

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Need answers in Python. Q1. Define a function to analyze the frequency of words in a string Define a function named tokenize which does the
Need answers in Python.
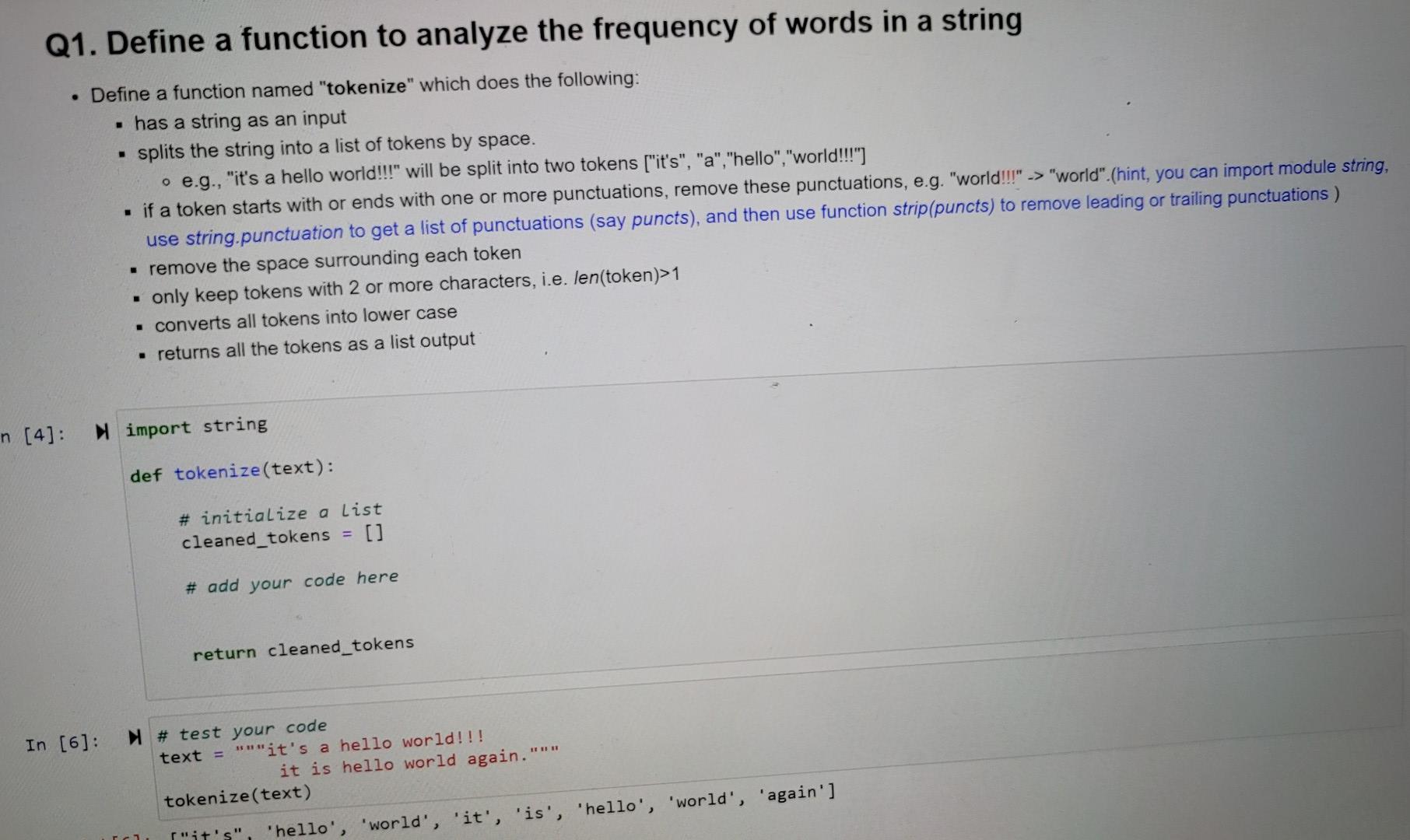
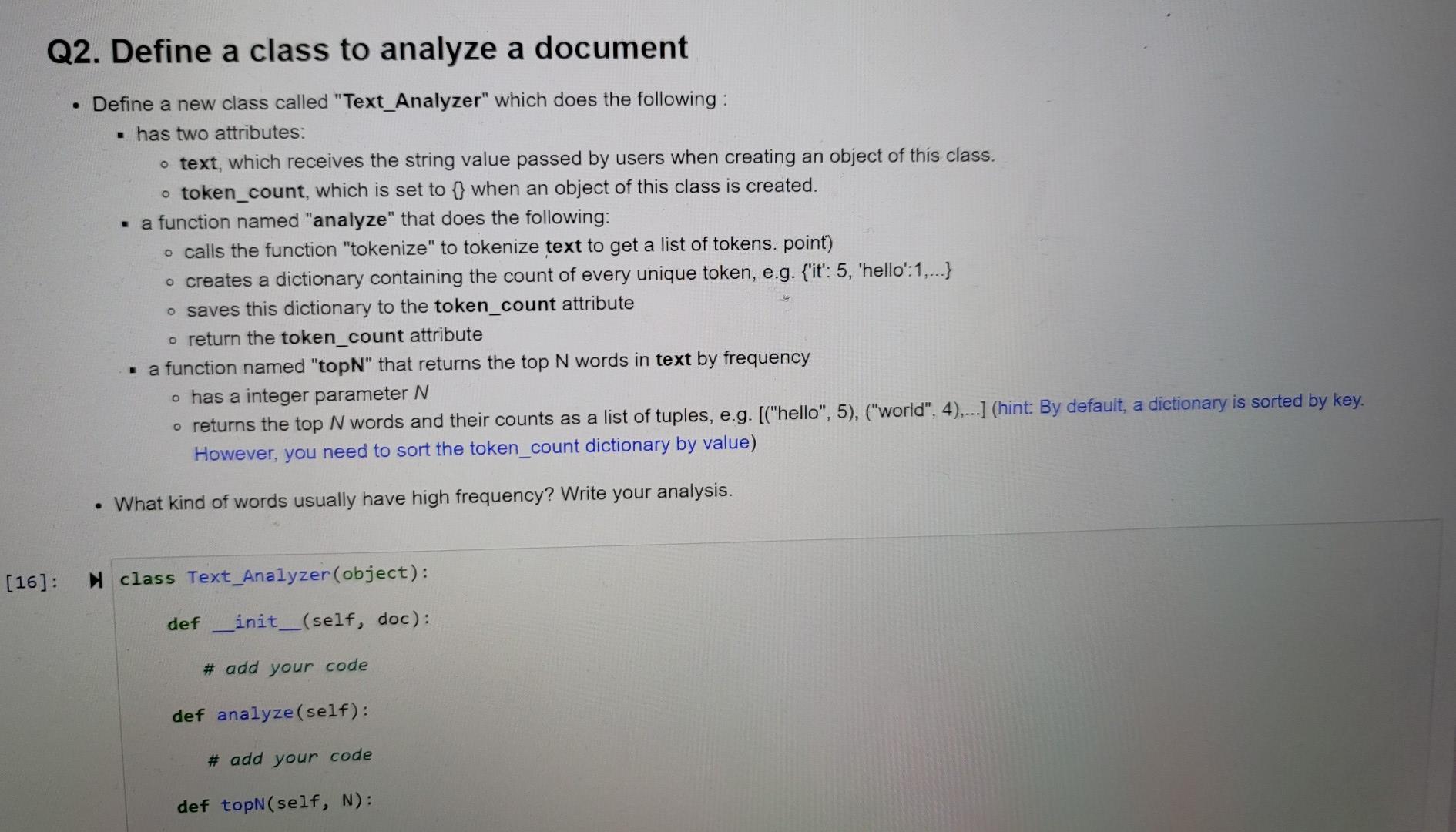
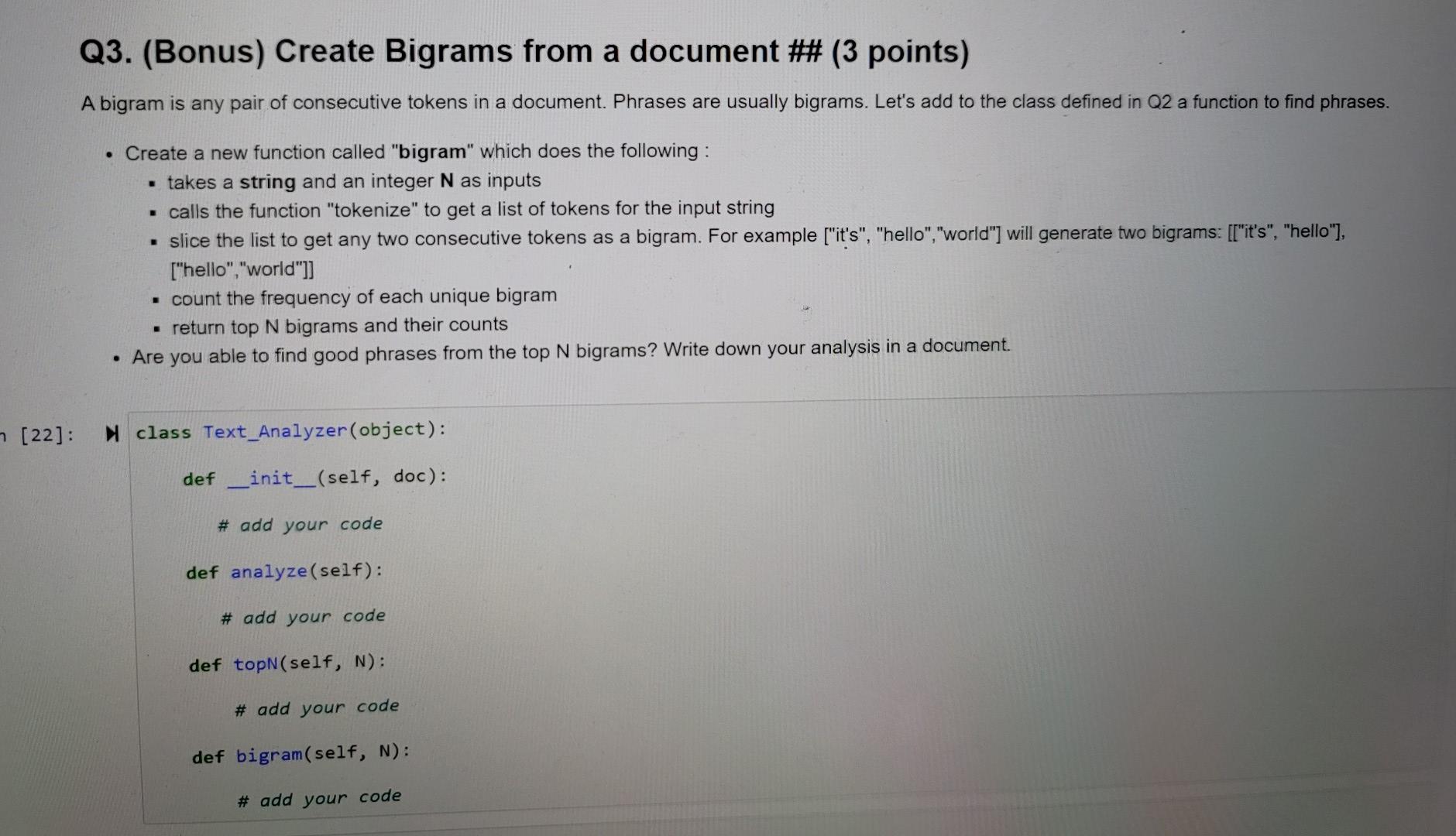
Q1. Define a function to analyze the frequency of words in a string Define a function named "tokenize" which does the following: has a string as an input splits the string into a list of tokens by space. o e.g., "it's a hello world!!!" will be split into two tokens ["it's", "a","hello","world!!!") if a token starts with or ends with one or more punctuations, remove these punctuations, e.g. "world!!!" -> "world".(hint, you can import module string, use string.punctuation to get a list of punctuations (say puncts), and then use function strip(puncts) to remove leading or trailing punctuations ) remove the space surrounding each token only keep tokens with 2 or more characters, i.e. len(token)>1 converts all tokens into lower case returns all the tokens as a list output n [4]: Nimport string def tokenize(text): # initialize a list cleaned_tokens = [] # add your code here return cleaned_tokens In [6]: IT I # test your code text = ""it's a hello world!!! it is hello world again. tokenize(text) it's" 'hello', 'world', 'it', 'is', 'hello', 'world', 'again'] Q2. Define a class to analyze a document Define a new class called "Text_Analyzer" which does the following: has two attributes: o text, which receives the string value passed by users when creating an object of this class. o token_count, which is set to f} when an object of this class is created. a function named "analyze" that does the following: o calls the function "tokenize" to tokenize text to get a list of tokens. point) o creates a dictionary containing the count of every unique token, e.g. {'it': 5, 'hello': 1,...} o saves this dictionary to the token_count attribute o return the token_count attribute . a function named "topN" that returns the top N words in text by frequency o has a integer parameter N o returns the top N words and their counts as a list of tuples, e.g. [("hello", 5), ("world", 4),..] (hint: By default, a dictionary is sorted by key. However, you need to sort the token_count dictionary by value) What kind of words usually have high frequency? Write your analysis. [16]: N class Text_Analyzer(object): def __init_(self, doc): # add your code def analyze (self): # add your code def topN(self, N): Q3. (Bonus) Create Bigrams from a document ## (3 points) A bigram is any pair of consecutive tokens in a document. Phrases are usually bigrams. Let's add to the class defined in Q2 a function to find phrases. Create a new function called "bigram" which does the following: takes a string and an integer N as inputs calls the function "tokenize" to get a list of tokens for the input string slice the list to get any two consecutive tokens as a bigram. For example ["it's", "hello","world"] will generate two bigrams: [["it's", "hello"], ["hello", "world"]] count the frequency of each unique bigram return top N bigrams and their counts Are you able to find good phrases from the top N bigrams? Write down your analysis in a document. - [22]: class Text_Analyzer(object): def __init__(self, doc): # add your code def analyze (self): # add your code def topN(self, N): # add your code def bigram(self, N): # add your codeStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Making Databases Work The Pragmatic Wisdom Of Michael Stonebraker
Authors: Michael L. Brodie
1st Edition
1947487167, 978-1947487161