Please explain:-
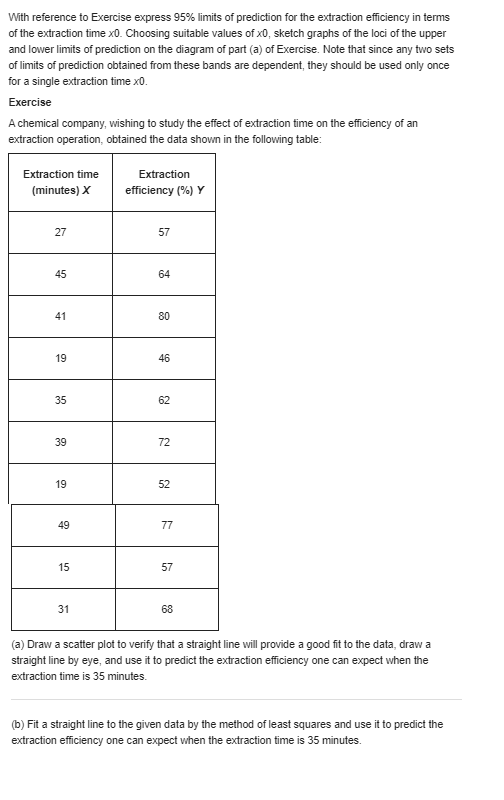
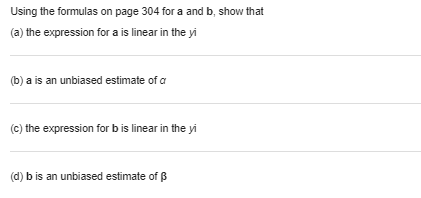
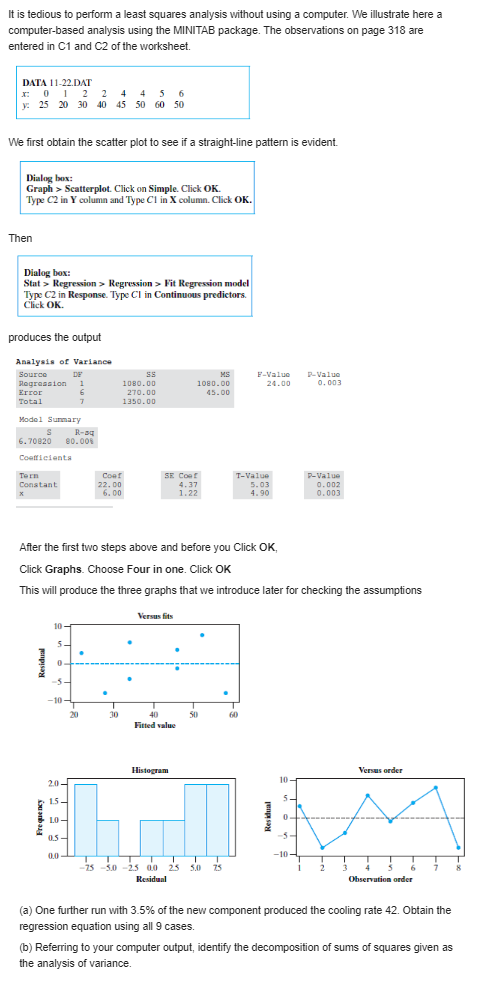
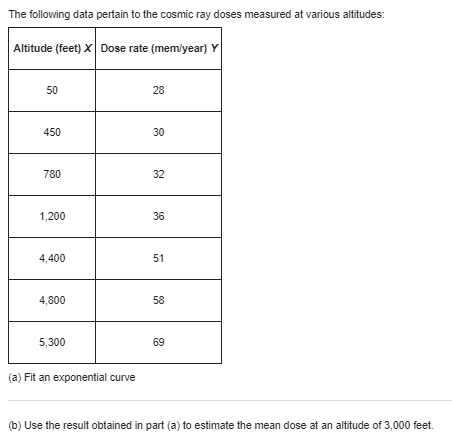
With reference to Exercise express 95% limits of prediction for the extraction efficiency in terms of the extraction time x0. Choosing suitable values of x0, sketch graphs of the loci of the upper and lower limits of prediction on the diagram of part (a) of Exercise. Note that since any two sets of limits of prediction obtained from these bands are dependent, they should be used only once for a single extraction time x0. Exercise A chemical company, wishing to study the effect of extraction time on the efficiency of an extraction operation, obtained the data shown in the following table: Extraction time Extraction (minutes) X efficiency (%) Y 27 57 45 64 41 80 19 46 35 62 39 72 19 52 49 77 15 57 31 68 (a) Draw a scatter plot to verify that a straight line will provide a good fit to the data, draw a straight line by eye, and use it to predict the extraction efficiency one can expect when the extraction time is 35 minutes. (b) Fit a straight line to the given data by the method of least squares and use it to predict the extraction efficiency one can expect when the extraction time is 35 minutes.When the sum of the x values is equal to zero, the calculation of the coefficients of the regression line of Y on x is greatly simplified; in fact, their estimates are given by and = Exy This simplification can also be attained when the values of x are equally spaced; that is, when they are in arithmetic progression. We then code the data by substituting for x the values . .., -2,-1, 0, 1, 2, . ... when n is odd, or the values . ..,-3,-1, 1, 3, ..., when n is even. The preceding formulas are then used in connection with the coded data. (a) Because of high lead residue, a faucet manufacturer cannot sell his product for home use unless each item is labeled as being hazardous to health. A consulting engineer suggests adding an acid bath at the end of the production line. An experiment is conducted with the bath having 0.2, 0.4, 0.6, 0.8, 1.0, 1.2 and 1.4 percent acid solutions. Suppose the corresponding values of lead residue are 4.6, 4.0, 3.3, 3.6, 3.0, 2.4, and 1.6 ppm. Fit a least squares line and give the point prediction of the lead residue when using a 1.3 percent solution. (b) Encouraged by the responses in Part (a), one further test was conducted with a 1.6 percent solution. Suppose the resulting lead residue is 1.1 ppm. Fit a least squares line using all eight runs. Again predict the lead residue for a 1.3 percent solutionUsing the formulas on page 304 for a and b, show that (a) the expression for a is linear in the yi (b) a is an unbiased estimate of a (c) the expression for b is linear in the yi (d) b is an unbiased estimate of BThe decomposition of the sums of squares into a contribution due to error and a contribution due to regression underlies the least squares analysis. Consider the identity M - y - (3 - y) = (X - >) Note that H=atbx = ] - bx+ bx = y+ b(x - X) 80 # - J = b(x -x) Using this last expression, then the definition of b and again the last expression, we see that and the sum of squares about the mean can be decomposed as total sum of squares error sum of squares regression rim of squares Generally, we find the straight-line fit acceptable if the ratio regression sum of squares =1 - total sum of squares is near 1. Calculate the decomposition of the sum of squares and calculate r2 using the observations in Exercise. Exercise The following data pertain to the number of computer jobs per day and the central processing unit (CPU) time required. Number of jobs X| CPU time Y N 2 5 4 4 9 5 10 (a) Use the first set of expressions on page 304, involving the deviations from the mean, to obtain a least squares fit of a line to the observations on CPU time. (b) Use the equation of the least squares line to estimate the mean CPU time at x = 3.5.It is tedious to perform a least squares analysis without using a computer. We illustrate here a computer-based analysis using the MINITAB package. The observations on page 318 are entered in C1 and C2 of the worksheet. DATA 11-22.DAT 0 2 2 4 4 5 6 y: 25 20 30 40 45 50 50 We first obtain the scatter plot to see if a straight-line pattern is evident. Dialog box: Graph > Scatterplot. Click on Simple. Click OK. Type C2 in Y column and Type Cl in X column. Click OK. Then Dialog box: Stat > Regression > Regression > Fit Regression model Type C2 in Response. Type CI in Continuous predictors. Click OK. produces the output Analysis of Variance Source DE MS F-Value P-Value Rograssion 1080.00 1080.00 24.00 0. 0 03 Error 270.00 45.00 Total 1350.00 Modal Summary R-D4 6. 70820 80.008 Coefficients Tern COAT SE COAT T-Value P-Value Constant 22. DO 4.37 5.03 0.002 X 6. 00 1.22 4.90 0.003 After the first two steps above and before you Click OK, Click Graphs. Choose Four in one. Click OK This will produce the three graphs that we introduce later for checking the assumptions Versus fits 10 5 Residual Fitted value Histogram Versus order 2.0- 10 - 1.5 - 5 - Residual Frequency 0.5- 0.0 75 -3.0 -25 00 25 5.0 75 Residual Observation order (a) One further run with 3.5% of the new component produced the cooling rate 42. Obtain the regression equation using all 9 cases. (b) Referring to your computer output, identify the decomposition of sums of squares given as the analysis of variance.\fThe following data pertain to the cosmic ray doses measured at various altitudes: Altitude (feet) X| Dose rate (mem/year) Y 50 28 450 30 780 32 1,200 36 4,400 51 4,800 58 5,300 69 (a) Fit an exponential curve (b) Use the result obtained in part (a) to estimate the mean dose at an altitude of 3,000 feet.With reference to the preceding exercise, change the equation obtained in part (a) to the form " alecx and use the result to rework part (b). Exercise The following data pertain to the cosmic ray doses measured at various altitudes: Altitude (feet) X| Dose rate (mem/year) Y 50 28 450 30 780 32 1,200 36 4,400 51 4,800 58 5,300 69 (a) Fit an exponential curve (b) Use the result obtained in part (a) to estimate the mean dose at an altitude of 3,000 feet