

Question
Part 2: Auto dataset revisited We also used the auto dataset two weeks ago in lab 6. We used it with LDA and QDA. Both
Part 2: Auto dataset revisited
We also used the auto dataset two weeks ago in lab 6. We used it with LDA and QDA. Both methods in R provide a CV argument that will compute a LOOCV estimate for us. If we want to compute a k-fold cross validation estimate when k is not equal to the number of instances, we have to either write our own code or find another library to use. Here we will write our own code! Write a function that accepts a dataframe, a model-building function (either lda or qda), and a value for K and returns an error estimate and its variance for k-fold cross validation. Use this function to generate values for the same kind of table you made in part 1. Compare these values to using the training set and a validation set to estimate the error rates, too. Finally, include a paragraph summarizing and explaining the results just as you did in part 1.
Below is the code in R markdown with the auto data, the training and testing split, and with the Linear Discriminant Analysis (LDA) and Quadratric Discriminant Analysis. and
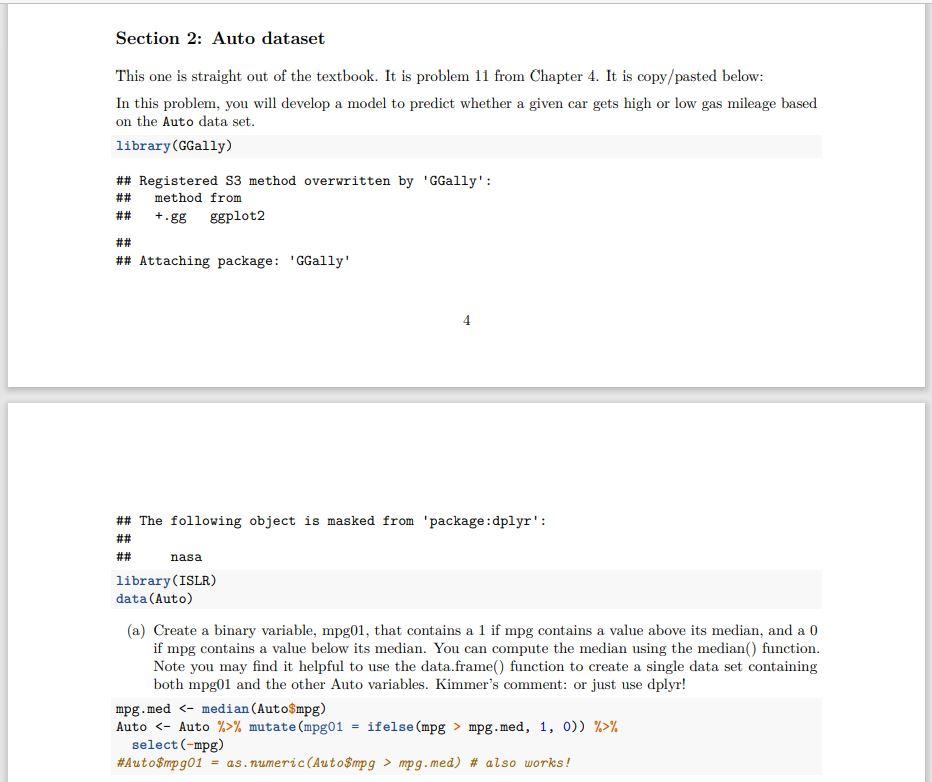
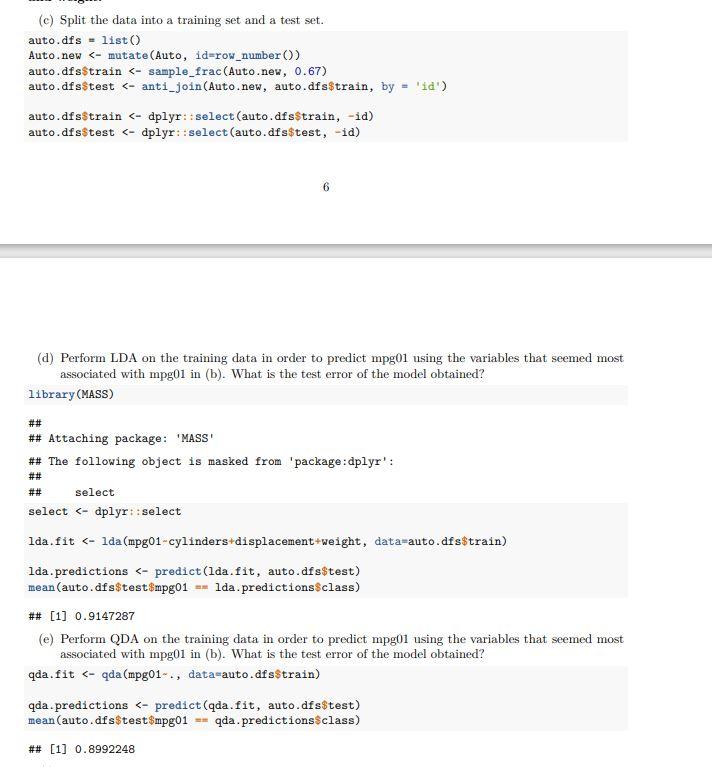
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Databases And Python Programming MySQL MongoDB OOP And Tkinter
Authors: R. PANNEERSELVAM
1st Edition
9357011331, 978-9357011334