

Question
Objectives: 1. Understand what a Pipeline is and what it is used for 2. Implement a Pipeline ' python' As briefly mentioned in the Feature
Objectives:
1. Understand what a Pipeline is and what it is used for
2. Implement a Pipeline
"'
 python'"
python'"
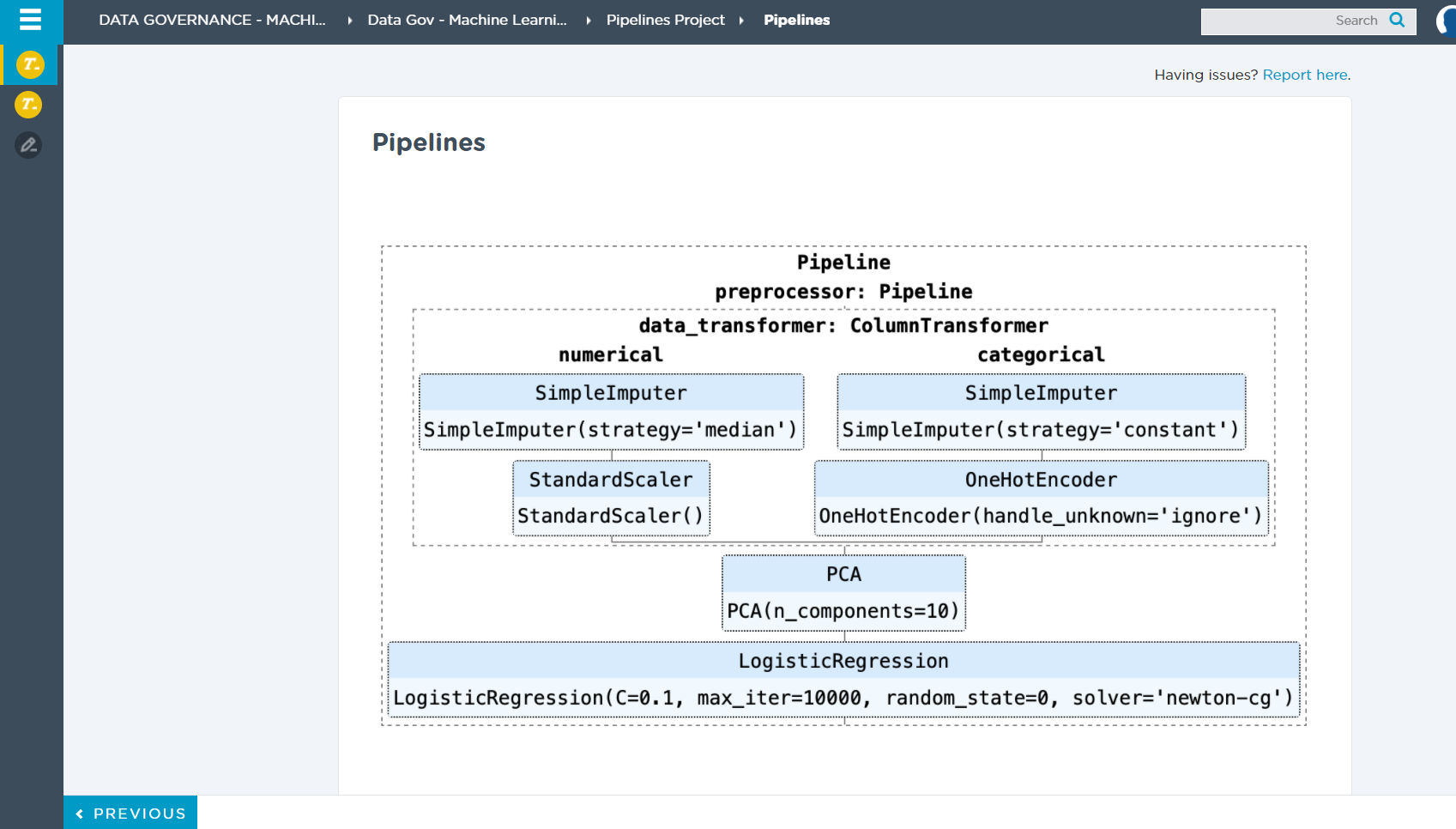
As briefly mentioned in the Feature Engineering module, we can use Pipelines in Python to aggregate different transforms for data and modeling. By aggregating different transforms in Pipelines we can write cleaner code and also streamline the machine learning workflow.
Imagine we want to find the best Scaler, Imputer, and other different transformers which we have discussed in feature engineering. How would we do that? Well, we could try each one of these transformers one by one and compare scores. Or, we could use a Pipeline with GridSearchCV as tools to do this process for us.
"The purpose of the pipeline is to assemble several steps that can be cross-validated together while setting different parameters. For this, it enables setting parameters of the various steps using their names and the parameter name separated by a __, as in the example below. A steps estimator may be replaced entirely by setting the parameter with its name to another estimator, or a transformer removed by setting it to passthrough or None.
...
>>> from sklearn.svm import SVC >>> from sklearn.preprocessing import StandardScaler >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification(random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... random_state=0) >>> pipe = Pipeline([('scaler', StandardScaler()), ('svc', SVC())]) >>> # The pipeline can be used as any other estimator >>> # and avoids leaking the test set into the train set >>> pipe.fit(X_train, y_train) Pipeline(steps=[('scaler', StandardScaler()), ('svc', SVC())]) >>> pipe.score(X_test, y_test) 0.88 copy
"
- sklearn.pipeline.Pipeline
For more examples please watch the following video and be sure to do the readings.
DATA GOVERNANCE - MACHI... Data Gov - Machine Learni... Pipelines Project Pipelines Search Q r Having issues? Report here. 1 Pipelines Pipeline preprocessor: Pipeline data_transformer: Column Transformer numerical categorical SimpleImputer SimpleImputer SimpleImputer(strategy='median') SimpleImputer(strategy='constant') StandardScaler StandardScaler() OneHotEncoder OneHotEncoder(handle_unknown='ignore') PCA PCA(n_components=10) LogisticRegression LogisticRegression(C=0.1, max_iter=10000, random_state=0, solver='newton-cg') >> from sklearn.svm import SVC >>> from sklearn.preprocessing import Standardscaler >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification (random_state=0) >>> X_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) >>> pipe = Pipeline([('scaler', Standardscaler(), ('svc', SVCO))) >>> # The pipeline can be used as any other estimator >> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification (random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=0) >>>> pipe = Pipeline([('scaler', Standardscaler(), ('svc', SVCO)]) >>> # The pipeline can be used as any other estimator >>> # and avoids leaking the test set into the train set >>> pipe.fit(X_train, y_train) Pipeline(steps=[('scaler', Standardscaler()), ('suc', SVCO)]) >>> pipe. score (X_test, y_test) 0.88 - sklearn.pipeline.Pipeline For more examples please watch the following video and be sure to do the readings. Creating Pipelines Using Sklearn- Machine Learning Tutorial: (11 minutes) Creating Pipelines Using Sklearn- Machine Learning Tutorial Watch later Share Creating Pipelines Using >> from sklearn.svm import SVC >>> from sklearn.preprocessing import Standardscaler >>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification (random_state=0) >>> X_train, x_test, y_train, y_test = train_test_split(x, y, random_state=0) >>> pipe = Pipeline([('scaler', Standardscaler(), ('svc', SVCO))) >>> # The pipeline can be used as any other estimator >> from sklearn.model_selection import train_test_split >>> from sklearn.pipeline import Pipeline >>> X, y = make_classification (random_state=0) >>> X_train, X_test, y_train, y_test = train_test_split(x, y, random_state=0) >>>> pipe = Pipeline([('scaler', Standardscaler(), ('svc', SVCO)]) >>> # The pipeline can be used as any other estimator >>> # and avoids leaking the test set into the train set >>> pipe.fit(X_train, y_train) Pipeline(steps=[('scaler', Standardscaler()), ('suc', SVCO)]) >>> pipe. score (X_test, y_test) 0.88 - sklearn.pipeline.Pipeline For more examples please watch the following video and be sure to do the readings. Creating Pipelines Using Sklearn- Machine Learning Tutorial: (11 minutes) Creating Pipelines Using Sklearn- Machine Learning Tutorial Watch later Share Creating Pipelines UsingStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Systems For Advanced Applications 18th International Conference Dasfaa 2013 Wuhan China April 22 25 2013 Proceedings Part 2 Lncs 7826
Authors: Weiyi Meng ,Ling Feng ,Stephane Bressan ,Werner Winiwarter ,Wei Song
2013th Edition
3642374492, 978-3642374494