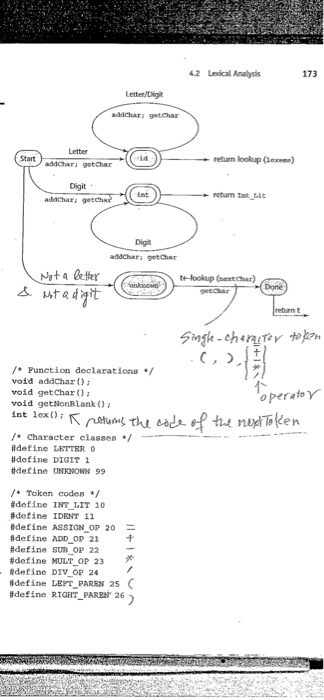
Lexical and Syntax Analysis class named DIGIT for digits and use a single transition on any character in this character class to a state that collects integer literals. Eecause our names can include digits, the transition from the node fol lowing the first character of a name can use a single transition on LETTER or DIGIT to continue collecting the characters of a name. Next, we define some utility subprograms for the common tasks inside the lexical analyzer. First, we need a subprograrn, wich we can name getchar, that has several daties. When called getChar gets the next character of input from the input program and puts it in the global variable next Char, getChar must also determine the character class of the input character and put it in the global variable charclasa. The lexeme being built by the lexical analyzer, which could be implemented as a character string or an array, will be named lexeme. We implement the process of putting the character in nextchar into the string array lexeme in a subprogram named addChar. This subprogram must be explicitly called becaiuse programs incude some characters that need not be put in lexeme, for example the white-space characters between lex- emes. In a more realistic lexical analyzer, comments also would not be placed in lexeme When the lexical analyzer is called, it is convenient if the next character of input is the first character of the next lexeme. Because of this, a function named get NonBlank is used to skip white space every time the analyzer is called nally, a subprogram named 1ookup is needed he token code for the single-character tokens, in our emple these are parenthesesa ritheti by the compiler writer. ic operators. Token codes are numbers arbitrarily assigned to tokens The state diagram in Figure 4. describes the patterns for our tokens. It includes the actions required on each transition of the state dingram The following is a C implementation of a lexical analyzer specified ih the state diagram of Figure 4.1, including a main driver function for testing purposes: /front. a lexical analyzer system for simple arithmetic expressions #include
#include / Global declarations /Variablea/ int charClass char lexeme (2001, (o chavacters char next char int lexten int token int next Token FILE .in fp. topen) Lexical and Syntax Analysis class named DIGIT for digits and use a single transition on any character in this character class to a state that collects integer literals. Eecause our names can include digits, the transition from the node fol lowing the first character of a name can use a single transition on LETTER or DIGIT to continue collecting the characters of a name. Next, we define some utility subprograms for the common tasks inside the lexical analyzer. First, we need a subprograrn, wich we can name getchar, that has several daties. When called getChar gets the next character of input from the input program and puts it in the global variable next Char, getChar must also determine the character class of the input character and put it in the global variable charclasa. The lexeme being built by the lexical analyzer, which could be implemented as a character string or an array, will be named lexeme. We implement the process of putting the character in nextchar into the string array lexeme in a subprogram named addChar. This subprogram must be explicitly called becaiuse programs incude some characters that need not be put in lexeme, for example the white-space characters between lex- emes. In a more realistic lexical analyzer, comments also would not be placed in lexeme When the lexical analyzer is called, it is convenient if the next character of input is the first character of the next lexeme. Because of this, a function named get NonBlank is used to skip white space every time the analyzer is called nally, a subprogram named 1ookup is needed he token code for the single-character tokens, in our emple these are parenthesesa ritheti by the compiler writer. ic operators. Token codes are numbers arbitrarily assigned to tokens The state diagram in Figure 4. describes the patterns for our tokens. It includes the actions required on each transition of the state dingram The following is a C implementation of a lexical analyzer specified ih the state diagram of Figure 4.1, including a main driver function for testing purposes: /front. a lexical analyzer system for simple arithmetic expressions #include #include / Global declarations /Variablea/ int charClass char lexeme (2001, (o chavacters char next char int lexten int token int next Token FILE .in fp. topen)