

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
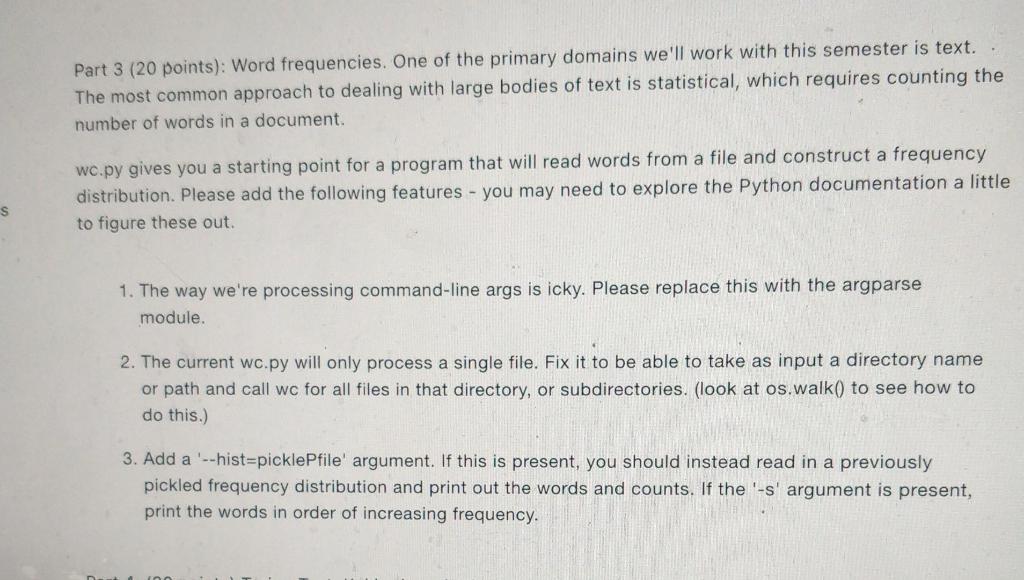
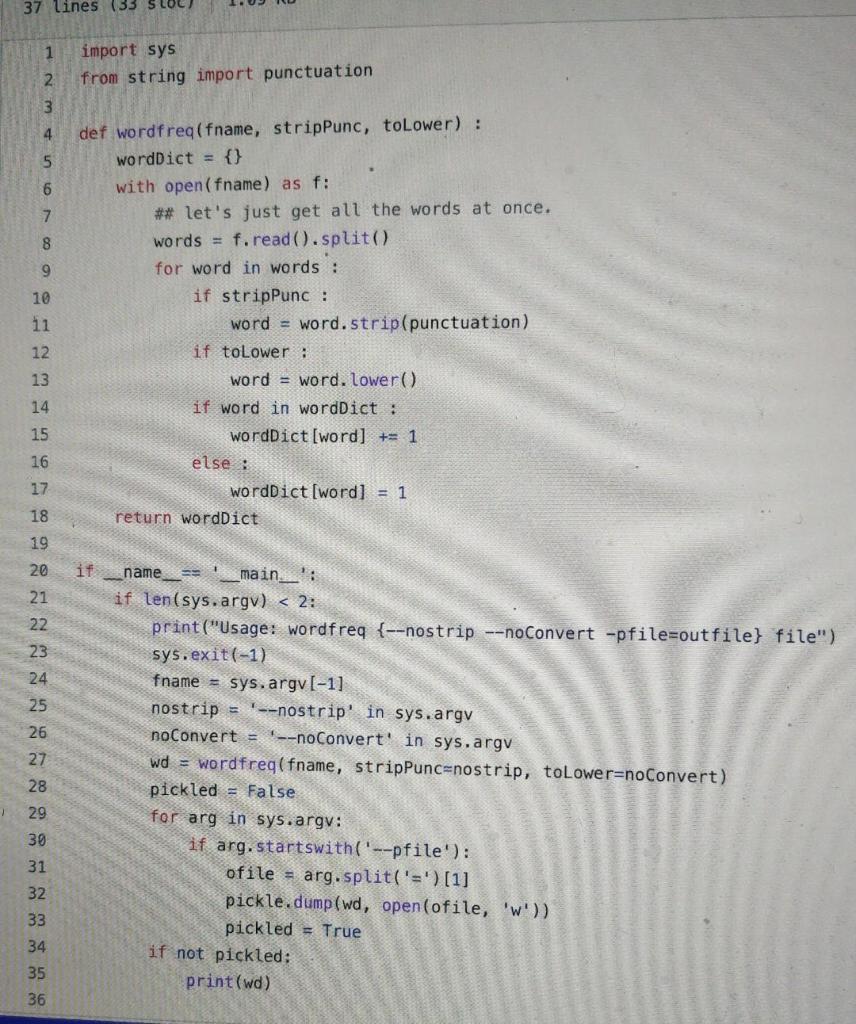
Part 3 (20 points): Word frequencies. One of the primary domains we'll work with this semester is text. The most common approach to dealing with
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Practical Database Programming With Visual C# .NET
Authors: Ying Bai
1st Edition
0470467274, 978-0470467275