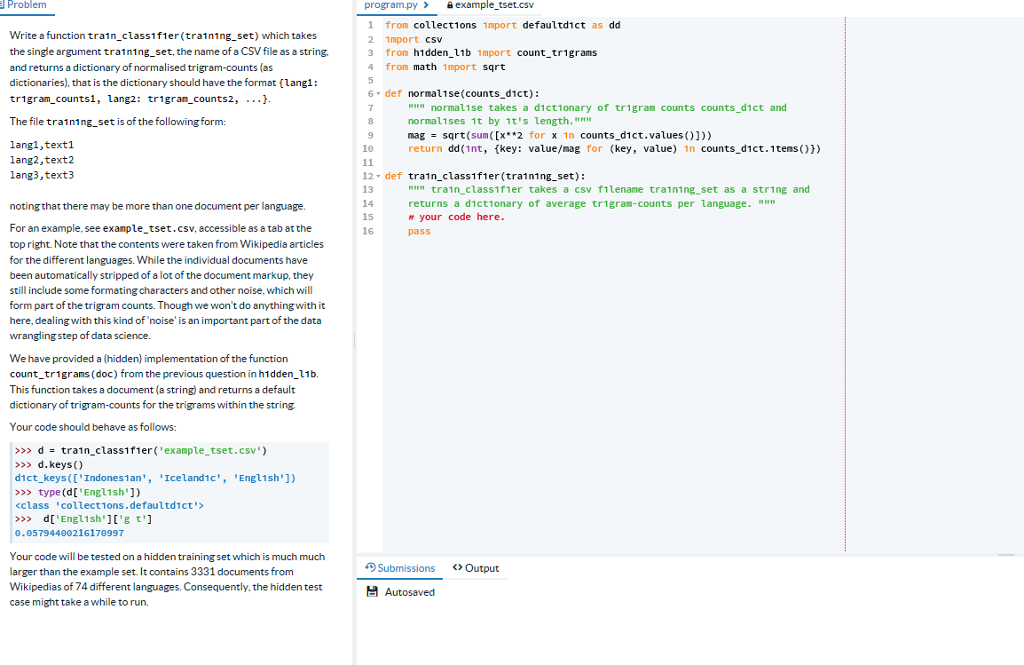
Problem Write a function tra1n class1f1er (tra1ning set) which takes the single argument training set, the name of a CSV file as a string. and returns a dictionary of normalised trigram-counts (as dictionaries), that is the dictionary should have the format (lang1: tr1gram countsl, lang2: tr1gran counts2, ...] program.py > exampletset.csv 1 from collections 1mport defaultdict as dd 2 1mport csv 3 from h1dden_l1b 1mport count trigrams 4 from math 1mport sqrt 6 def normal1se(counts d1ct) normalise takes a d1ct1onary of tr1gram counts counts_dict and normal1ses 1t by 1t's length. " mag = sqrt(sun((x**2 for x 1n counts-d1ct.values()))) return dd (1nt, (key: value/mag for (key, value) 1n counts dict.tens) The file tra1ning set is of the following form: lang1,text1 lang2,text2 lang3,text3 1e 12 def tra1n class1fier (tra1ning set): 13 tra1n classifier takes a csv f1lename tra1ning set as a string and returns a dict1onary of average trigram-counts per language. r your code here pass noting that there may be more than one document per language 15 For an example, see example tset.csv, accessible as a tab at the top right. Note that the contents were taken from Wikipedia articles for the different languages. While the individual documents have been automatically stripped of a lot of the document markup, they still include some formating characters and other noise, which will form part of the trigram counts. Though we won't do anythingwith it here, dealing with this kind of 'noise' is an important part of the data wrangling step of data science. 16 We have provided a (hidden) implementation of the function count_trigrams (doc) from the previous question in h1dden_l1b. This function takes a document (a string) and returns a default dictionary of trigram-counts for the trigrams within the string Your code should behave as follows >>> d = tra1n-class1f1er( ' example-tset.csv ') > d.keys() dict_keys (['Indones1an' 'Icelandic', 'Engl1sh']) >>> type (dI Engl1sh']) class collections.defaultdict 0.05794400216170997 Your code will be tested on a hidden training set which is much much larger than the example set. It contains 3331 documents from Wikipedias of 74 different languages, Consequently, the hidden test case might take a while to run. Submissions Output Problem Write a function tra1n class1f1er (tra1ning set) which takes the single argument training set, the name of a CSV file as a string. and returns a dictionary of normalised trigram-counts (as dictionaries), that is the dictionary should have the format (lang1: tr1gram countsl, lang2: tr1gran counts2, ...] program.py > exampletset.csv 1 from collections 1mport defaultdict as dd 2 1mport csv 3 from h1dden_l1b 1mport count trigrams 4 from math 1mport sqrt 6 def normal1se(counts d1ct) normalise takes a d1ct1onary of tr1gram counts counts_dict and normal1ses 1t by 1t's length. " mag = sqrt(sun((x**2 for x 1n counts-d1ct.values()))) return dd (1nt, (key: value/mag for (key, value) 1n counts dict.tens) The file tra1ning set is of the following form: lang1,text1 lang2,text2 lang3,text3 1e 12 def tra1n class1fier (tra1ning set): 13 tra1n classifier takes a csv f1lename tra1ning set as a string and returns a dict1onary of average trigram-counts per language. r your code here pass noting that there may be more than one document per language 15 For an example, see example tset.csv, accessible as a tab at the top right. Note that the contents were taken from Wikipedia articles for the different languages. While the individual documents have been automatically stripped of a lot of the document markup, they still include some formating characters and other noise, which will form part of the trigram counts. Though we won't do anythingwith it here, dealing with this kind of 'noise' is an important part of the data wrangling step of data science. 16 We have provided a (hidden) implementation of the function count_trigrams (doc) from the previous question in h1dden_l1b. This function takes a document (a string) and returns a default dictionary of trigram-counts for the trigrams within the string Your code should behave as follows >>> d = tra1n-class1f1er( ' example-tset.csv ') > d.keys() dict_keys (['Indones1an' 'Icelandic', 'Engl1sh']) >>> type (dI Engl1sh']) class collections.defaultdict 0.05794400216170997 Your code will be tested on a hidden training set which is much much larger than the example set. It contains 3331 documents from Wikipedias of 74 different languages, Consequently, the hidden test case might take a while to run. Submissions Output




