

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Problem 3 : TokenizationIf your regular expression is right, all the tests defined below should pass: init _ test ( ) TEST _ EXAMPLES (
Problem : TokenizationIf your regular expression is right, all the tests defined below should pass:
inittest
TESTEXAMPLES
This is a test!Thisisa 'test',
Is this a test?Is 'this', a 'test',
I don't think this is a test", Idont 'think', 'this', isa 'test"
Thy ph c ca ti ly ca ln
Thy 'phi', cacatilycaln
Isit 'legal', to 'shout', "The word 'very' is very overused",
The word 'very' is very overused", 'word', 'very', is 'very', 'over', 'used'
I don't think we'll"ve been there yet",
Idont 'think', weve 'been', 'there', 'yet'
Give me apples, please", Giveme 'apples', 'please'
A tip on a $ tab is dollars",
A 'tip', ona$ 'tab', is 'dollars'
Qpytest.mark.parametrizetext toks', TESTEXANPLES
def testtokenizertext toks:
testtokenizertext toks: assert tokenizetext toks
runtest
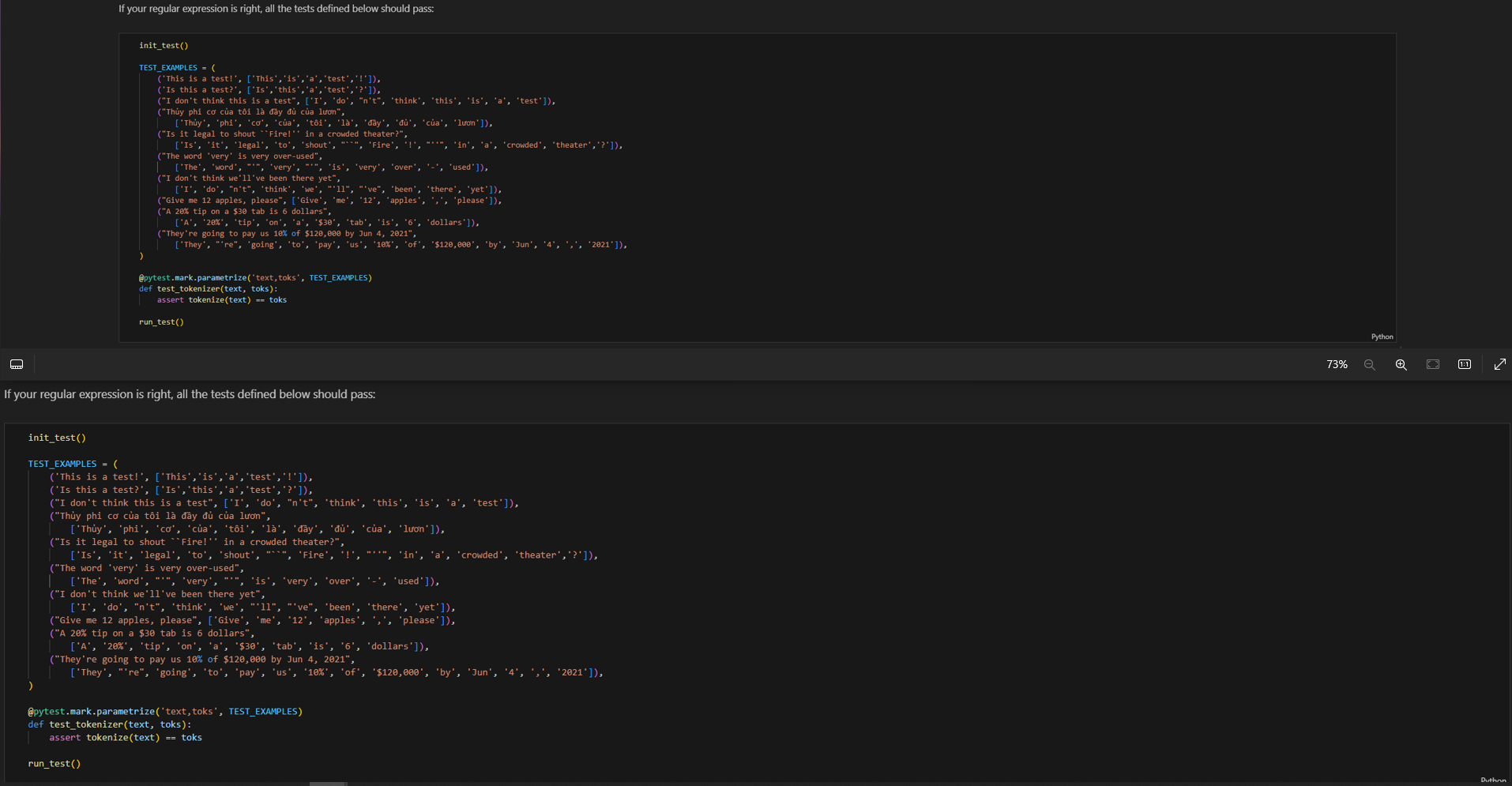
If your regular expression is right, all the tests defined below should pass:
inittest
TESTEXAMPLES
This is a test!Thisisa 'test',
Is this a test?Is 'this', a 'test',
I don't think this is a test", Idont 'think', 'this', isa 'test'
Thy phi c ca ti ly ca ln
Thy 'phi', ccatilycaln
Is it legal to shout 'Fire! in a crowded theater?",
Isit 'legal', to 'shout', 'Fire', ina 'crowded', 'theater',
The word 'very' is very overused",
The 'word', 'very', is 'very', 'over', 'used'
I don't think we'll've been there yet",
Idont 'think', weve 'been', 'there", 'yet"
Give me apples, please", Giveme 'apples', 'please'
A tip on a $ tab is dollars",
A 'tip', ona $ 'tab', is 'dollars'
Theyre going to pay us of $ by Jun
Theyre 'going', to 'pay', usof$by 'Jun',
Qpytest.mark.parametrizetexttoks', TESTEXAMPLES
def testtokenizertext toks:
assert tokenizetext toks
runtest
Modify this expression so that it meets the following additional requirements:
the punctuation marks and left double apostrophe and right double apostrophe should be single tokens
like nt the contractions vere and s should be seperate tokens
numbers should be separate tokens, where:
@ a number may start with $ or end with
a number may start with or contain a comma but may not end with one technically number tokens shouldn't start with a comma but it's okay if your transducer allows it
tokpatterns
# insert spaces before and after punctuation
tokpatternspunct
FSTrer$rewrite: :
# insert space before nt
tokpatternscontract
FSTrer$rewrite : t
tokenizer
FSTre$punct @ $contract", tokpatterns
def tokenizes:
listtokenizergenerates
if len :
return split
else:
return None
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Concepts
Authors: David M. Kroenke, David J. Auer
7th edition
133544621, 133544626, 0-13-354462-1, 978-0133544626