

Question
Java Program: Look through the Language Description and build a list of keywords. Add a HashMap to your Lexer class and initialize all the keywords.
Java Program:
Look through the Language Description and build a list of keywords. Add a HashMap to your Lexer class and initialize all the keywords. Change your lexer so that it checks each string before making the WORD token and creates a token of the appropriate type if the work is a key word. When the exact type of a token is known (like "WHILE"), you should NOT fill in the value string, the type is enough. For tokens with no exact type (like "hello"), we still need to fill in the token's string. Finally, rename "WORD" to "IDENTIFIER". Similarly, look through the Language Description for the list of punctuation. A hash map is not necessary or helpful for these - they need to be added to your state machine. Be particularly careful about the multi-character operators like := or >=. These require a little more complexity in your state machine. See the comment state machine example for an idea on how to implement this. Strings and characters will require some additions to your state machine. Create "STRINGLITERAL" and "CHARACTERLITERAL" token types. These cannot cross line boundaries. Note that we aren't going to build in escaping like Java does ( " This is a double quote\" that is inside a string" or '\''). Comments, too, require a bit more complexity in your state machine. When a comment starts, you need to accept and ignore everything until the closing comment character. Assume that comments cannot be nested - {{this is invalid} and will be a syntax error later}. Remember, though, that comments can span lines, unlike numbers or words or symbols; no token should be output for comments. Your lexer should throw an exception if it encounters a character that it doesn't expect outside of a comment, string literal or character literal. Create a new exception type that includes a good error message and the token that failed. Ensure that the ToString method prints nicely. An example of this might be:
ThisIsAnIdentifier 123 ! {
Add "line number" to your Token class. Keep track of the current line number in your lexer and populate each Token's line number; this is straightforward because each call to lex() will be one line greater than the last one. The line number should be added to the exception, too, so that users can fix the exceptions.
Finally, indentation. This is not as bad as it seems. For each line, count from the beginning the number of spaces and tabs until you reach a non-space/tab. Each tab OR four spaces is an indentation level. If the indentation level is greater than the last line (keep track of this in the lexer), output one or more INDENT tokens. If the indentation level is less than the last line, output one or more DEDENT tokens (obviously you will need to make new token types). For example:
1 { indent level 0, output NUMBER 1 }
a { indent level 1, output an INDENT token, then IDENTIIFIER a }
b { indent level 2, output an INDENT token, then IDENTIFIER b }
c { indent level 4, output 2 INDENT tokens, then IDENTIFIER c }
2 { indent level 0; output 4 DEDENT tokens, then NUMBER 2 }
Be careful of the two exceptions:
If there are no non-space/tab characters on the line, don't output an INDENT or DEDENT and don't change the stored indentation level.
If we are in the middle of a multi-line comment, indentation is not considered.
Note that end of file, you must output DEDENTs to get back to level 0.
Requirements:
Your exception must be called "SyntaxErrorException" and be in its own file. Unterminated strings or characters are invalid and should throw this exception, along with any invalid symbols.
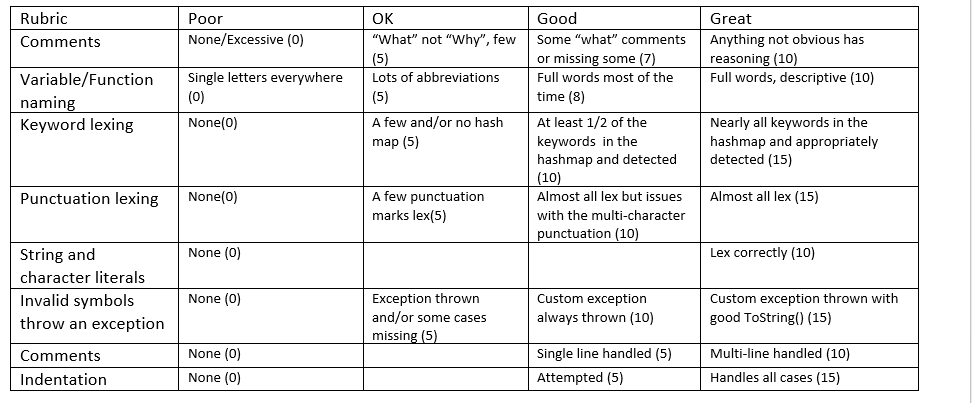
Below is the lexer file with the token and shank files. The shank file is the main method file. There are errors in the lexer file and make sure to fix the errors in the lexer file as well. Make sure to complete the above task required and there must be no error at all. Show the entire written code and attached is rubric as well. Show the output in the terminal:
Lexer.java
package mypack;
import java.util.ArrayList; import java.util.HashMap; import java.util.List;
public class Lexer { private static final int INTEGER_STATE = 1; private static final int DECIMAL_STATE = 2; private static final int IDENTIFIER_STATE = 3; private static final int SYMBOL_STATE = 4; private static final int ERROR_STATE = 5; private static final int STRING_STATE = 6; private static final int CHAR_STATE = 7; private static final int COMMENT_STATE = 8; private static final int UNKNOWN_STATE = 9;
private static final char EOF = (char) -1; private static String input; private static int index; private static char currentChar; private static int lineNumber = 1; private static int indentLevel = 0; private static int lastIndentLevel = 0; private static HashMap
while (currentChar != EOF) { switch (currentState()) { case INTEGER_STATE: integerState(tokens); break; case DECIMAL_STATE: decimalState(tokens); break; case IDENTIFIER_STATE: identifierState(tokens); break; case SYMBOL_STATE: symbolState(tokens); break; case STRING_STATE: stringState(tokens); break; case CHAR_STATE: charState(tokens); break; case COMMENT_STATE: commentState(); break; case ERROR_STATE: case UNKNOWN_STATE: throw new SyntaxErrorException("Invalid character encountered at line " + lineNumber + ": " + currentChar, lineNumber, currentChar); } nextChar(); } return tokens; } private static int currentState() { if (Character.isDigit(currentChar) ) { return INTEGER_STATE; } else if (Character.isLetter(currentChar)) { return IDENTIFIER_STATE; } else if (currentChar == '\"' || currentChar == '\'') { return currentChar == '\"' ? STRING_STATE : CHAR_STATE; } else if (currentChar == '{' || currentChar == '}') { return COMMENT_STATE; } else if (currentChar == ' ' || currentChar == '\t') { return UNKNOWN_STATE; } else if (isSymbol(currentChar)) { return SYMBOL_STATE; } else { return UNKNOWN_STATE; } } private static void integerState(List
Token.java
package mypack;
public class Token { public enum TokenType { WORD, NUMBER, SYMBOL }
public TokenType tokenType; private String value; public Token(TokenType type, String val) { this.tokenType = type; this.value = val; } public TokenType getTokenType() { return this.tokenType; }
public String toString() { return this.tokenType + ": " + this.value; } } Shank.java
package mypack;
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.List;
public class Shank { public static void main(String[] args) { if (args.length != 1) { System.out.println("Error: Exactly one argument is required."); System.exit(0); }
String filename = args[0];
try { List
Lexer lexer = new Lexer();
for (String line : lines) { try { List
for (Token token : tokens) { System.out.println(token); } } catch (Exception e) { System.out.println("Exception: " + e.getMessage()); } } } catch (IOException e) { System.out.println("Error: Could not read file '" + filename + "'."); } } }
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Fundamentals Of Database Management Systems
Authors: Mark L. Gillenson
3rd Edition
978-1119907466