OCmal programing
For this assignment, you will be enhancing ogrep to correctly parse and match bracket characters and the star operation, as follows:
1. tokenize and read_bracket
tokenize is responsible for converting a string into a list of token values for parsing. The implementation given with the assignment doesn't give * or brackets [] any special meaning. To change this, first add two new constructors to the token declaration:
- ST will represent a * token
- BR of string will include the string of characters found inside a pair of brackets []. (So eventually the result of scanning, say "[abc]" will be the value BR "abc")
Once you've added these variants, we'll need to update tokenize to correctly handle them. * is a simple case and can be handled similarly to .. (Once modified, the result of calling tokenize ".*" 0 should be [DOT; ST].)
Handling bracket expressions is more like escapes: add a second mutually recursive declaration to the definition of tokenize and read_escape that defines the function read_bracket : string -> int -> token list like read_escape, read_bracket should expect to be called with the first index of the string st after an open bracket. It should scan the rest of the string until a closing bracket ] is found, then return a BR value with the contents between the brackets, consed onto the result of tokenizing the rest of the string. (So calling read_bracket "[abc]d" 1 should result in [BR "abc"; Ch 'd']). A few things to keep in mind:
- A bracket expression can include the closing bracket ] by putting it in the first position after the [ character, so read_bracket "[]]" 1 should evaluate to [BR "]"]
- If no closing bracket is found, read_bracket should call failwith "brackets unbalanced"
- Some functions from the String library should prove useful: String.sub and String.index_from_opt.
Don't forget to modify tokenize to call read_bracket when encountering a [ character, so that (tokenize "1701[abcd]" 0) evaluates to [Ch '1'; Ch '7'; Ch '0'; Ch '1'; BR "abcd"].
2. parse_base_case and parse_bracket
Now that tokenize properly scans bracket and * tokens, we'll need to update the regular expression parsing functions. First, we'll need to add a constructor, Bracket, to the regexp type. We'll leave it up to you to determine the form of the data a Bracket constructor should hold. Keep in mind, though, that bracket expressions can contain a list of single characters and ranges mixed in any order, so for example [ab-ef0-9] is a valid bracket expression, as is [A-Za-z] and [a-zc-d]; and that a bracket expression that starts with a caret ^ means "any character that does not match the following list."
Add a function, parse_bracket : string -> regexp that reads the string from a BR and produces a Bracket value. parse_bracket should handle the following cases:
- Checking for the initial ^ that inverts a bracket expression
- If a bracket string has an inverted range, or a double - (e.g. z-a or z--) then parse_bracket should call failwith "invalid range"
- A bracket string may end with -, in which case - is one of the characters that can match.
Once you've defined parse_bracket, modify the parse_base_case function to call parse_bracket if the first token in its argument is a BR.
3. Star and parse_starred_base
Next, to support the star (*) operator, you'll need to add another constructor to the regexp type, Star of regexp. Once you've done that, you'll need to update the parser functions to correctly parse expressions containing a *. Add a function parse_starred_base to the mutually recursive group of parser functions (and parse_starred_base token_list = ). You'll need to replace calls to parse_base_case with calls to parse_starred_base in the other parser functions, and parse_starred_base will make a call to parse_base_case. If parse_starred_base finds a ST token immediately following a base case, it should wrap the base case regexp in a Star and otherwise just return the results of parse_base_case. Once you've finished with this step, it should be the case that parse_starred_base [DOT; ST] evaluates to (Star Wi
ld, []), parse_starred_base [Ch 'a'; Ch 'b'; Ch 'c'] evaluates to (Char 'a', [Ch 'b'; Ch 'c']), and parse_regex [Ch 'a'; ST; Ch 'b'] evaluates to (Concat (Star (Char 'a'), Char 'b'), []).
4. bracket_match
In preparation for the final step, add the function bracket_match : regexp -> char -> bool which takes as input a Bracket value and a character c and checks whether c belongs to the range of characters the bracket expression represents. Thus bracket_match (parse_bracket "a-f0-9") 'c' should evaluate to true, and bracket_match (parse_bracket "^0-9") '0' should evaluate to false. If bracket_match is called with a variant of regexp other than Bracket, it should call invalid_arg "bracket_match".
5. re_match
Finally, we need to modify re_match to handle matching against Star and Bracket regexp values. Add two cases to the match statement that handle the Bracket variant underneath the Char cases in the provided implementation. These cases will look quite similar to the Char cases but involve calling bracket_match instead of a simple equality check. Once this is done, you should find that, for instance regex_match (Concat (parse_bracket "0-9", parse_bracket "a-z")) "0a" evaluates to true.
Add another case to the match statement in re_match to handle Star r. This is the trickiest case, but keep in mind that a string matches the regular expression r* if it would match 0 or more concatenations of r. So we can match Star r to s if we can continue matching s with k, or if we can match r to part of s and continue trying to match Star r to the remaining portion of s. (This second possibility will look a lot like the Concat case.)
Once you have this case correctly implemented, you should find that, for example regex_match (Star (Char 'a')) "" evaluates to true, and so does regex_match (Star (Char 'a')) "aaa", but regex_match (Star (Char 'b')) "a" evaluates to false.
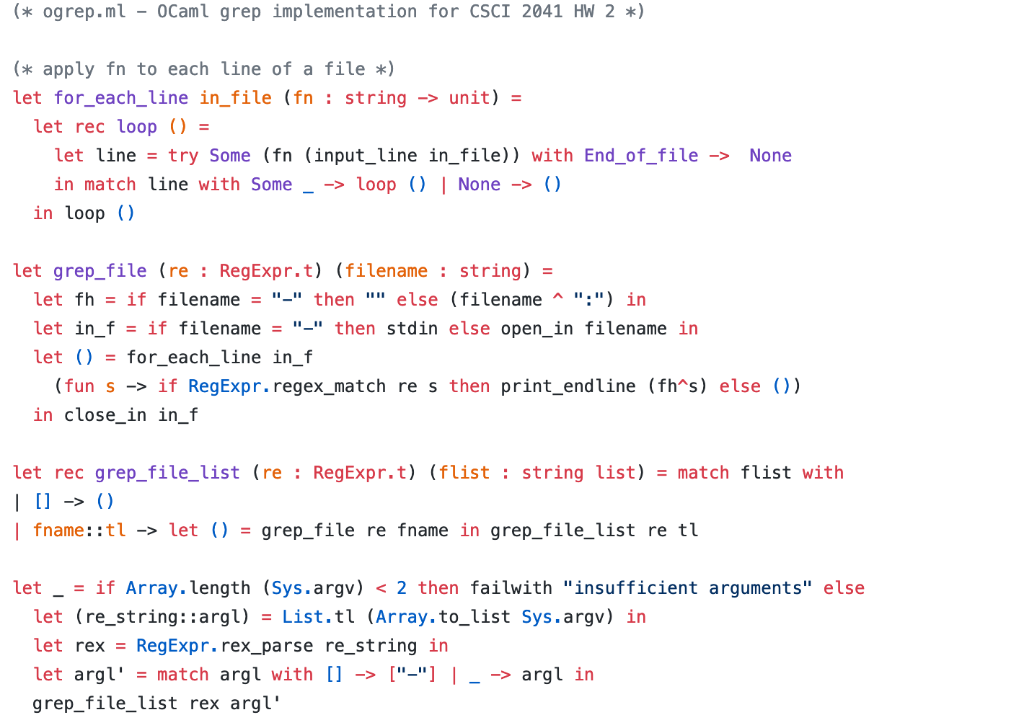



ogrep.ml 0Caml grep implementation for CSCI 2041 HW 2 ) apply fn to each line of a file x) let rec loop) let for_each_line in file (fn string -unit) let linetry Some (fn (input_line in_file)) with End_of file ->None in match line with SomeLoopNone - in loop () let grep_file (re RegExpr.t) (filename string) let fh = if filename - "-" then "" else (filename ^ ":") in let in_fif filename" then stdin else open_in filename in letfor_each_line in_f (fun s -> if RegExpr.regex_match re s then print_endline (fh s) else )) in close_in in_f let rec grep_file_ list (re: RegExpr.t) (flist string list)-match flist with I fname: :tl -> let grep_file re fname in grep_file list re tl let-= if Array.length (Sys.argv) argl in grep file_list rex argl' Tokens (substrings that make up regular expressions) ) type tok-LP | RP I U I DOT I ch of char (* turn a string into a list of regex tokens let rec tokenize sti- if String. length st-i then [] else if st. [i] -'\'then read_escape st (i+1) else (match st. [i] with '.' -> DOT | C -> Ch c):: (tokenize st (i+1)) and read_escape sti- if String. length st-i then failwith "trailing backslash" else (match st. [1] with "(' -> [LP] | c ->[Ch '; Ch c]) @ (tokenize st (i+1)) type regexpUnion of regexp regexp | Concat of regexp regexp | Char of char | Wild | NullSet (matches no strings at all *) (* parse a list of tokens into a regexp ) (each function takes a list of tokens, tries to parse a kind of regex from the list, and returns the list of unused tokens *) let re parse a "Base" Case regexp: Empty, NullSet, Bracket, Wild, or Char *) parse base_case token_list match token_list with I [ -> (NullSet, [) I DOT: :tl -(Wild,tl) 1 LP::tl-> let (re , t l') = parse-regex tl in (match tl' with RP::tl'"-> (re,tl'") I _failwith "expected close paren") I failwith "unexpected token" term-helper ti re -match t with (* parse a "factor" in a regex of the form r1 r2 r3 and ) *) term_helper tl re match tl with parse a "factor" in a regex of the form r1 r2 (r3 ..) ) | --> let (re-next, tl') parse-base-case tl in = term_helper tl' (Concat (re, re_next)) and parse-terms tl = match parse-base-case tl with (* parse a regex in the form r1 r2 (r3 ) *) I (t,tl')-> term_helper tl' t and regex_helper tl re-helper for parsing union of terms) let (t-next , tl') = parse-terms tl in match tl. with U::tl''->regex_helper t(Union (re, t_next)) > (Union (re, t_next), tl') and parse_regex tl-match parse_terms tl with parse a regex *) let rex-parse s = let n-String.length s in let s. = if n > 1 && s. [0] - '^' then String . sub s 1 (n-1) else ( *.. ^s) in let n'-String.length s' in let s"-if n'>1 && s'. [n'-1] then String.sub s0 (n'-1) else (s'".*" in let toklist = tokenize s.. 0 in match parse_regex tok_list with - (re, [) -> re I failwith ("regular expression string "sis unbalanced") (* Check if an exploded string matches a regex -a helper function ) uses "continuation"-style search: k is a "continuation function" that checks the rest of the string*) let rec re match re s kmatch (re,s) with (* If the first character matches Char c, continue checking the rest of the string with k*) I (Char c, []) ->false | (Char c, c2 : : t ) -> (c-C2) 66 (k t) (*Check if an exploded string matches a regex-a helper function ) (* uses "continuation"-style search: k is a "continuation function" that checks the rest of the string) let rec re-match re s k match (re,s) with (* If the first character matches Char c, continue checking the rest of the string with k *) I (Char c, [1) -> false | (Char c, c2: : t ) -> (c-c2) 66 (k t) ( Wild always eats a char *) | (Wild, )-false (* Check r1|r2 by first continuing with r1, and if that fails, continue with r2 ) I (Union (r1, r2), _) -> (re_match rl sk) II (re_match r2 s k) (* Check r1 r2 by checking rl, and if that succeeds, "continue" with r2 ) | (Concat (r1,r2),-)-> (re-match r1 s (fun s.-> re-match r2 s' k)) NullSet, false let explode s letn String.length s in let rec exphelp i acc ifi n then acc else exphelp (i+1) (s. [i]::acc) in List.rev (exphelp 0 []) (* given a regexp and string, decide if the string matches ) let regex_match rs- re match r (explode s) (() [) Common ocaml idiom: other files will call the regexp type RegExpr.t ) type t regexp ogrep.ml 0Caml grep implementation for CSCI 2041 HW 2 ) apply fn to each line of a file x) let rec loop) let for_each_line in file (fn string -unit) let linetry Some (fn (input_line in_file)) with End_of file ->None in match line with SomeLoopNone - in loop () let grep_file (re RegExpr.t) (filename string) let fh = if filename - "-" then "" else (filename ^ ":") in let in_fif filename" then stdin else open_in filename in letfor_each_line in_f (fun s -> if RegExpr.regex_match re s then print_endline (fh s) else )) in close_in in_f let rec grep_file_ list (re: RegExpr.t) (flist string list)-match flist with I fname: :tl -> let grep_file re fname in grep_file list re tl let-= if Array.length (Sys.argv) argl in grep file_list rex argl' Tokens (substrings that make up regular expressions) ) type tok-LP | RP I U I DOT I ch of char (* turn a string into a list of regex tokens let rec tokenize sti- if String. length st-i then [] else if st. [i] -'\'then read_escape st (i+1) else (match st. [i] with '.' -> DOT | C -> Ch c):: (tokenize st (i+1)) and read_escape sti- if String. length st-i then failwith "trailing backslash" else (match st. [1] with "(' -> [LP] | c ->[Ch '; Ch c]) @ (tokenize st (i+1)) type regexpUnion of regexp regexp | Concat of regexp regexp | Char of char | Wild | NullSet (matches no strings at all *) (* parse a list of tokens into a regexp ) (each function takes a list of tokens, tries to parse a kind of regex from the list, and returns the list of unused tokens *) let re parse a "Base" Case regexp: Empty, NullSet, Bracket, Wild, or Char *) parse base_case token_list match token_list with I [ -> (NullSet, [) I DOT: :tl -(Wild,tl) 1 LP::tl-> let (re , t l') = parse-regex tl in (match tl' with RP::tl'"-> (re,tl'") I _failwith "expected close paren") I failwith "unexpected token" term-helper ti re -match t with (* parse a "factor" in a regex of the form r1 r2 r3 and ) *) term_helper tl re match tl with parse a "factor" in a regex of the form r1 r2 (r3 ..) ) | --> let (re-next, tl') parse-base-case tl in = term_helper tl' (Concat (re, re_next)) and parse-terms tl = match parse-base-case tl with (* parse a regex in the form r1 r2 (r3 ) *) I (t,tl')-> term_helper tl' t and regex_helper tl re-helper for parsing union of terms) let (t-next , tl') = parse-terms tl in match tl. with U::tl''->regex_helper t(Union (re, t_next)) > (Union (re, t_next), tl') and parse_regex tl-match parse_terms tl with parse a regex *) let rex-parse s = let n-String.length s in let s. = if n > 1 && s. [0] - '^' then String . sub s 1 (n-1) else ( *.. ^s) in let n'-String.length s' in let s"-if n'>1 && s'. [n'-1] then String.sub s0 (n'-1) else (s'".*" in let toklist = tokenize s.. 0 in match parse_regex tok_list with - (re, [) -> re I failwith ("regular expression string "sis unbalanced") (* Check if an exploded string matches a regex -a helper function ) uses "continuation"-style search: k is a "continuation function" that checks the rest of the string*) let rec re match re s kmatch (re,s) with (* If the first character matches Char c, continue checking the rest of the string with k*) I (Char c, []) ->false | (Char c, c2 : : t ) -> (c-C2) 66 (k t) (*Check if an exploded string matches a regex-a helper function ) (* uses "continuation"-style search: k is a "continuation function" that checks the rest of the string) let rec re-match re s k match (re,s) with (* If the first character matches Char c, continue checking the rest of the string with k *) I (Char c, [1) -> false | (Char c, c2: : t ) -> (c-c2) 66 (k t) ( Wild always eats a char *) | (Wild, )-false (* Check r1|r2 by first continuing with r1, and if that fails, continue with r2 ) I (Union (r1, r2), _) -> (re_match rl sk) II (re_match r2 s k) (* Check r1 r2 by checking rl, and if that succeeds, "continue" with r2 ) | (Concat (r1,r2),-)-> (re-match r1 s (fun s.-> re-match r2 s' k)) NullSet, false let explode s letn String.length s in let rec exphelp i acc ifi n then acc else exphelp (i+1) (s. [i]::acc) in List.rev (exphelp 0 []) (* given a regexp and string, decide if the string matches ) let regex_match rs- re match r (explode s) (() [) Common ocaml idiom: other files will call the regexp type RegExpr.t ) type t regexp




