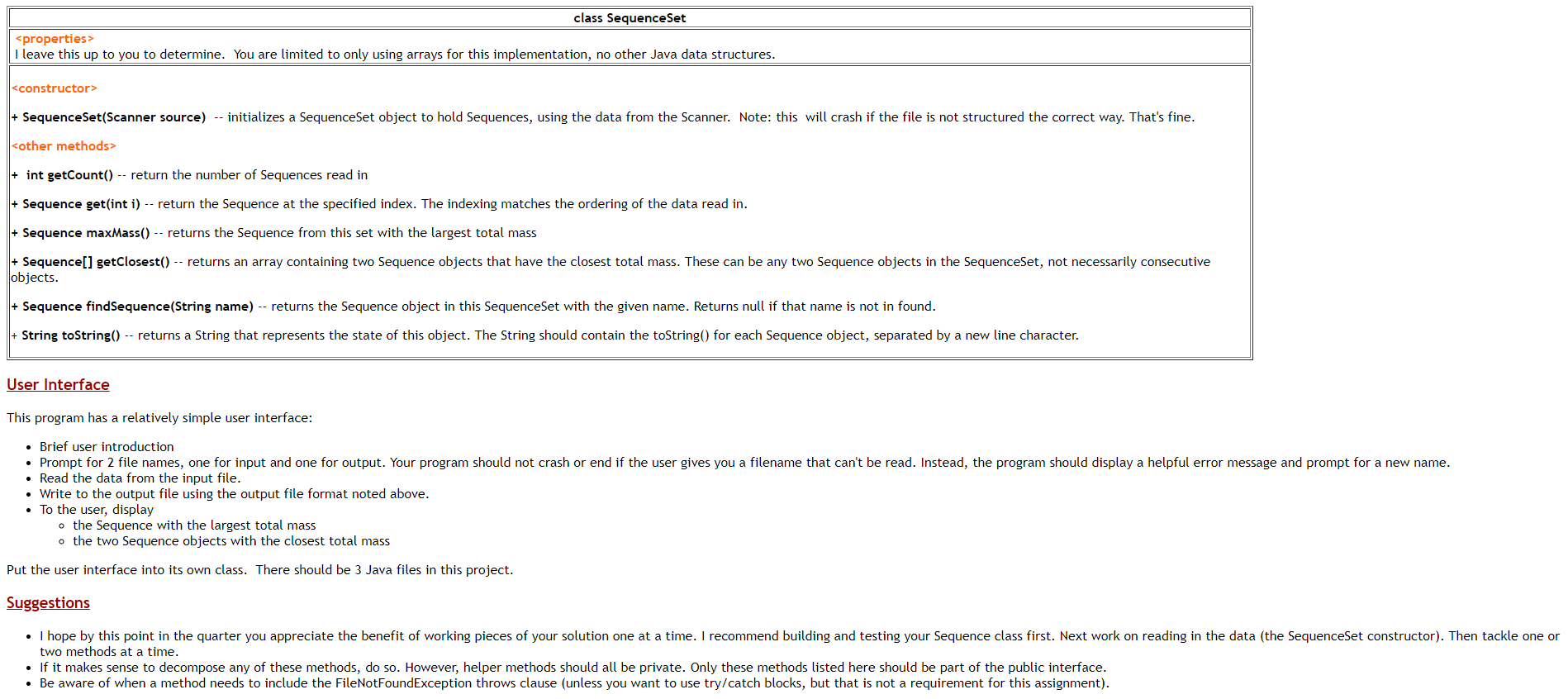
Documentation and Style 1. Make sure to write complete Javadoc comments for each class and each public method. 2. Include sufficient internal, algorithm documentation. 3. Use appropriate style (variable names, indenting, class constants, etc.) throughout the program. Concepts Arrays of objects Plain text file input/output More practice writing supplier code to a specification Background Information About DNA Note: This section explains some information from the field of biology that is related to this project. It is for your information only; you do not need to fully understand it to complete the code. Deoxyribonucleic acid (DNA) is a complex biochemical macromolecule that carries genetic information for cellular life forms and some viruses. DNA is also the mechanism through which genetic information from parents is passed on during reproduction. DNA consists of long chains of chemical compounds called nucleotides. Four nucleotides are present in DNA: Adenine (A), Cytosine (C), Guanine (G), and Thymine (T). DNA has a double-helix structure (see diagram below) containing complementary chains of these four nucleotides connected by hydrogen bonds. Certain regions of the DNA are called genes. Most genes encode instructions for building proteins (they're called "protein-coding" genes). These proteins are responsible for carrying out most of the life processes of the organism. Nucleotides in a gene are organized into codons. Codons are groups of three nucleotides and are written as the first letters of their nucleotides (e.g., TAC or GGA). Each codon uniquely encodes a single amino acid, a building block of proteins. The process of building proteins from DNA has two major phases called transcription and translation, in which a gene is replicated into an intermediate form called mRNA, which is then processed by a structure called a ribosome to build the chain of amino acids encoded by the codons of the gene. Thymine DNA mRNA Protein Adenine Translation Transcription DNA Guanine a Cytosine gooool mRNA D Deoxyribose (sugar) PPhosphate Hydrogen Bond Cell Nucleus oooooooo Protein (amino acid chain) Ribosome Cytoplasm DNA translation. T A The chemical structure of DNA. Codon Codon The sequences of DNA that encode proteins occur between a start codon (which we will assume to be ATG) and a stop codon (which is any of TAA, TAG, or TGA). Not all regions of DNA are genes; large portions that do not lie between a valid start and stop codon are called intergenic DNA and have other (possibly unknown) functions. Computational biologists examine large DNA data files to find patterns and important information, such as which regions are genes. Sometimes they are interested in the percentages of mass accounted for by each of the four nucleotide types. Often high percentages of Cytosine (C) and Guanine (G) are indicators of important genetic data. For more information, visit the Wikipedia page about DNA: http://en.wikipedia.org/wiki/DNA Input Data Files Your program will be reading DNA information from text files. The DNA input file start with an integer, which is the number of nameucleotide sequence pairs in the file. The rest of the lines are treated as pairs. The first line of the pair is the name of the nucleotide sequence, the second line of the pair is the sequence itself. Each character in the nucleotide sequence will be A, C, G, T, or a dash character, -- The nucleotides can be either lower or upper case. The dash characters represent junk or garbage regions of the sequence. Here are two sample files dna1.txt and dna2.txt You program does not have to be responsible for files that do not match this format (in other words, if the end user enters a filename with bad data and the program crashes, that's ok). You can create any text file you want for testing (use a program like Notepad or any other basic text editor). Program Overview Your program will read DNA data from a file. For each named sequence, produce the following A count of the occurrences of the four nucleotides (A, C, G, and T) The mass percentage occupied by each nucleotide type in the sequence. All the codons in the sequence. Note, any junk is skipped. For example, if the sequence is "AC-TGA--TacT" the codons are ACT, GAT, and ACT Whether this sequence is a protein-coding gene. For our purposes, a protein-coding gene is a string that: o begins with the start codon ATG o ends with one of the following stop codons: TAA, TAG, or TGA o is at least 3 codons long (including the start and stop codons) The program behavior is as follows: 1. Display a brief user introduction 2. Prompt for input file name 3. Prompt for output file name 4. Process the input file and write results to the output file 5. Display other results to System.out (see below) The code needs to calculate the total mass as well as the mass percentages for each nucleotide. To compute these values, use the following mass of each nucleotide (grams/mol). Notice that the junk regions do add to the total mass: Adenine (A): 135.128 Cytosine (C): 111.103 Guanine (G): 151.128 Thymine (T): 125.107 Junk .: 100.000 For example, the mass of the sequence ATCGTAA-TC is (135.128 * 3 + 111.103 * 2 + 151.128 * 1 + 125.107 * 3 + 100 * 1) which equals 1254.039. of that mass: 405.384 is from 3 Adenine (32.38) 222.206 is from 2 Cytosine (17.7%) 151.128 is from 1 Guanine (12.13) 325.321 is from 3 Thymine (29.9%) 100 is from 1 dash (83) Output File Format Here is a sample of the file output with the format your program needs to follow. Se Name: Sequence: N Counts: Tt Masss: Codons : Protein?: made up sequence AtcGTAA-TC [3, 2, 1, 3] 1254.0 with [32.3, 17.7, 12.1, 29.9] [ATC, GTA, ATC) NO Seg Name: Sequence: N Counts: Tt Mass$: Codons Protein?: Things to note about the output file: You can use the Arrays.toString() method to print the arrays of data Line 4 lists the total mass value and the mass percentages of each nucleotide. All values are rounded to 1 decimal place. Note that the percentages don't add up to 100%. That's because the percentages are just for A, C, G, and T, where the total mass includes the junk information. There is a blank line between the data for each sequence from the original input file. Code Specification Implement the two classes below, each in its own file. To get full credit, public interfaces must match these descriptions exactly. class Sequence

Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Machine Learning And Knowledge Discovery In Databases European Conference Ecml Pkdd 2014 Nancy France September 15 19 2014 Proceedings Part 2 Lnai 8725
Authors: Toon Calders ,Floriana Esposito ,Eyke Hullermeier ,Rosa Meo
2014th Edition
3662448505, 978-3662448502