

Question
Please solve this problem in Python language. This is homework of Web and Data Mining course. Please use google colab if possible. Chegg does not
Please solve this problem in Python language. This is homework of Web and Data Mining course. Please use google colab if possible. Chegg does not allow me to post text files here. Please comment so that I can post text files in the comment section. Thank you.

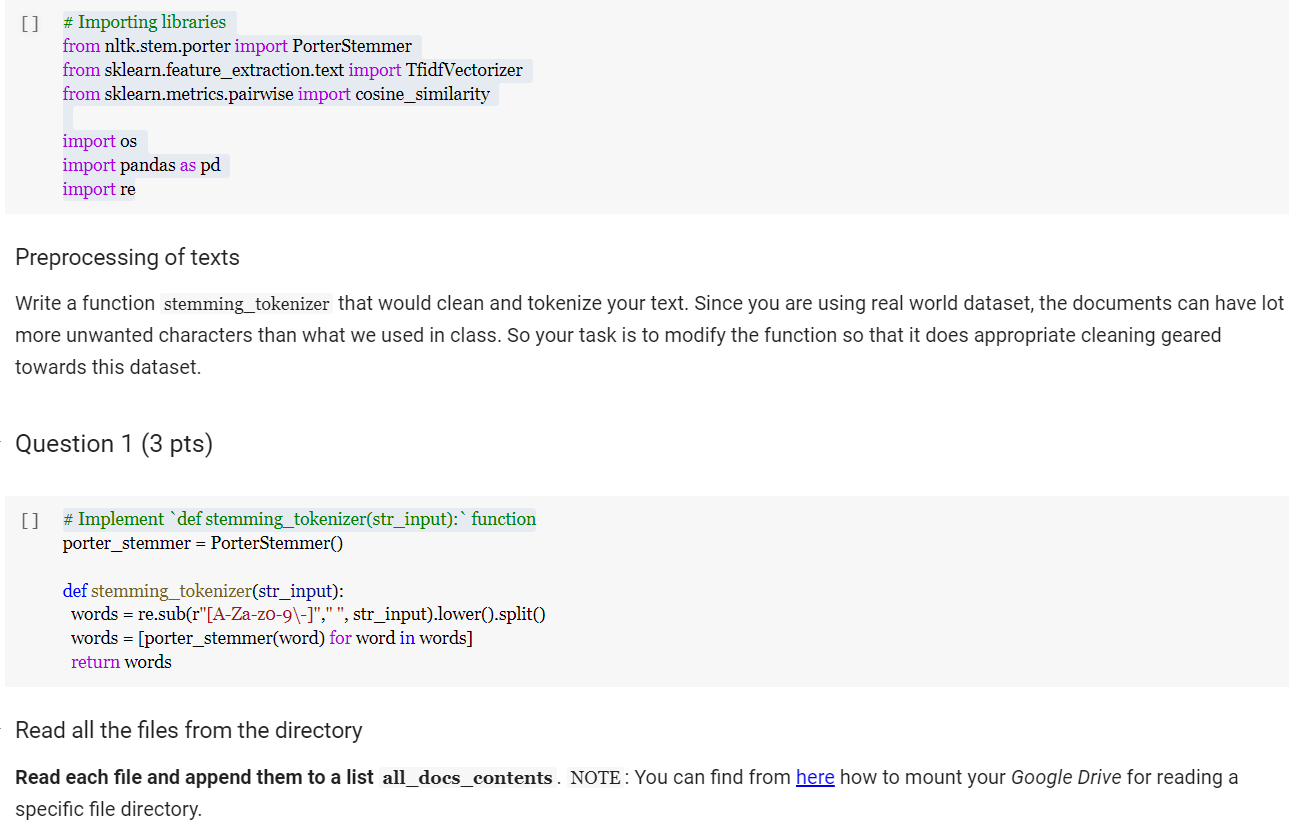
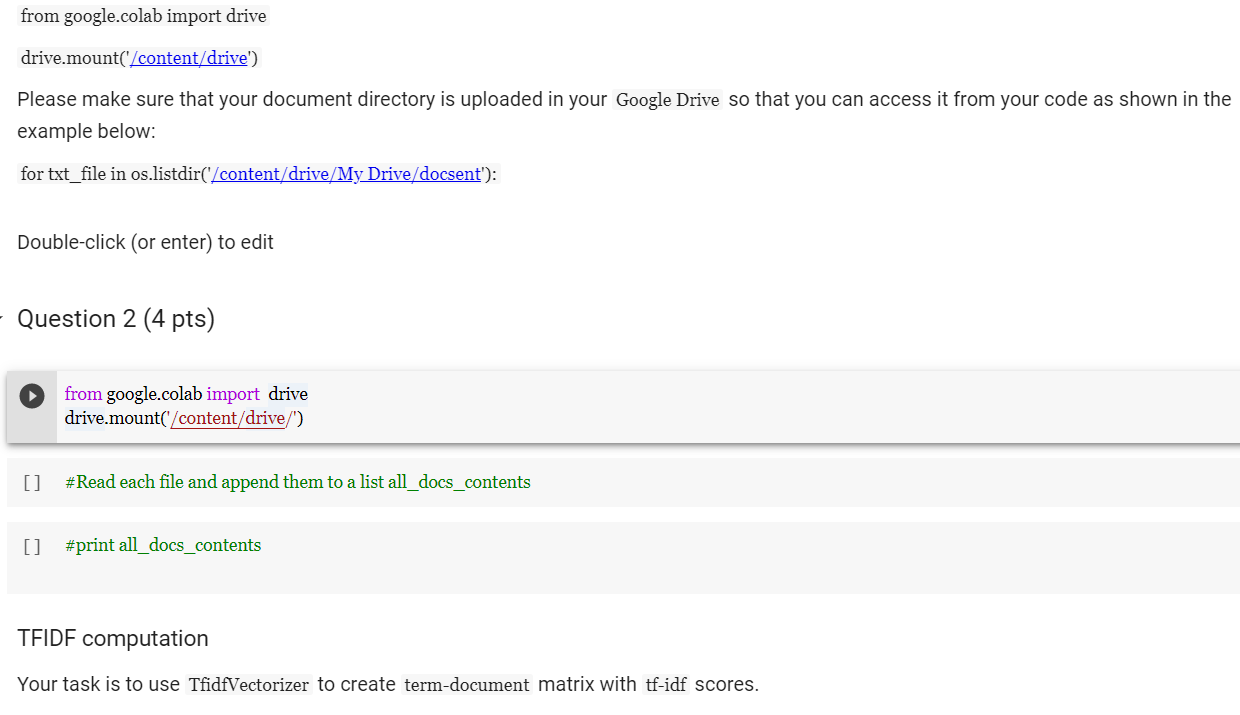
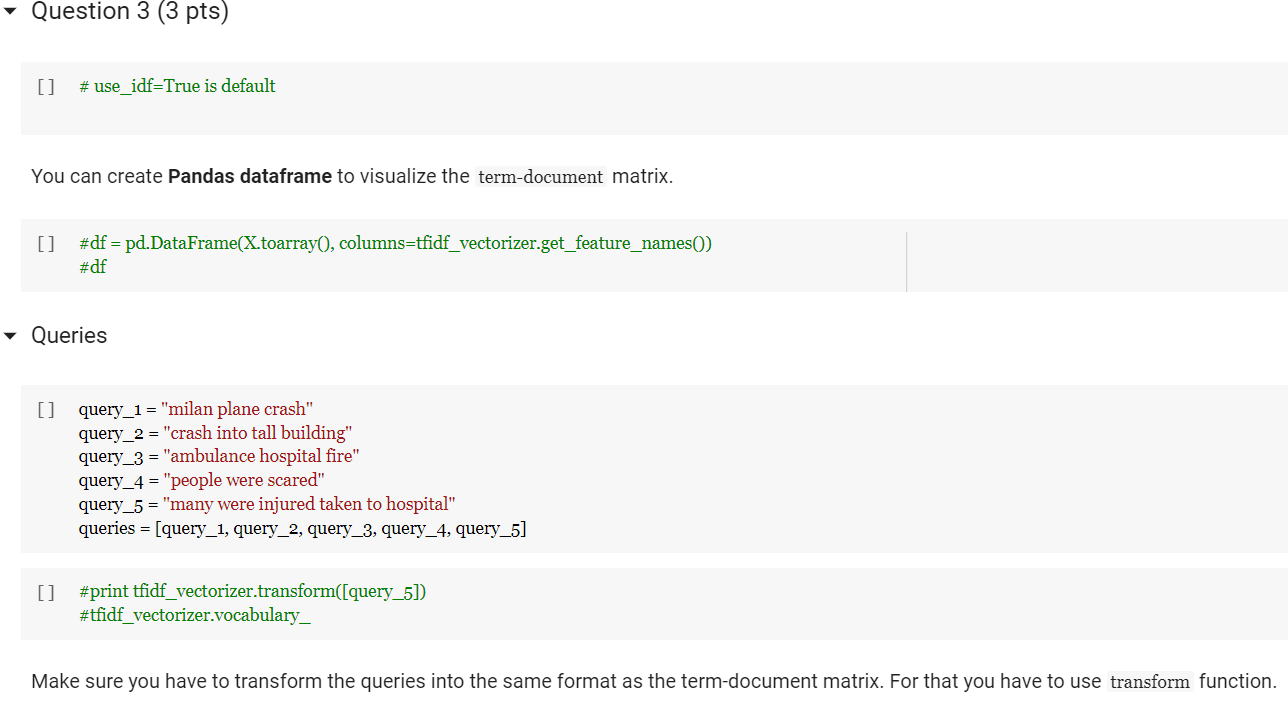
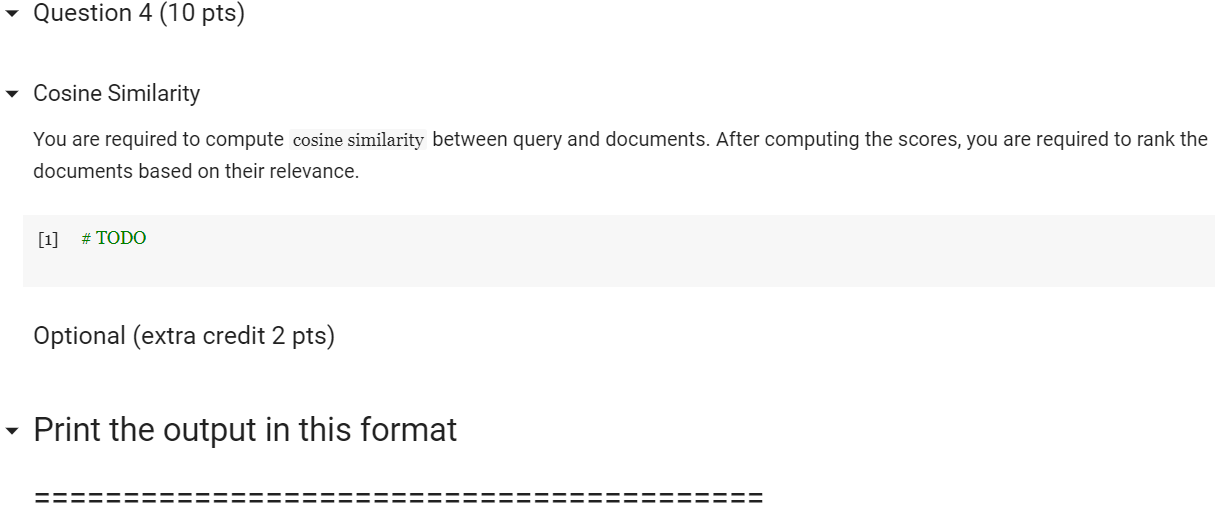

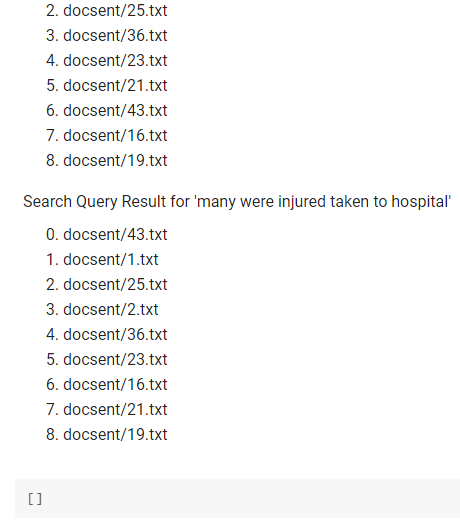
Problem Statement - You are designing an IR system in this homework. You are given a corpus and a set of query. Your task is to find the documents relevant to each query. The main goal of this homework is to make you conversant with tf-idf and cosine similarity using scikit-learn and understand different parameters. The dataset is collected from news articles related to Milan plane crash. Submission Instructions: Please download HW2.ipynb and docsent folder (with all the documents) and insert cells in the HW2.ipynb to complete your homework. Please feel free to use the w4-TextProcessing.ipynb and w5-tf-idf.ipynb as references to work on this homework. [] # Importing libraries from nltk.stem.porter import PorterStemmer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import os import pandas as pd import re Preprocessing of texts Write a function stemming_tokenizer that would clean and tokenize your text. Since you are using real world dataset, the documents can have lot more unwanted characters than what we used in class. So your task is to modify the function so that it does appropriate cleaning geared towards this dataset. Question 1 (3 pts) [] # Implement 'def stemming_tokenizer(str_input): function porter_stemmer = PorterStemmer def stemming_tokenizer(str_input): words = re.sub(r"[A-Za-Z0-9\-]"," ", str_input).lower().split() words = [porter_stemmer(word) for word in words] return words Read all the files from the directory Read each file and append them to a list all_docs_contents. NOTE: You can find from here how to mount your Google Drive for reading a specific file directory. from google.colab import drive drive.mount('/content/drive') Please make sure that your document directory is uploaded in your Google Drive so that you can access it from your code as shown in the example below: for txt_file in os.listdir('/content/drive/My Drive/docsent'): Double-click (or enter) to edit - Question 2 (4 pts) from google.colab import drive drive.mount('/content/drive/') [] #Read each file and append them to a list all_docs_contents [] #print all_docs_contents TEIDF computation Your task is to use TfidfVectorizer to create term-document matrix with tf-idf scores. Question 3 (3 pts) [] # use_idf=True is default You can create Pandas dataframe to visualize the term-document matrix. [] #df = pd.DataFrame(X.toarray(), columns=tfidf_vectorizer.get_feature_names()) #df Queries [] query_1 = "milan plane crash" query_2 = "crash into tall building" query_3 = "ambulance hospital fire" query_4 = "people were scared" query_5 = "many were injured taken to hospital" queries = [query_1, query_2, query_3, query_4, query_5] [] #print tfidf_vectorizer.transform([query_5]) #tfidf_vectorizer.vocabulary_ Make sure you have to transform the queries into the same format as the term-document matrix. For that you have to use transform function. Question 4 (10 pts) Cosine Similarity You are required to compute cosine similarity between query and documents. After computing the scores, you are required to rank the documents based on their relevance. # TODO Optional (extra credit 2 pts) Print the output in this format Search query Result for 'milan plane crash' 0. docsent/16.txt 1. docsent/23.txt 2. docsent/21.txt 3. docsent/36.txt 4. docsent/43.txt 5. docsent/1.txt 6. docsent/25.txt 7. docsent/19.txt 8. docsent/2.txt Search Query Result for 'crash into tall building' 0. docsent/36.txt 1. docsent/23.txt 2. docsent/21.txt 3. docsent/16.txt 4. docsent/2.txt 5. docsent/19.txt 6. docsent/1.txt 7. docsent/25.txt 8. docsent/43.txt Search Query Result for 'ambulance hospital fire 0. docsent/43.txt 1. docsent/1.txt 2. docsent/25.txt 3. docsent/2.txt 4. docsent/21.txt 5. docsent/16.txt 6. docsent/36.txt 7. docsent/19.txt 8. docsent/23.txt Search query Result for 'people were scared' 0. docsent/1.txt 1. docsent/2.txt 2. docsent/25.txt 3. docsent/36.txt 4. docsent/23.txt 5. docsent/21.txt 6. docsent/43.txt 7. docsent/16.txt 8. docsent/19.txt Search Query Result for 'many were injured taken to hospital' 0. docsent/43.txt 1. docsent/1.txt 2. docsent/25.txt 3. docsent/2.txt 4. docsent/36.txt 5. docsent/23.txt 6. docsent/16.txt 7. docsent/21.txt 8. docsent/19.txt [] Problem Statement - You are designing an IR system in this homework. You are given a corpus and a set of query. Your task is to find the documents relevant to each query. The main goal of this homework is to make you conversant with tf-idf and cosine similarity using scikit-learn and understand different parameters. The dataset is collected from news articles related to Milan plane crash. Submission Instructions: Please download HW2.ipynb and docsent folder (with all the documents) and insert cells in the HW2.ipynb to complete your homework. Please feel free to use the w4-TextProcessing.ipynb and w5-tf-idf.ipynb as references to work on this homework. [] # Importing libraries from nltk.stem.porter import PorterStemmer from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.metrics.pairwise import cosine_similarity import os import pandas as pd import re Preprocessing of texts Write a function stemming_tokenizer that would clean and tokenize your text. Since you are using real world dataset, the documents can have lot more unwanted characters than what we used in class. So your task is to modify the function so that it does appropriate cleaning geared towards this dataset. Question 1 (3 pts) [] # Implement 'def stemming_tokenizer(str_input): function porter_stemmer = PorterStemmer def stemming_tokenizer(str_input): words = re.sub(r"[A-Za-Z0-9\-]"," ", str_input).lower().split() words = [porter_stemmer(word) for word in words] return words Read all the files from the directory Read each file and append them to a list all_docs_contents. NOTE: You can find from here how to mount your Google Drive for reading a specific file directory. from google.colab import drive drive.mount('/content/drive') Please make sure that your document directory is uploaded in your Google Drive so that you can access it from your code as shown in the example below: for txt_file in os.listdir('/content/drive/My Drive/docsent'): Double-click (or enter) to edit - Question 2 (4 pts) from google.colab import drive drive.mount('/content/drive/') [] #Read each file and append them to a list all_docs_contents [] #print all_docs_contents TEIDF computation Your task is to use TfidfVectorizer to create term-document matrix with tf-idf scores. Question 3 (3 pts) [] # use_idf=True is default You can create Pandas dataframe to visualize the term-document matrix. [] #df = pd.DataFrame(X.toarray(), columns=tfidf_vectorizer.get_feature_names()) #df Queries [] query_1 = "milan plane crash" query_2 = "crash into tall building" query_3 = "ambulance hospital fire" query_4 = "people were scared" query_5 = "many were injured taken to hospital" queries = [query_1, query_2, query_3, query_4, query_5] [] #print tfidf_vectorizer.transform([query_5]) #tfidf_vectorizer.vocabulary_ Make sure you have to transform the queries into the same format as the term-document matrix. For that you have to use transform function. Question 4 (10 pts) Cosine Similarity You are required to compute cosine similarity between query and documents. After computing the scores, you are required to rank the documents based on their relevance. # TODO Optional (extra credit 2 pts) Print the output in this format Search query Result for 'milan plane crash' 0. docsent/16.txt 1. docsent/23.txt 2. docsent/21.txt 3. docsent/36.txt 4. docsent/43.txt 5. docsent/1.txt 6. docsent/25.txt 7. docsent/19.txt 8. docsent/2.txt Search Query Result for 'crash into tall building' 0. docsent/36.txt 1. docsent/23.txt 2. docsent/21.txt 3. docsent/16.txt 4. docsent/2.txt 5. docsent/19.txt 6. docsent/1.txt 7. docsent/25.txt 8. docsent/43.txt Search Query Result for 'ambulance hospital fire 0. docsent/43.txt 1. docsent/1.txt 2. docsent/25.txt 3. docsent/2.txt 4. docsent/21.txt 5. docsent/16.txt 6. docsent/36.txt 7. docsent/19.txt 8. docsent/23.txt Search query Result for 'people were scared' 0. docsent/1.txt 1. docsent/2.txt 2. docsent/25.txt 3. docsent/36.txt 4. docsent/23.txt 5. docsent/21.txt 6. docsent/43.txt 7. docsent/16.txt 8. docsent/19.txt Search Query Result for 'many were injured taken to hospital' 0. docsent/43.txt 1. docsent/1.txt 2. docsent/25.txt 3. docsent/2.txt 4. docsent/36.txt 5. docsent/23.txt 6. docsent/16.txt 7. docsent/21.txt 8. docsent/19.txt []
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
MFDBS 89 2nd Symposium On Mathematical Fundamentals Of Database Systems Visegrad Hungary June 26 30 1989 Proceedings
Authors: Janos Demetrovics ,Bernhard Thalheim
1989th Edition
3540512519, 978-3540512516