

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Please help me with python 3 H.W. This is the table for the previous Q --------------------------------------------------------------------------------------------------- Question 2. At the moment, the name column is
Please help me with python 3 H.W.
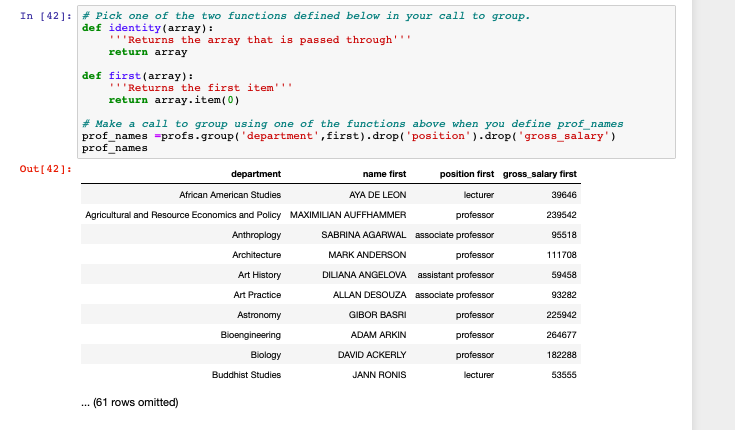
This is the table for the previous Q
---------------------------------------------------------------------------------------------------
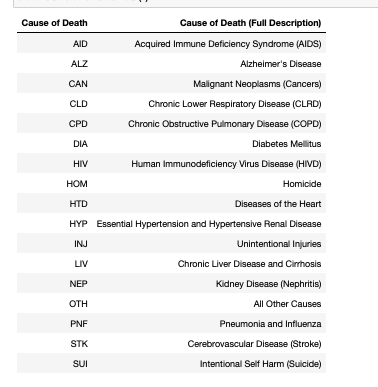
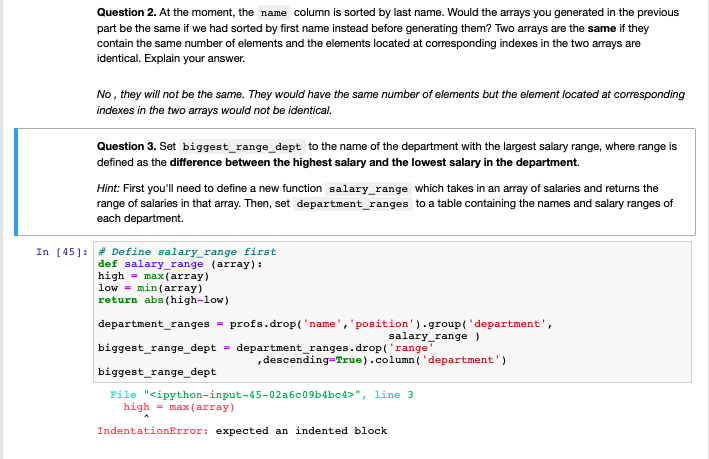
Question 2. At the moment, the name column is sorted by last name. Would the arrays you generated in the previous part be the same if we had sorted by first name instead before generating them? Two arrays are the same if they contain the same number of elements and the elements located at corresponding indexes in the two arrays are identical. Explain your answer. No, they will not be the same. They would have the same number of elements but the element located at corresponding indexes in the two arrays would not be identical. Question 3. Set biggest_range_dept to the name of the department with the largest salary range, where range is defined as the difference between the highest salary and the lowest salary in the department. Hint: First you'll need to define a new function salary range which takes in an array of salaries and returns the range of salaries in that array. Then, set department ranges to a table containing the names and salary ranges of each department. In [45]: # Define salary range first def salary_range (array): high-max(array) low = min(array) return abs (high-low) department ranges = profs.drop('name', 'position').group('department', salary_range) biggest_range_dept = department_ranges.drop( 'range' descending=True).column('department') biggest range_dept File "
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Making Databases Work The Pragmatic Wisdom Of Michael Stonebraker
Authors: Michael L. Brodie
1st Edition
1947487167, 978-1947487161