

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
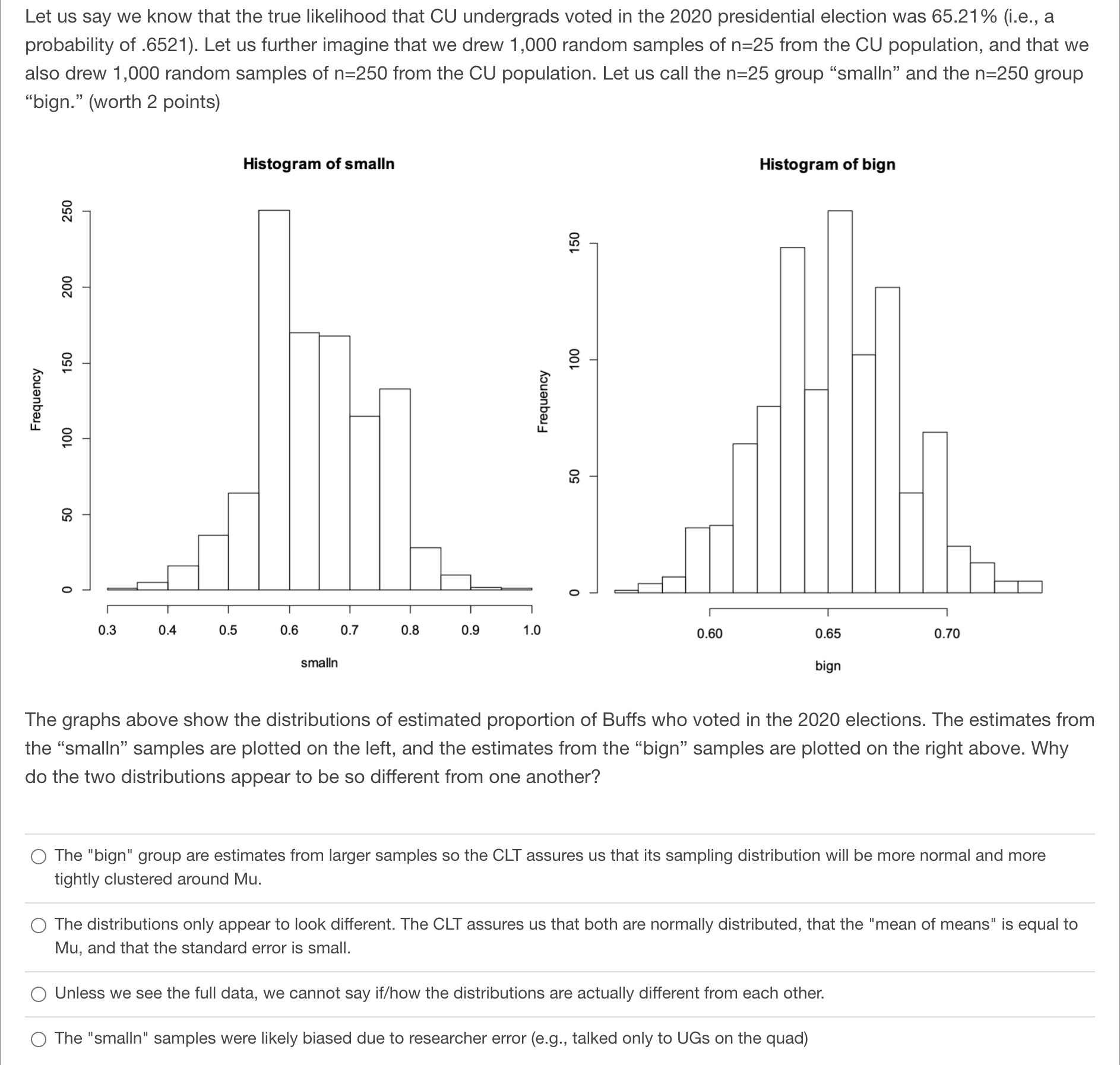
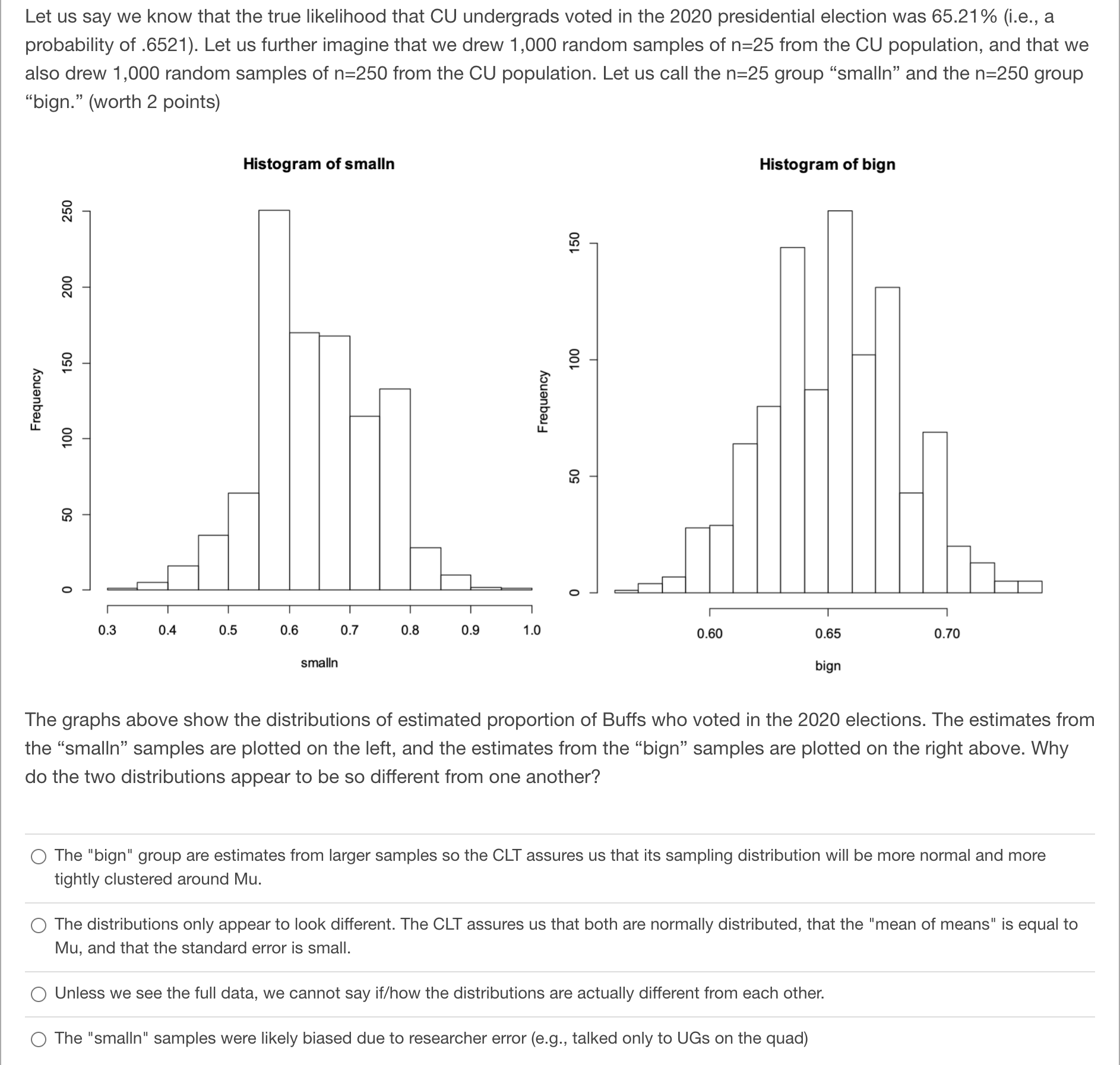
Let us say we know that the true likelihood that CU undergrads voted in the 2020 presidential election was 65.21% (i.e., a probability of .6521).
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
The Art And Craft Of Problem Solving
Authors: Paul Zeitz
3rd Edition
1119094844, 9781119094845