

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
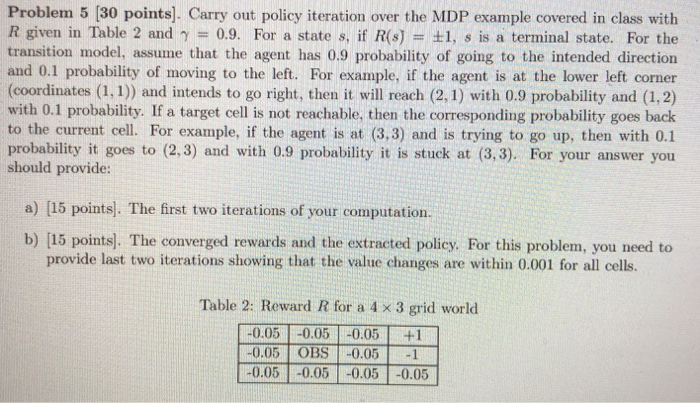
Problem 5 [30 points]. Carry out policy iteration over the MDP example covered in class with R given in Table 2 and = 0.9. For
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Advanced Data Management For Sql Nosql Cloud And Distributed Databases
Authors: Lena Wiese
1st Edition
9783110441406