

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
My main issue is understanding what this assignment is asking me to do and then how to start the project. 5 Interfacing with Blackbox #include



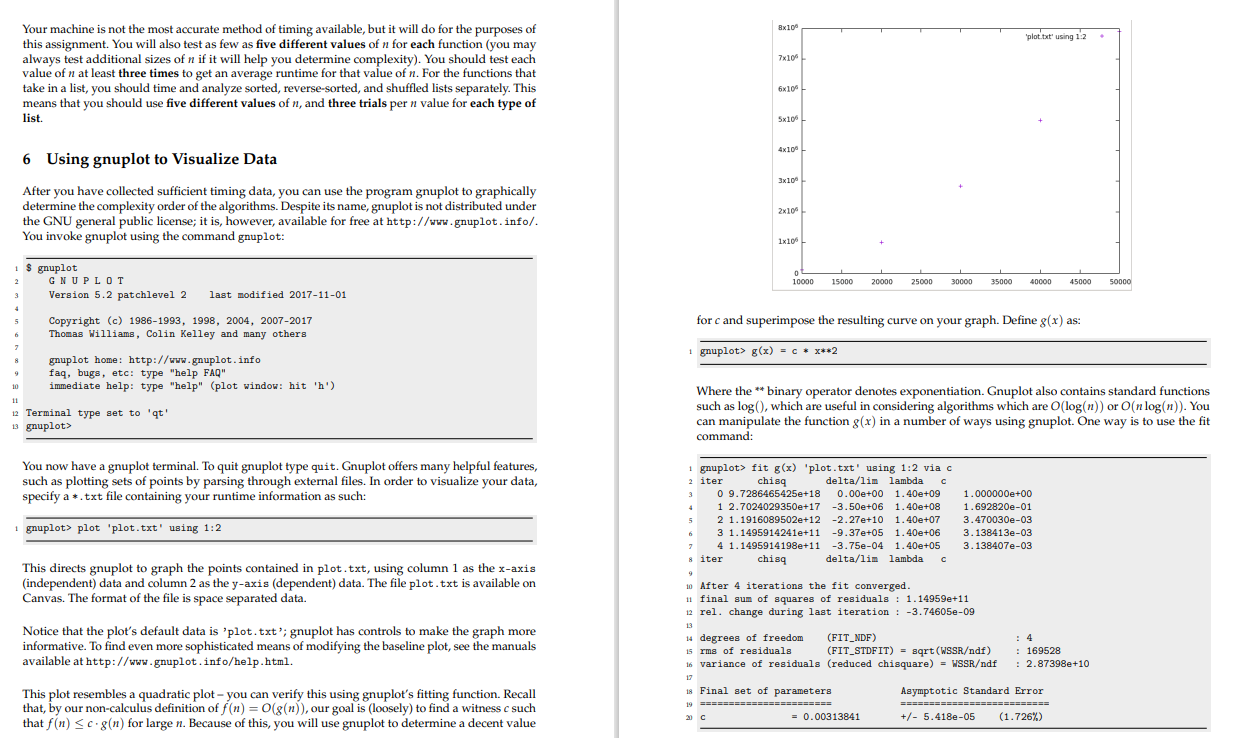
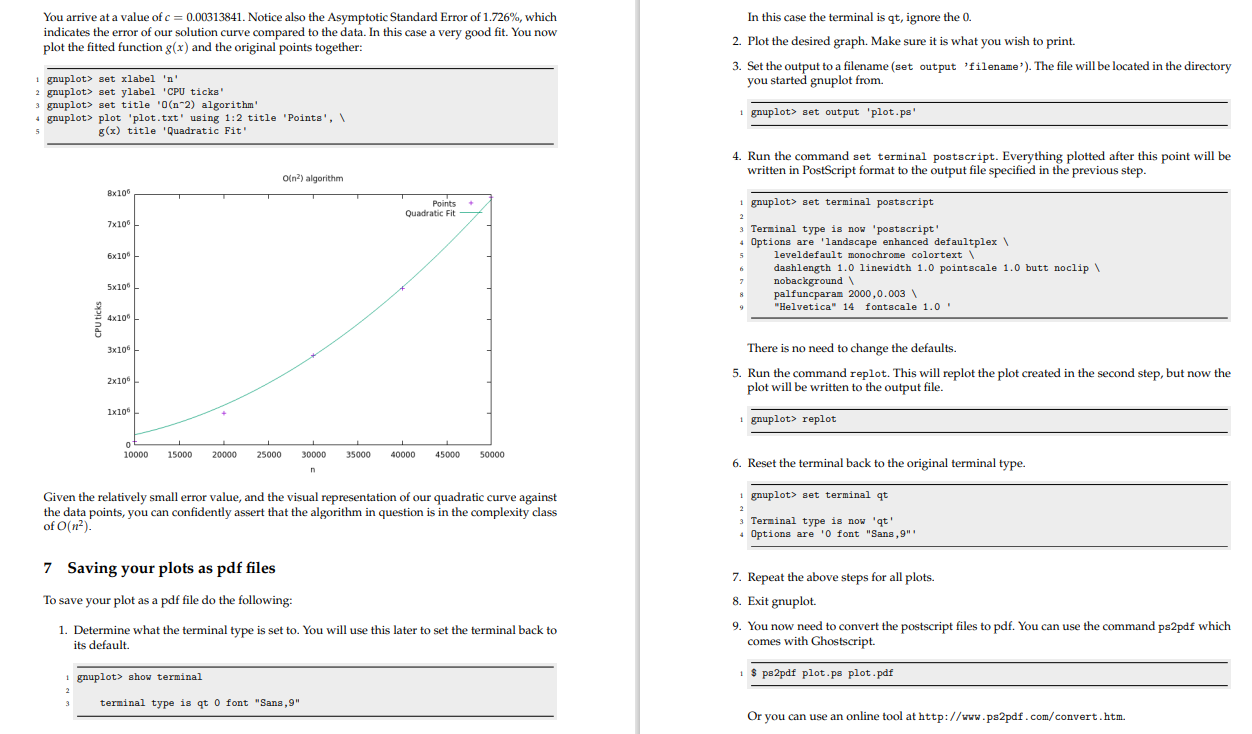
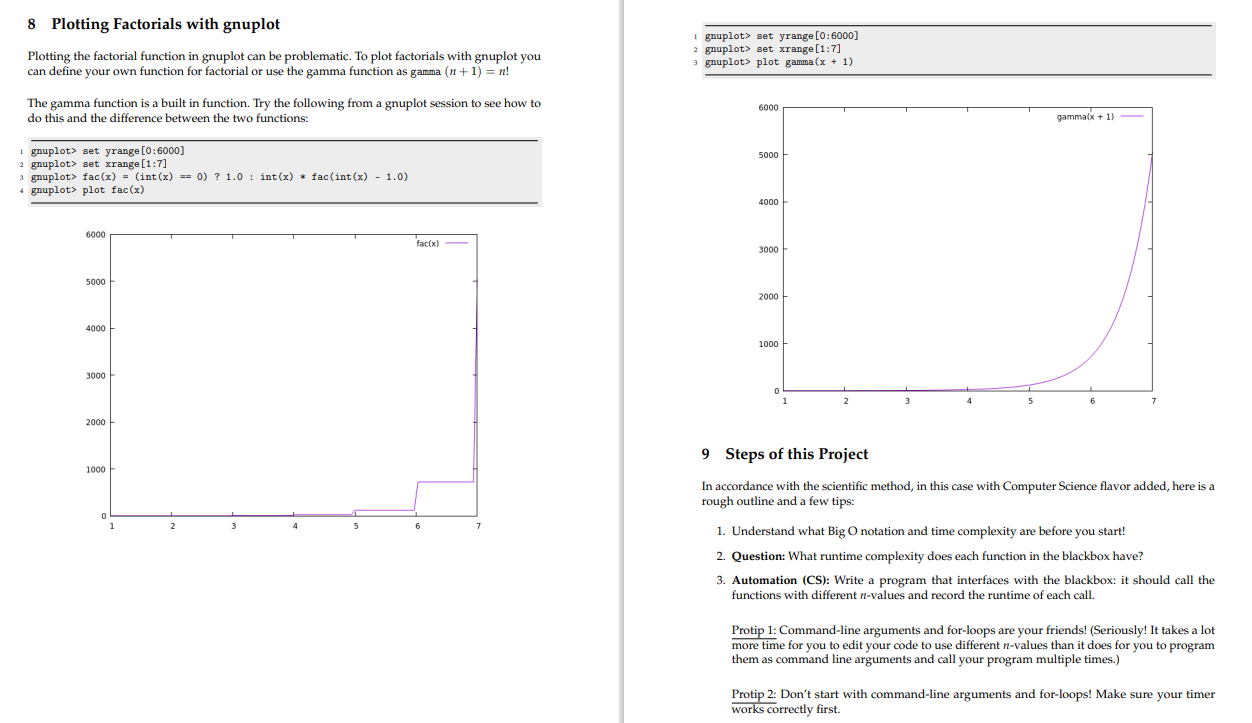
 My main issue is understanding what this assignment is asking me to do and then how to start the project.
My main issue is understanding what this assignment is asking me to do and then how to start the project.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Select Healthcare Classification Systems And Databases
Authors: Katherine S. Rowell, Ann Cutrell
1st Edition
0615909760, 978-0615909769