

Question: Lets consider the following 3-state MDP(Markov Decision Process) for a robot trying to walk, the three states being Fallen , Standing and Moving , as
Lets consider the following 3-state MDP(Markov Decision Process) for a robot trying to walk, the three states being Fallen, Standing and Moving, as shown in the following figure.
Use the MDP formulation to code the following problem and find the optimal Values using the value iteration algorithm. And then use policy iteration method to find optimal policy for discount factor =0.1. Try using this method with a different discount factor, for example a much larger discount factor like 0.9 or 0.99, or a much smaller one like 0.01. Does the optimal policy change comment on it?
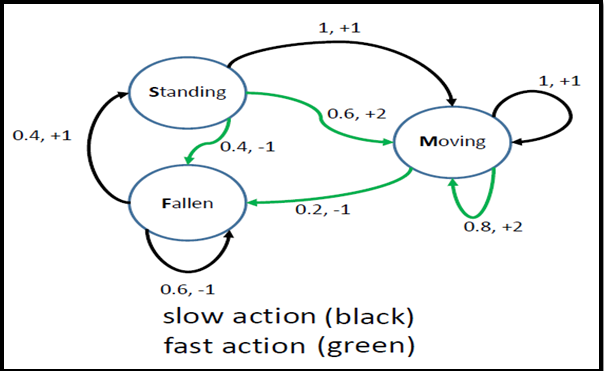
1, +1 1, +1 Standing 0.6, +2 0.4, +1 0.4, -1 Moving Fallen 0.2, -1 0.8, +2 0.6, -1 slow action (black) fast action (green)
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts