
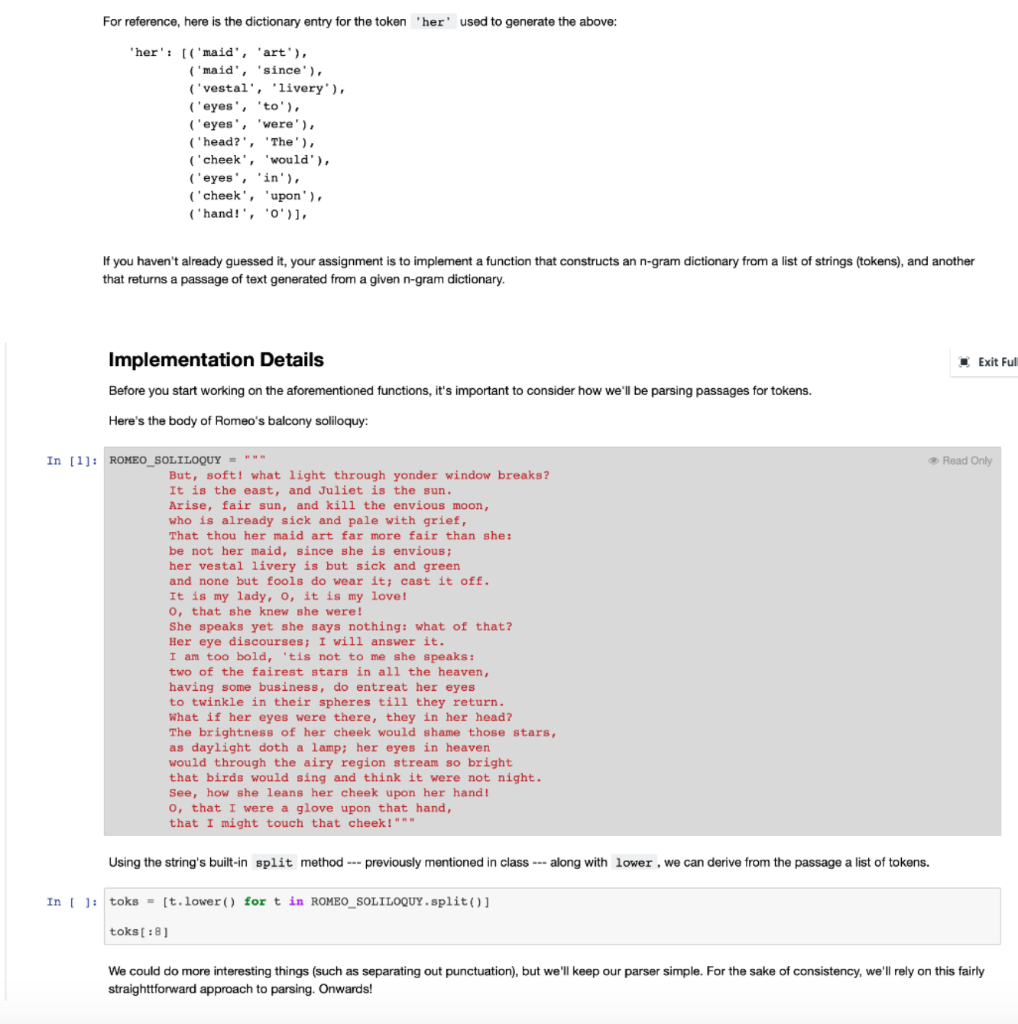
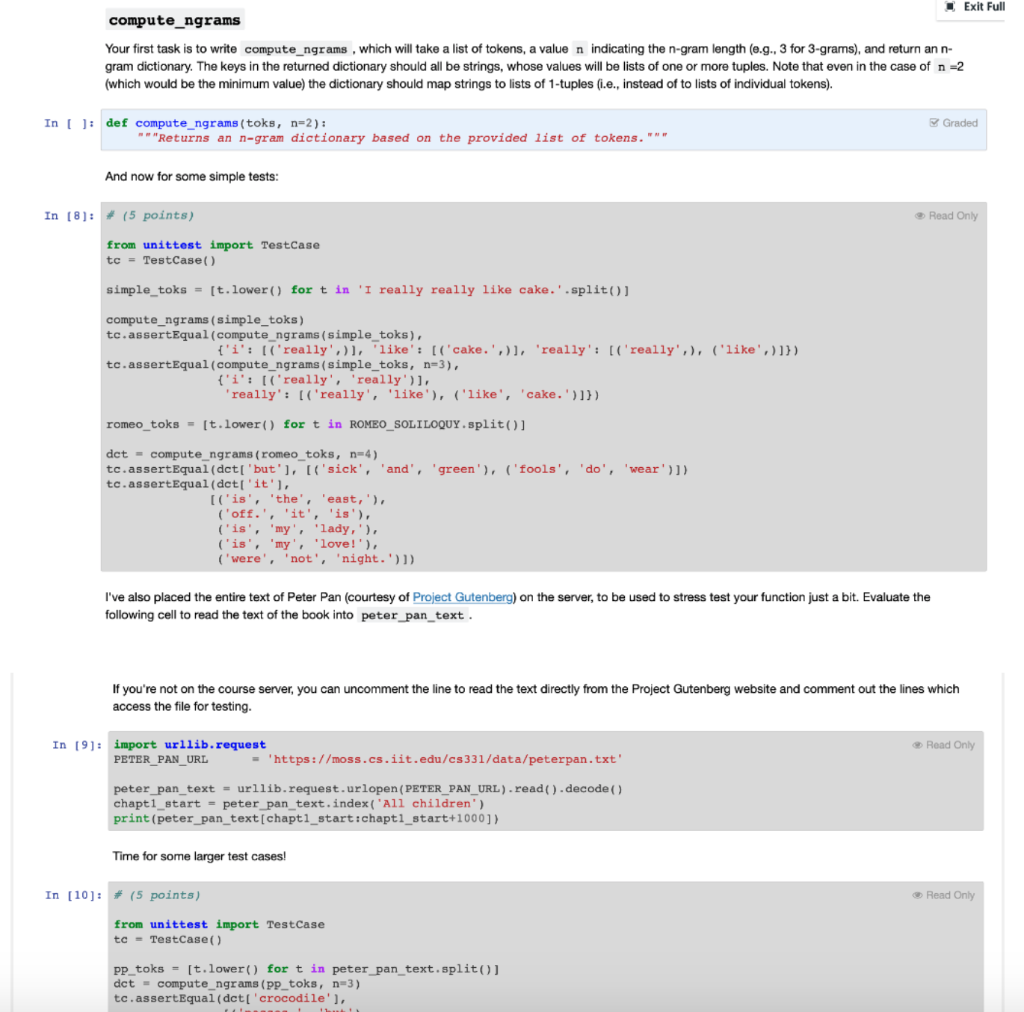
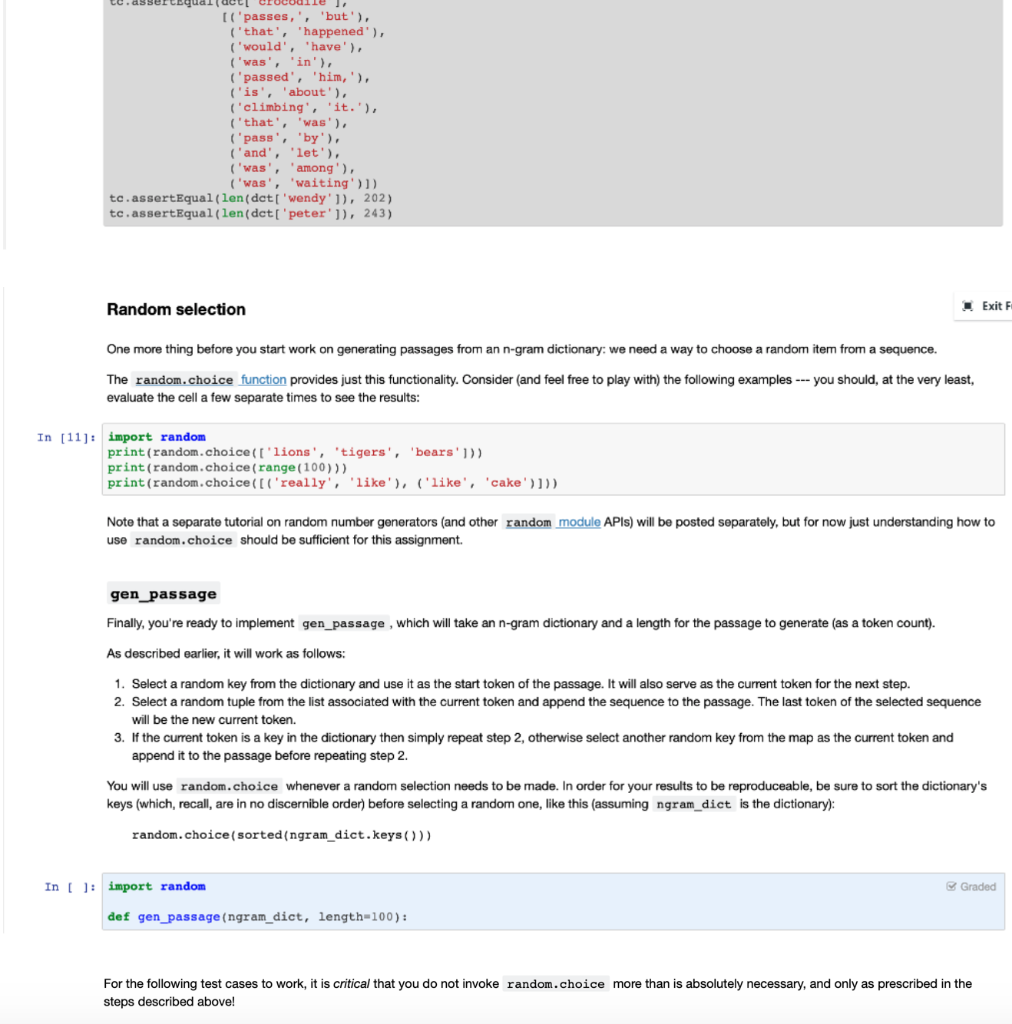
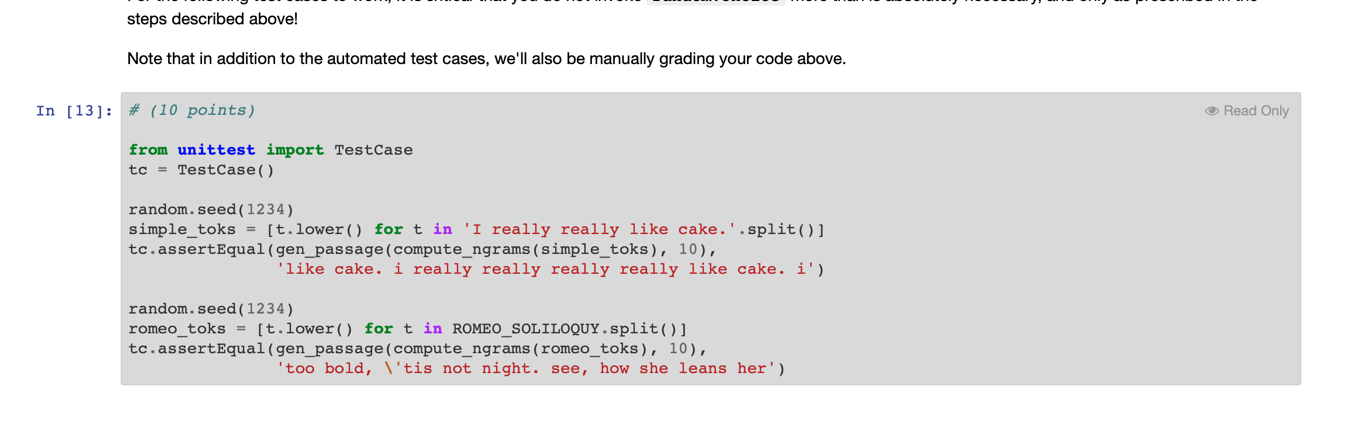
Overview Exit Full An n-gram -- in the context of parsing natural languages such as English -- is a sequence of n consecutive tokens (which we might define as characters separated by whitespace) from some passage of text. Based on the following passage: I really really like cake. We have the following 2-grams: [('I', 'really'), ('really', 'really'), ('really', 'like'), ('like', 'cake.')] And the following 3-grams: [('I', 'really', 'really'), ('really', 'really', 'like'), ('really', 'like', 'cake.')] (lomita 1-gram listing because it would merely be a list of all tokens in the original text.) Among other things, n-grams are useful for describing the vocabulary of and statistical correlation between tokens in a sample body of text (e.g., as taken from a book). We can use an n-gram model to determine the likelihood of finding a particular sequence of words after another. This information, in turn, can be used to generate passages of text that statistically mimic the sample. We can convert the above 3-gram list into the following lookup structure (i.e., a dictionary mapping strings to lists of 2-tuples), where the first token of each n- gram maps to all sequences that follow it in the text: {'I': [('really', 'really')], 'really': [('really', 'like'), ('like', 'cake.')}} We can now generate passages of text using the following method: 1. Select a random key and use it as the start token of the passage. It will also serve as the current token for the next step. 2. Select a random tuple from the list associated with the current token and append the sequence to the passage. The last token of the selected sequence will be the new current token. 3. If the current token is a key in the dictionary then simply repeat step 2, otherwise select another random key from the dictionary as the current token and append it to the passage before repeating step 2 E.g., we might start by selecting 'I' in step (1), which gives us ('really', 'really') as our only choice in (2). The second 'really in that tuple is the new current token (which is a valid key), which takes us back to (2) and gives us a choice between two tuples. If we choose ('like', 'cake.'), then we have 'cake.' as our new current token --- it is not a key in the map, however, so we'd have to choose a new random key if we wanted to generate a longer passage. Either way, the passage we've generated thus far is 'I really really like cake.' (which also happens to be the original passage). 's every time a new random key is Here's a lengthier passage that could be generated from the 3-gram dictionary above -- note that for clarity I've added selected (i.e., when the previous token isn't a key in the dictionary): * really like cake. I really really really like * really like cake. I really really really like really This gets more interesting when we build n-gram dictionaries from lengthier bodies of text. For instance, the following text was generated (with a little programmed embellishment for prettier capitalization and punctuation) from a 3-gram dictionary extracted from Romeo's famous balcony monologue: Lamp her eyes were there they in their spheres till they in her eyes in all the fairest stars in all the heaven having some business do wear it is my love! O it is envious her cheek would through the heaven having some business do entreat her eyes were there they in their spheres till they in her eyes to. For reference, here is the dictionary entry for the token 'her' used to generate the above: 'her': [('maid', 'art), ('maid', 'since'), ('vestal', 'livery'), ('eyes', 'to'), ('eyes', 'were'), ('head?', 'The'), ('cheek', 'would'), ('eyes', 'in'), ('cheek', 'upon'), ('hand!', '0')], If you haven't already guessed it, your assignment is to implement a function that constructs an n-gram dictionary from a list of strings (tokens), and another that returns a passage of text generated from a given n-gram dictionary Implementation Details Exit Ful Before you start working on the aforementioned functions, it's important to consider how we'll be parsing passages for tokens. Here's the body of Romeo's balcony soliloquy: Read Only In [1]: ROMEO_SOLILOQUY = "" But, soft! what light through yonder window breaks? It is the east, and Juliet is the sun. Arise, fair sun, and kill the envious moon, who is already sick and pale with grief, That thou her maid art far more fair than she be not her maid, since she is envious; her vestal livery is but sick and green and none but fools do wear it; cast it off. It is my lady, o, it is my love! O, that she knew she were! She speaks yet she says nothing: what of that? Her eye discourses; I will answer it. I am too bold, 'tis not to me she speaks: two of the fairest stars in all the heaven, having some business, do entreat her eyes to twinkle in their spheres till they return. What if her eyes were there, they in her head? The brightness of her cheek would shame those stars, as daylight doth a lamp: her eyes in heaven would through the airy region stream so bright that birds would sing and think it were not night. See, how she leans her cheek upon her hand! o, that I were a glove upon that hand, that I might touch that cheek!""" Using the string's built-in split method --- previously mentioned in class --- along with lower , we can derive from the passage a list of tokens. In [ ]: toks = [t. lower() for t in ROMEO_SOLILOQUY.split()] toks[:8) We could do more interesting things (such as separating out punctuation), but we'll keep our parser simple. For the sake of consistency, we'll rely on this fairly straighttforward approach to parsing. Onwards! Exit Full compute_ngrams Your first task is to write compute_ngrams , which will take a list of tokens, a value n indicating the n-gram length (e.g., 3 for 3-grams), and return an n- gram dictionary. The keys in the returned dictionary should all be strings, whose values will be lists of one or more tuples. Note that even in the case of n=2 (which would be the minimum value) the dictionary should map strings to lists of 1-tuples (.e., instead of to lists of individual tokens). Graded In ( ): def compute_ngrams (toks, n=2): "Returns an n-gram dictionary based on the provided list of tokens." And now for some simple tests: In [8]: + (5 points) Read Only from unittest import TestCase tc = Test Case() simple_toks = [t. lower() for t in 'I really really like cake.'.split() compute_ngrams (simple_toks) tc.assertEqual (compute_ngrams (simple_toks), {'i': [('really', )], 'like': [('cake.'.)], 'really': [('really',), ('like', )]}) tc.assertEqual (compute_ngrams (simple_toks, n=3), ('i': [('really, really')], 'really': [('really', 'like'), ('like', 'cake.')}}) romeo_toks - [t. lower() for t in ROMEO_SOLILOQUY.split() det = compute_ngrams (romeo_toks, n=4) tc.assertEqual(dct['but'], [('sick', 'and', 'green'), ('fools', 'do', 'wear'))) tc.assertEqual (dct['it'), [('is', 'the', 'east,'), ('off.', 'it', 'is'), ('is', 'my', 'lady,'), ('is', 'my', 'love!'), ('were', 'not', 'night.')]) I've also placed the entire text of Peter Pan (courtesy of Project Gutenberg) on the server, to be used to stress test your function just a bit. Evaluate the following cell to read the text of the book into peter_pan_text. If you're not on the course server, you can uncomment the line to read the text directly from the Project Gutenberg website and comment out the lines which access the file for testing. In [9]: Read Only import urllib.request PETER PAN URL - 'https://moss.cs.iit.edu/cs331/data/peterpan.txt' peter_pan_text = urllib.request.urlopen(PETER PAN URL).read().decode() chapt1_start = peter pan_text.index(All children") print (peter_pan_text[chapti_start chapt1_start+1000]) Time for some larger test cases! In [10]: + (5 points) Read Only from unittest import Test Case tc = TestCase() PP_toks = [t.lover() for t in peter_pan_text.split() dct = compute_ngrams (Pp_toks, n=3) tc.assertEqual(dct['crocodile'), te.assertEqualldett Crocodile [('passes,', 'but'), ('that', 'happened'), ('would', 'have'). ('was', 'in'), ('passed', 'him, '), ('is', 'about'). ('climbing', 'it.'), ('that', 'was'), ('pass', 'by'). ('and', 'let'). ('was', 'among'), ('was', 'waiting')]) tc.assertEqual(len(det['wendy']), 202) tc.assertEqual(len(det['peter']), 243) Random selection Exit F One more thing before you start work on generating passages from an n-gram dictionary: we need a way to choose a random item from a sequence. The random.choice function provides just this functionality. Consider (and feel free to play with) the following examples --- you should, at the very least, evaluate the cell a few separate times to see the results: In [11] import random print (random.choice(['lions', 'tigers', 'bears'])) print (random.choice (range (100))) print (random.choice ([('really', 'like'), ('like', 'cake')))) Note that a separate tutorial on random number generators (and other random module APIs) will be posted separately, but for now just understanding how to use random.choice should be sufficient for this assignment. gen passage Finally, you're ready to implement gen_passage, which will take an n-gram dictionary and a length for the passage to generate (as a token count). As described earlier, it will work as follows: 1. Select a random key from the dictionary and use it as the start token of the passage. It will also serve as the current token for the next step. 2. Select a random tuple from the list associated with the current token and append the sequence to the passage. The last token of the selected sequence will be the new current token. 3. If the current token is a key in the dictionary then simply repeat step 2, otherwise select another random key from the map as the current token and append it to the passage before repeating step 2. You will use random.choice whenever a random selection needs to be made. In order for your results to be reproduceable, be sure to sort the dictionary's keys (which, recall, are in no discernible order) before selecting a random one, like this (assuming ngram_dict is the dictionary): random.choice (sorted(ngram_dict.keys())) In [ ]: import random Graded def gen_passage (ngram_dict, length-100): For the following test cases to work, it is critical that you do not invoke random.choice more than is absolutely necessary, and only as prescribed in the steps described above! steps described above! Note that in addition to the automated test cases, we'll also be manually grading your code above. In [13]: # (10 points) Read Only from unittest import Test Case tc = TestCase() random.seed (1234) simple_toks = [t. lower() for t in 'I really really like cake.'.split()] tc.assertEqual (gen_passage (compute_ngrams (simple_toks), 10), like cake. i really really really really like cake. i') random.seed (1234) romeo_toks = [t.lower() for t in ROMEO_SOLILOQUY.split()] tc.assertEqual (gen passage ( compute_ngrams (romeo_toks), 10), 'too bold, I'tis not night. see, how she leans her')




