

Question
My project evaluates around the use of implementing a simple polynomial-parse tree evaluator. This is executed through the following files (please read and/or copy the
My project evaluates around the use of implementing a simple polynomial-parse tree evaluator. This is executed through the following files (please read and/or copy the following code):
parser.cc (this file includes #include "parser.h" & #include "lexer.h")
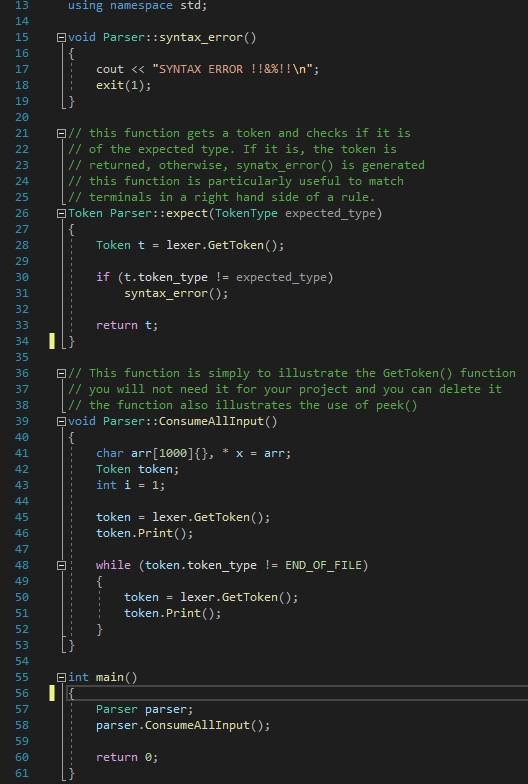
parser.h
#ifndef __PARSER_H__ #define __PARSER_H__
#include #include
using namespace std;
#include "lexer.h"
class Parser { public: void ConsumeAllInput();
private: LexicalAnalyzer lexer; void syntax_error(); Token expect(TokenType expected_type); //Token myParser(); };
string reserved[] = { "END_OF_FILE", "POLY", "EVAL", "INPUT", "EQUAL", "ID", "POWER", "NUM", "PLUS", "SEMICOLON", "ERROR", "MULT" };
#define KEYWORDS_COUNT 3 string keyword[] = { "POLY", "EVAL", "INPUT" };
void Token::Print() { cout lexeme token_type] line_no
// The constructor function will get all token in the input and stores them in an // internal vector. This faciliates the implementation of peek() LexicalAnalyzer::LexicalAnalyzer() { this->line_no = 1; tmp.lexeme = ""; tmp.line_no = 1; tmp.token_type = ERROR;
Token token = GetTokenMain(); index = 0;
while (token.token_type != END_OF_FILE) { tokenList.push_back(token); // push token into internal list token = GetTokenMain(); // and get next token from standatd input } // pushes END_OF_FILE is not pushed on the token list }
bool LexicalAnalyzer::SkipSpace() { char c; bool space_encountered = false;
input.GetChar(c); line_no += (c == ' ');
while (!input.EndOfInput() && isspace(c)) { space_encountered = true; input.GetChar(c); line_no += (c == ' '); }
if (!input.EndOfInput()) { input.UngetChar(c); } return space_encountered; }
bool LexicalAnalyzer::IsKeyword(string s) { for (int i = 0; i
TokenType LexicalAnalyzer::FindKeywordIndex(string s) { for (int i = 0; i
Token LexicalAnalyzer::ScanNumber() { char c;
input.GetChar(c); if (isdigit(c)) { if (c == '0') { tmp.lexeme = "0"; } else { tmp.lexeme = ""; while (!input.EndOfInput() && isdigit(c)) { tmp.lexeme += c; input.GetChar(c); } if (!input.EndOfInput()) { input.UngetChar(c); } } tmp.token_type = NUM; tmp.line_no = line_no; return tmp; } else { if (!input.EndOfInput()) { input.UngetChar(c); } tmp.lexeme = ""; tmp.token_type = ERROR; tmp.line_no = line_no; return tmp; } }
Token LexicalAnalyzer::ScanIdOrKeyword() { char c; input.GetChar(c);
if (isalpha(c)) { tmp.lexeme = ""; while (!input.EndOfInput() && isalnum(c)) { tmp.lexeme += c; input.GetChar(c); } if (!input.EndOfInput()) { input.UngetChar(c); } tmp.line_no = line_no; if (IsKeyword(tmp.lexeme)) tmp.token_type = FindKeywordIndex(tmp.lexeme); else tmp.token_type = ID; } else { if (!input.EndOfInput()) { input.UngetChar(c); } tmp.lexeme = ""; tmp.token_type = ERROR; } return tmp; }
// GetToken() accesses tokens from the tokenList that is populated when a // lexer object is instantiated Token LexicalAnalyzer::GetToken() { Token token; if ((size_t)index == tokenList.size()) { // return end of file if token.lexeme = ""; // index is too large token.line_no = line_no; token.token_type = END_OF_FILE; } else{ token = tokenList[index]; index = index + 1; } return token; }
// peek requires that the argument "howFar" be positive. Token LexicalAnalyzer::peek(int howFar) { if (howFar
int peekIndex = index + howFar - 1; if ((size_t)peekIndex > (tokenList.size()-1)) { // if peeking too far Token token; // return END_OF_FILE token.lexeme = ""; token.line_no = line_no; token.token_type = END_OF_FILE; return token; } else return tokenList[peekIndex]; }
Token LexicalAnalyzer::GetTokenMain() { char c;
SkipSpace(); tmp.lexeme = ""; tmp.line_no = line_no; tmp.token_type = END_OF_FILE;
if (!input.EndOfInput()) input.GetChar(c); else return tmp;
switch (c) { case ';': tmp.token_type = SEMICOLON; return tmp; case '^': tmp.token_type = POWER; return tmp; // case '-': tmp.token_type = MINUS; return tmp; case '+': tmp.token_type = PLUS; return tmp; case '=': tmp.token_type = EQUAL; return tmp; // case '(': tmp.token_type = LPAREN; return tmp; // case ')': tmp.token_type = RPAREN; return tmp; // case ',': tmp.token_type = COMMA; return tmp; case '*': tmp.token_type = MULT; return tmp; default: if (isdigit(c)) { input.UngetChar(c); return ScanNumber(); } else if (isalpha(c)) { input.UngetChar(c); return ScanIdOrKeyword(); } else if (input.EndOfInput()) tmp.token_type = END_OF_FILE; else tmp.token_type = ERROR;
return tmp; } }
bool InputBuffer::EndOfInput() { if (!input_buffer.empty()) return false; else return cin.eof(); }
char InputBuffer::UngetChar(char c) { if (c != EOF) input_buffer.push_back(c);; return c; }
void InputBuffer::GetChar(char& c) { if (!input_buffer.empty()) { c = input_buffer.back(); input_buffer.pop_back(); } else { cin.get(c); } }
string InputBuffer::UngetString(string s) { for (size_t i = 0; i
#endif
lexer.h
#ifndef __LEXER__H__ #define __LEXER__H__
#include #include
#include "inputbuf.h"
// ------- token types -------------------
typedef enum { END_OF_FILE = 0, POLY, EVAL, INPUT, EQUAL, ID, POWER, NUM, PLUS, SEMICOLON, ERROR, MULT } TokenType;
class Token { public: void Print();
std::string lexeme; TokenType token_type; int line_no; };
class LexicalAnalyzer { public: Token GetToken(); Token peek(int); LexicalAnalyzer();
private: std::vector tokenList; Token GetTokenMain(); int line_no; int index; Token tmp; InputBuffer input;
bool SkipSpace(); bool IsKeyword(std::string); TokenType FindKeywordIndex(std::string); Token ScanNumber(); Token ScanIdOrKeyword(); };
#endif //__LEXER__H__
inputbuf.h
#ifndef __INPUT_BUFFER__H__ #define __INPUT_BUFFER__H__
#include #include
class InputBuffer { public: void GetChar(char&); char UngetChar(char); std::string UngetString(std::string); bool EndOfInput();
private: std::vector input_buffer; };
#endif //__INPUT_BUFFER__H__
Assume you have test cases that includes the following text files such as:
test_01.txt:
POLY X * Y; EVAL INPUT X = 3; INPUT Y = 2; EVAL INPUT X = 5; INPUT Y = 7; INPUT M = 12;
Assuming you use a Git Bash terminal instead of powershell in visual studio code
And execute the following command: ~$ g++ -std=c++17 parser.cc parser.h -o prog.out
Then ~$ ./prog.out myoutput_01.txt
**As of now, if we execute the following command the, output is not correct**
**Instead, what we want is to achieve to display the following outputs**
We should get our myoutput_01.txt file to read:
6
35
How would you convert the following output to match the expected output? (Modify the files to your content)
using namespace std; void Parser::syntax_error() { coutStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Machine Learning And Knowledge Discovery In Databases European Conference Ecml Pkdd 2017 Skopje Macedonia September 18 22 2017 Proceedings Part 3 Lnai 10536
Authors: Yasemin Altun ,Kamalika Das ,Taneli Mielikainen ,Donato Malerba ,Jerzy Stefanowski ,Jesse Read ,Marinka Zitnik ,Michelangelo Ceci ,Saso Dzeroski
1st Edition
3319712721, 978-3319712727