Only part c)
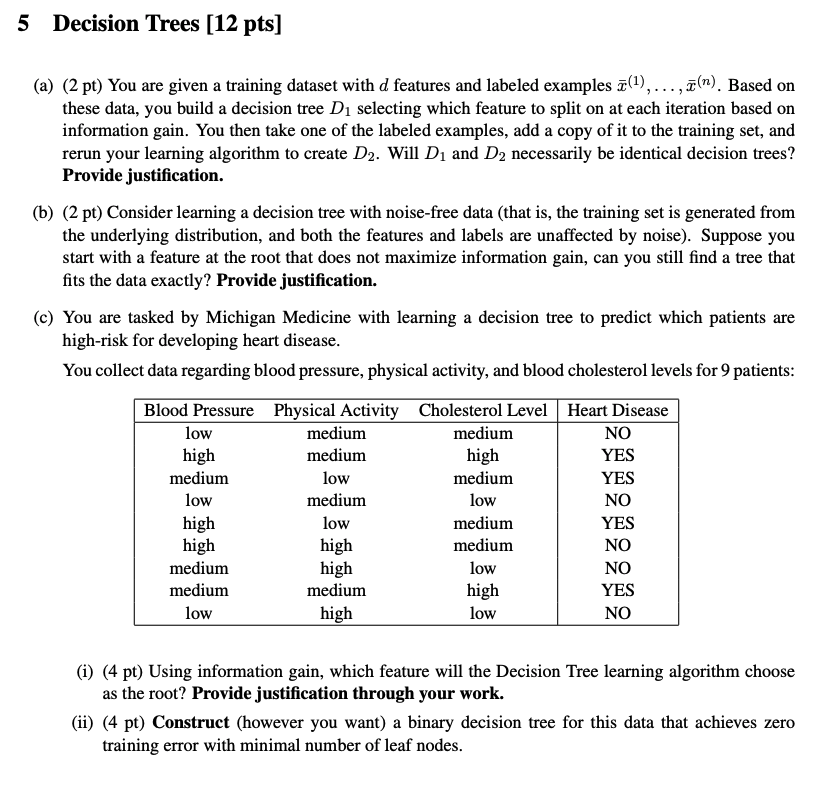
5 Decision Trees (12 pts] (a) (2 pt) You are given a training dataset with d features and labeled examples (1), ..., (n). Based on these data, you build a decision tree D1 selecting which feature to split on at each iteration based on information gain. You then take one of the labeled examples, add a copy of it to the training set, and rerun your learning algorithm to create D2. Will D1 and D2 necessarily be identical decision trees? Provide justification. (b) (2 pt) Consider learning a decision tree with noise-free data (that is, the training set is generated from the underlying distribution, and both the features and labels are unaffected by noise). Suppose you start with a feature at the root that does not maximize information gain, can you still find a tree that fits the data exactly? Provide justification. (c) You are tasked by Michigan Medicine with learning a decision tree to predict which patients are high-risk for developing heart disease. You collect data regarding blood pressure, physical activity, and blood cholesterol levels for 9 patients: low Blood Pressure Physical Activity Cholesterol Level Heart Disease medium medium NO high medium high YES medium low medium YES low medium low NO high low medium YES high high medium NO medium high low NO medium medium high YES low high low NO (i) (4 pt) Using information gain, which feature will the Decision Tree learning algorithm choose as the root? Provide justification through your work. (ii) (4 pt) Construct (however you want) a binary decision tree for this data that achieves zero training error with minimal number of leaf nodes. 5 Decision Trees (12 pts] (a) (2 pt) You are given a training dataset with d features and labeled examples (1), ..., (n). Based on these data, you build a decision tree D1 selecting which feature to split on at each iteration based on information gain. You then take one of the labeled examples, add a copy of it to the training set, and rerun your learning algorithm to create D2. Will D1 and D2 necessarily be identical decision trees? Provide justification. (b) (2 pt) Consider learning a decision tree with noise-free data (that is, the training set is generated from the underlying distribution, and both the features and labels are unaffected by noise). Suppose you start with a feature at the root that does not maximize information gain, can you still find a tree that fits the data exactly? Provide justification. (c) You are tasked by Michigan Medicine with learning a decision tree to predict which patients are high-risk for developing heart disease. You collect data regarding blood pressure, physical activity, and blood cholesterol levels for 9 patients: low Blood Pressure Physical Activity Cholesterol Level Heart Disease medium medium NO high medium high YES medium low medium YES low medium low NO high low medium YES high high medium NO medium high low NO medium medium high YES low high low NO (i) (4 pt) Using information gain, which feature will the Decision Tree learning algorithm choose as the root? Provide justification through your work. (ii) (4 pt) Construct (however you want) a binary decision tree for this data that achieves zero training error with minimal number of leaf nodes




