

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Matrix Multiplication using CUDA and implementation on Nvidia GPU 1) Declare matrix A of width 480 and height 800. 2) Declare matrix B of width

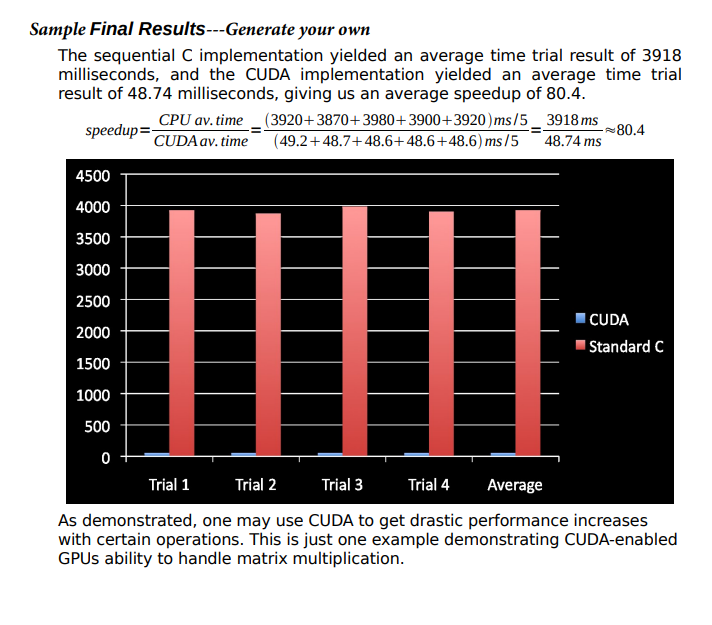

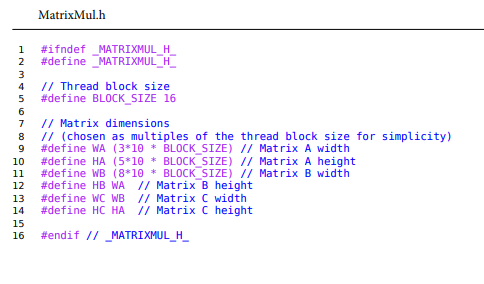


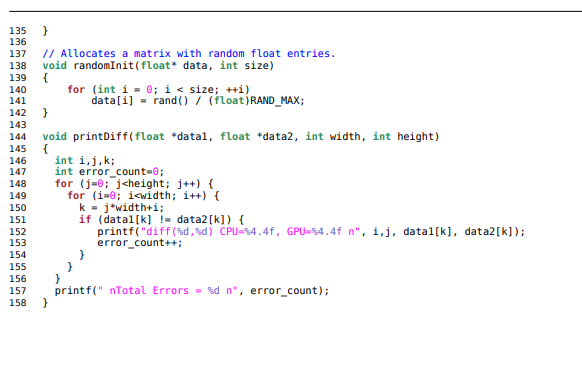
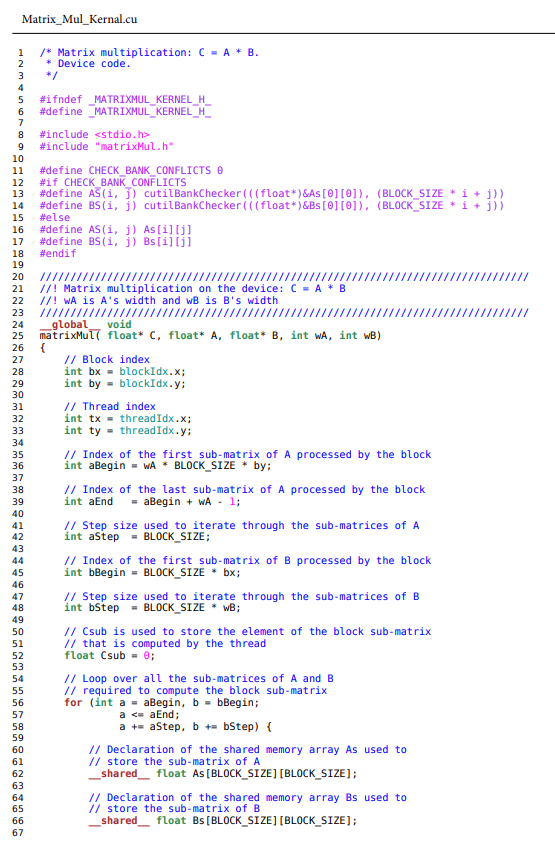

Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advanced Oracle Solaris 11 System Administration
Authors: Bill Calkins
1st Edition
0133007170, 9780133007176