

Question: just answer the given question using the references given Every cycle that does not initiate a new operation in a pipe is a lost opportunity,
just answer the given question using the references given
Every cycle that does not initiate a new operation in a pipe is a lost opportunity, in the sense that your hardware is not living up to its potential.
b. Loop unrolling is one standard compiler technique for finding more parallelism in code, in order to minimize the lost opportunities for performance. Hand-unroll two iterations of the loop in your reordered code from Exercise 3.5.
c. What speedup did you obtain? (For this exercise, just color the N+1 iterations instructions green to distinguish them from the Nth iterations instructions; if you were actually unrolling the loop, you would have to reassign registers to prevent collisions between the iterations.
3.5 -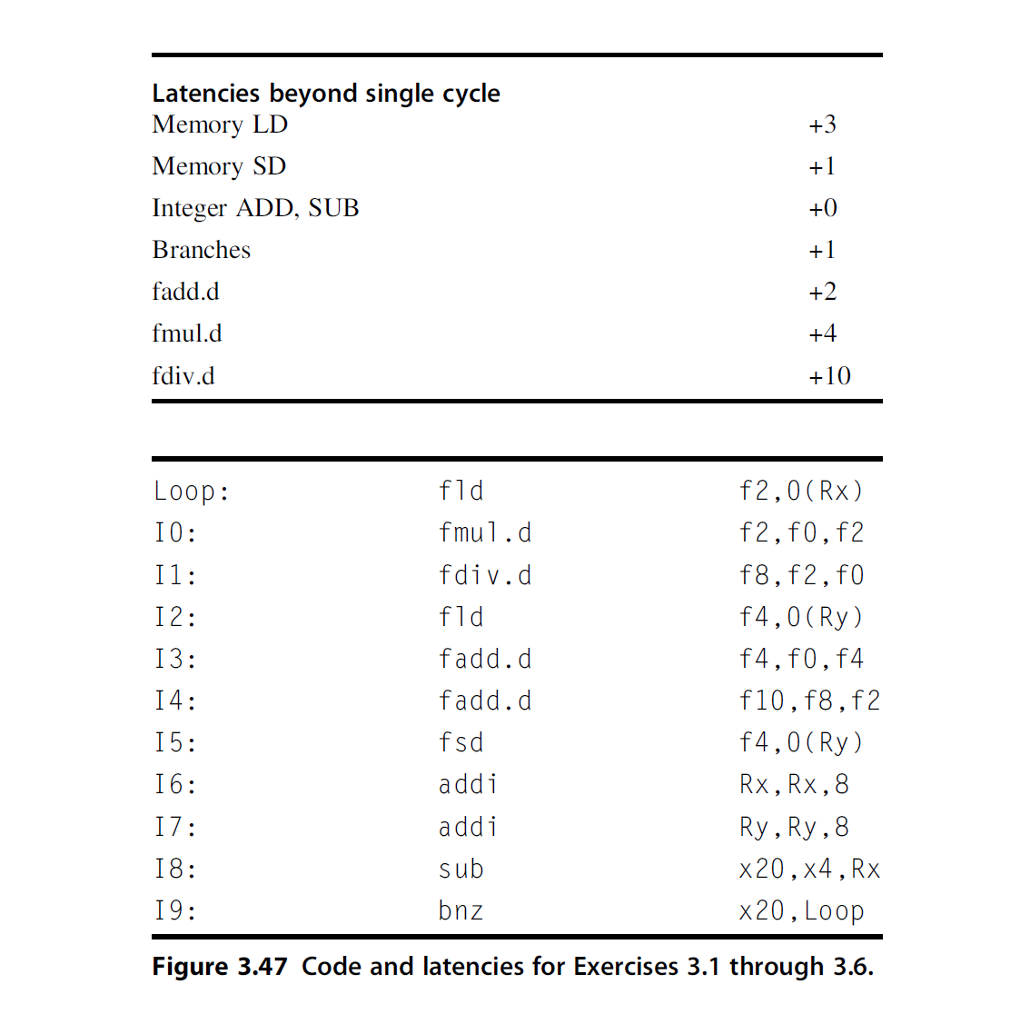 Reorder the instructions to improve performance of the code in Figure 3.47. Assume the two-pipe machine in Exercise 3.3 and that the out-oforder completion issues of Exercise 3.4 have been dealt with successfully. Just worry about observing true data dependences and functional unit latencies for now. How many cycles does your reordered code take?
Reorder the instructions to improve performance of the code in Figure 3.47. Assume the two-pipe machine in Exercise 3.3 and that the out-oforder completion issues of Exercise 3.4 have been dealt with successfully. Just worry about observing true data dependences and functional unit latencies for now. How many cycles does your reordered code take?
3.3 [15] Consider a multiple-issue design. Suppose you have two execution pipelines, each capable of beginning execution of one instruction per cycle, and enough fetch/decode bandwidth in the front end so that it will not stall your execution. Assume results can be immediately forwarded from one execution unit to another, or to itself. Further assume that the only reason an execution pipeline would stall is to observe a true data dependency. Now how many cycles does the loop require? 3.4 [10] In the multiple-issue design of Exercise 3.3, you may have recognized some subtle issues. Even though the two pipelines have the exact same instruction repertoire, they are neither identical nor interchangeable, because there is an implicit ordering between them that must reflect the ordering of the instructions in the original program. If instruction N+1 begins execution in Execution Pipe 1 at the same time that instruction N begins in Pipe 0, and N+1 happens to require a shorter execution latency than N, then N+1 will complete before N (even though program ordering would have implied otherwise). Recite at least two reasons why that could be hazardous and will require special considerations in the microarchitecture. Give an example of two instructions from the code in Figure 3.47 that demonstrate this hazard.
Latencies beyond single cycle Memory LD Memory S Integer ADD, SUB Branche:s fadd.d fmul.d fdiv.d fld fmul.d fdiv.d fld fadd.d fadd.d f2,0 (Rx) f2,f0,f2 f8,f2,fO f4,0 (Ry) f4,f0,f4 f10,f8,f2 f4,0 (Ry) Rx, Rx,8 Ry, Ry,8 x20,x4, Rx x20, Loop oop: IO: I2 13: addi add sub bnz 18: 19: Figure 3.47 Code and latencies for Exercises 3.1 through 3.6. Latencies beyond single cycle Memory LD Memory S Integer ADD, SUB Branche:s fadd.d fmul.d fdiv.d fld fmul.d fdiv.d fld fadd.d fadd.d f2,0 (Rx) f2,f0,f2 f8,f2,fO f4,0 (Ry) f4,f0,f4 f10,f8,f2 f4,0 (Ry) Rx, Rx,8 Ry, Ry,8 x20,x4, Rx x20, Loop oop: IO: I2 13: addi add sub bnz 18: 19: Figure 3.47 Code and latencies for Exercises 3.1 through 3.6
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts