

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
please choose the correct answer only. thanks. You'd like to train a fully-connected neural network with 5 hidden layers, each with 10 hidden units. The
please choose the correct answer only. thanks. 
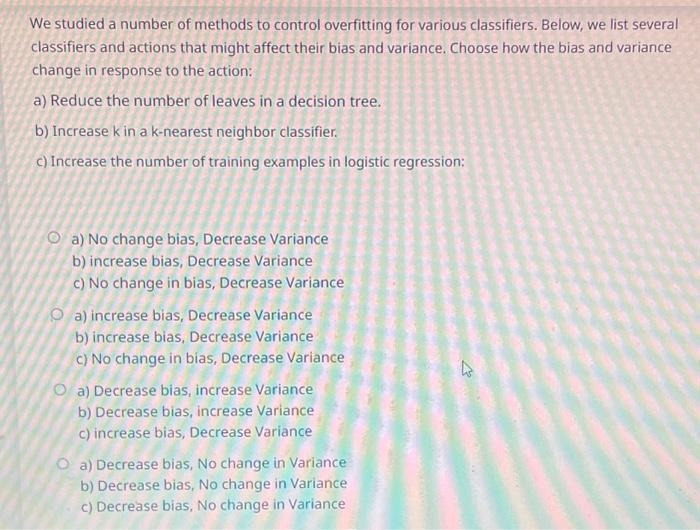

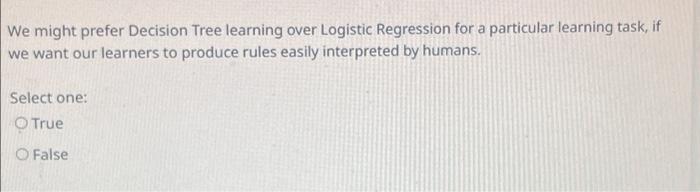




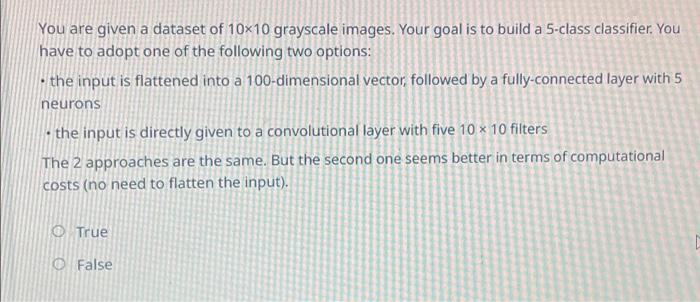
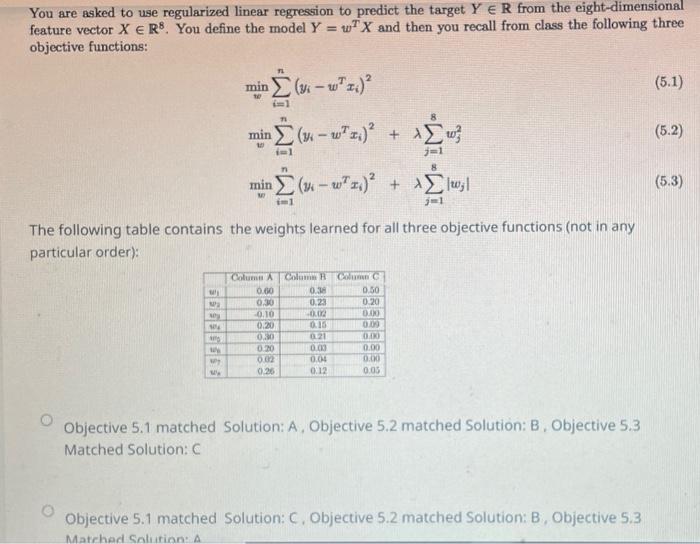
You'd like to train a fully-connected neural network with 5 hidden layers, each with 10 hidden units. The input is 20-dimensional and the output is a scalar. What is the total number of trainable parameters in your network? (20+1)10+(10+1)104+(10+1)(20+1)10+(10+1)105+(10+1)1(10+1)104+(10+1)1 We studied a number of methods to control overfitting for various classifiers. Below, we list several classifiers and actions that might affect their bias and variance. Choose how the bias and variance change in response to the action: a) Reduce the number of leaves in a decision tree. b) Increase k in a k-nearest neighbor classifier. c) Increase the number of training examples in logistic regression: a) No change bias, Decrease Variance b) increase bias, Decrease Variance c) No change in bias, Decrease Variance a) increase bias, Decrease Variance b) increase bias, Decrease Variance c) No change in bias, Decrease Variance a) Decrease bias, increase Variance b) Decrease bias, increase Variance c) increase bias, Decrease Variance a) Decrease bias, No change in Variance b) Decrease bias, No change in Variance c) Decrease bias, No change in Variance Assume we are trying to learn a decision tree. Our input data consists of N samples, each with k attributes (N>=k). We define the depth of a tree as the maximum number of nodes between the root and any of the leaf nodes (including the leaf, not the root). If all attributes are continuous, what is the maximum number of leaf nodes that we can have in a decision tree for this data? What is the maximal possible depth for a decision tree for this data? Continuous values can be used multiple times, so the maximum number of leaf nodes can be the same as the number of samples, N, and the maximal depth can also be N. Continuous values can be used multiple times, so the maximum number of leaf nodes is k, and the maximal depth can also be k. We might prefer Decision Tree learning over Logistic Regression for a particular learning task, if we want our learners to produce rules easily interpreted by humans. Select one: True False We might prefer Decision Tree learning over Logistic Regression for a particular learning task. Solution: If we want our learner to produce rules easily interpreted by humans. True False You are asked to use regularized linear regression to predict the target YR from the eight-dimensional feature vector XR8. You define the model Y=wTX and then you recall from class the following three objective functions: minwi=1n(yiwTxi)2minwi=1n(yiwTxi)2+j=18wj2minwi=1n(yiwTxi)2+j=18wj For large values of in objective 5.2 the bias would....(a)......, and For large values of in objective 5.3 the variance would. (b)............ (a) increase (b) increase (a) increase (b) decrease (a) decrease (b) decrease (a) decrease (b) increase Which of the following tends to work best on small data sets (few observations)? Logistic regression Naive Bayes You would like to train a dog/cat image classifier using mini-batch gradient descent. You have already split your dataset into train, validation, and test sets. The classes are balanced. You realize that within the training set, the images are ordered in such a way that all the dog images come first and all the cat images come after. which of the following is the correct action? You have to shuffle your training set before the training procedure you do not have to shuffle your training set before the training procedure You are given a dataset of 1010 grayscale images. Your goal is to build a 5-class classifier. You have to adopt one of the following two options: - the input is flattened into a 100-dimensional vector, followed by a fully-connected layer with 5 neurons - the input is directly given to a convolutional layer with five 1010 filters The 2 approaches are the same. But the second one seems better in terms of computational costs (no need to flatten the input). True False You are asked to use regularized linear regression to predict the target YR from the eight-dimensional feature vector XR8. You define the model Y=wTX and then you recall from class the following three objective functions: minwi=1n(yiwTxi)2minwi=1n(yiwTxi)2+j=18wj2minwi=1n(yiwTxi)2+j=18wj The following table contains the weights learned for all three objective functions (not in any particular order): Objective 5.1 matched Solution: A, Objective 5.2 matched Solution: B. Objective 5.3 Matched Solution: C Objective 5.1 matched Solution: C, Objective 5.2 matched Solution: B, Objective 5.3 Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Oracle 11G SQL
Authors: Joan Casteel
2nd Edition
1133947360, 978-1133947363