

Question
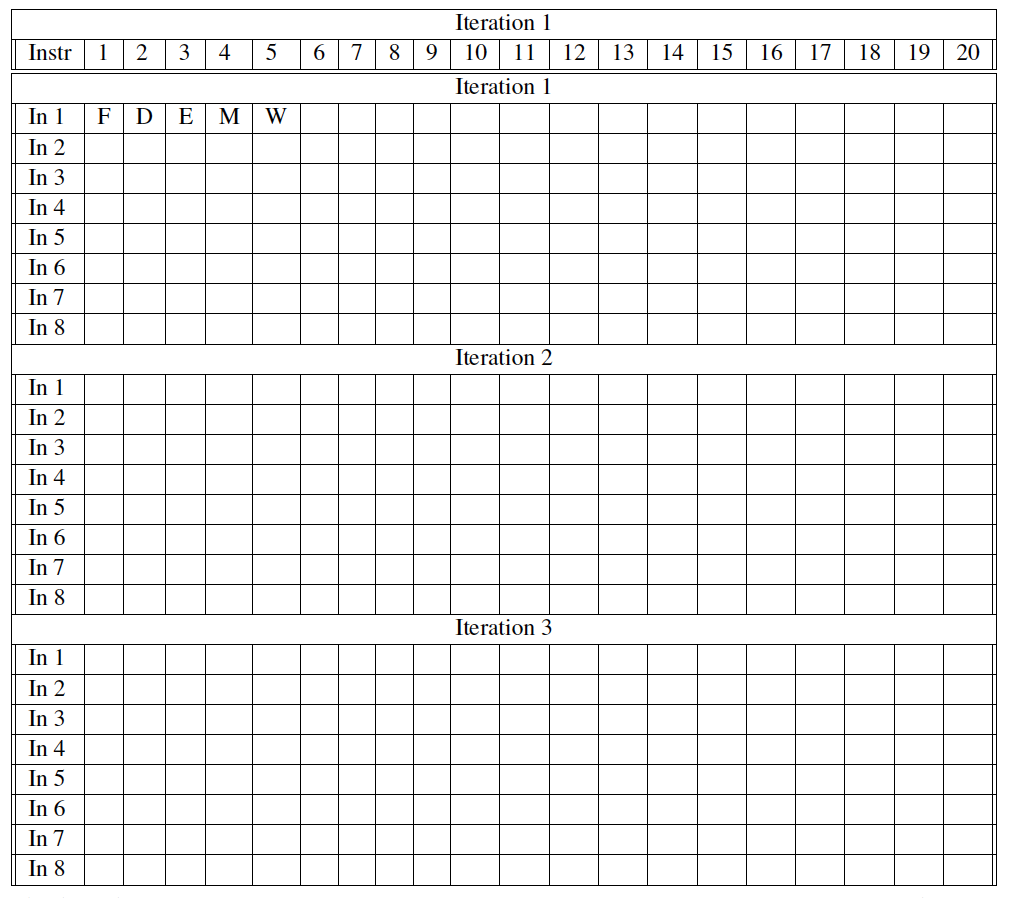
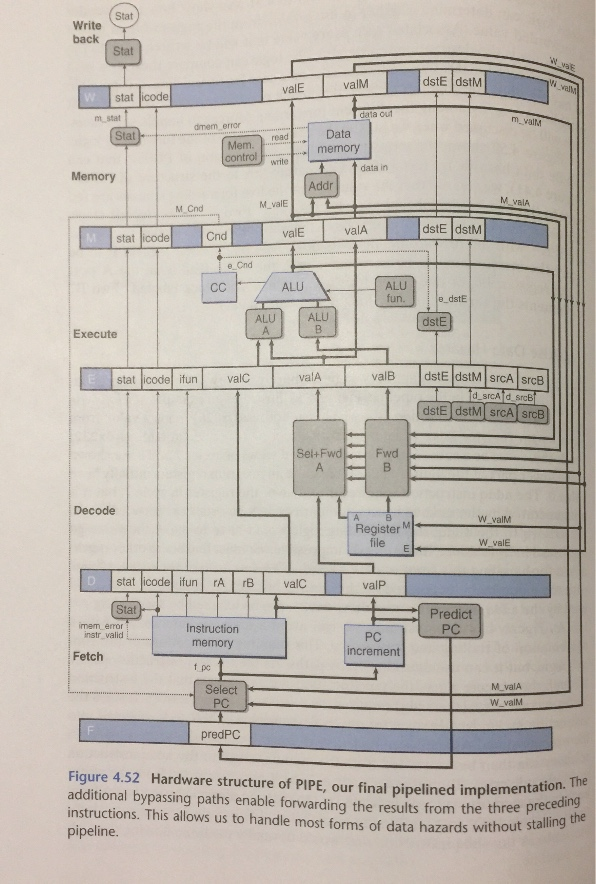
Problem 3: Consider a pipelined processor with bypassing paths as shown in Figure 4.52 and a perfect branch predictor. Fill in the following tables with
Problem 3: Consider a pipelined processor with bypassing paths as shown in Figure 4.52 and a perfect branch predictor. Fill in the following tables with which execution stage each instruction is in, during each clock cycle. The columns correspond to clock cycles. The rows correspond to individual instructions. Instructions can appear multiple time in the table, because these instructions are part of a loop. For example, the existing entries in the table indicate that In 1 is in fetch stage in cycle 1, in decode stage in cycle 2, in execution stage in cycle 3 in memory stage in cycle 4 and in writeback stage in cycle 5. Marks all the bypassings that occur during the execution.
Code segment:

The throughput of a pipeline is typically measure in terms of cycle per instruction (CPI). CPI is the average number of instructions graduated per clock cycle. The performance of a pipeline is function of the CPI and the clock rate.
1. The effective throughput of this pipeline in executing this code segment = ____________;
2. If the clock operates at 1GHz, the instruction per second achieved by the pipeline on this code = ____________.
figure 4.52:
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
SQL Server T-SQL Recipes
Authors: David Dye, Jason Brimhall
4th Edition
1484200616, 9781484200612