

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Programming Activity 5 - Guidance ================================= General ------- Programmers must learn how to use frameworks. In this course, you are learning about the Textbook Collections
Programming Activity 5 - Guidance ================================= General ------- Programmers must learn how to use frameworks. In this course, you are learning about the Textbook Collections Framework. You will not have the luxery to change the framework in any way. You must learn to do what you need to do with what is provided. Sometimes, this takes ingenuity and trial and error. Make sure you use the provided input.txt starter file to test your code. It must be located in the same folder as your Python file. Compare your results carefully to the "Programming Activity 5 - Expected Output" document. You have 5 parts to complete. Each part requires writing the code for the body of a function. Do not add, change, or delete any code outside of these function bodies. Each function already has all the parameters you might need. Make use of these parameters as needed within the function body. You do not need to use the parameter "words" in your code. As described in the function comments, "words" is a list of words. Its words contain only lowercase letters and there is no punctuation. An iterator for this list, "wordsIter", is also passed to the functions. "wordsIter" would not make sense without describing what it iterates. Your code can make use of "wordsIter" to access the words list. However, you could access "words" directly in a "for" loop, if you want. Part 1 ------ Call first() to prime the list iterator. Use a while loop with a hasNext() condition to traverse the words list. In the while block: Use next() to get the next word. Use "word" as the name of the variable to store this word. Determine if this word is in the removals list. To do this, use: if (word in removals): If the word is in the removals list: Call remove() on the list iterator to remove it from the words list. Part 2 ------ Introduce a variable called previousWord and initialize it to an empty string. Call first() to prime the list iterator. Use a while loop with a hasNext() condition to traverse the words list. In the while block: Use next() to get the next word. If the word is equal to "first" or word is equal to "last", then update the value of previousWord to be the current word and use continue to keep looping. If the word is equal to the previous word, call remove() on the list iterator. Update the value of previousWord to be the current word. Part 3 ------ This is similar to part 1. Instead of the removals list, use the misspellings list. Instead of using remove(): Call insert() on the list iterator to insert the flag text. Then call next() on the list iterator to move past the flag. Part 4 ------ The strategy here is to iterate through the list to: Count the number of "first" words. Remove each of the "first" words as they are encountered. Then use the count to control another loop to: Insert new "first" words at the beginning of the list. For each one: Call first() to prime the list iterator. If there is a next word, call next() to establish the insertion point. Call insert() to insert a "first" word. Since part 4 is one of the more difficult parts, here is its solution as a free gift: # Part 4: # Move all occurrences of "first" to the front of the words list. # Input: # words - an ArrayList of words, no uppercase, no punctuation # wordsIter - a list iterator for the words list def moveFirstLit(words, wordsIter): countFirst = 0 wordsIter.first() while (wordsIter.hasNext()): word = wordsIter.next() if (word == FIRST): wordsIter.remove() countFirst += 1 for count in range(countFirst): wordsIter.first() if (wordsIter.hasNext()): wordsIter.next() wordsIter.insert(FIRST) Make sure you study this code line by line. Make sure you understand everything about how it works. The FIRST constant (a convenience variable), is setup near the top of the starter code. Part 5 ------ The strategy here is to iterate through the list to: Count the number of "last" words. Remove each of the "last" words as they are encountered. Then use the count to control another loop to: Insert new "last" words at the end of the list. For each one: Call last() to establish the insertion point. Call insert() to insert a "last" word.



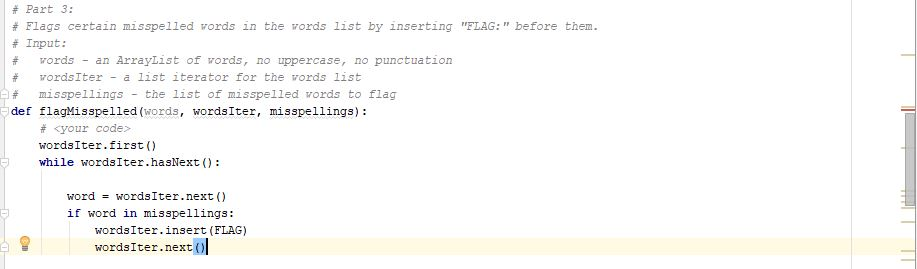


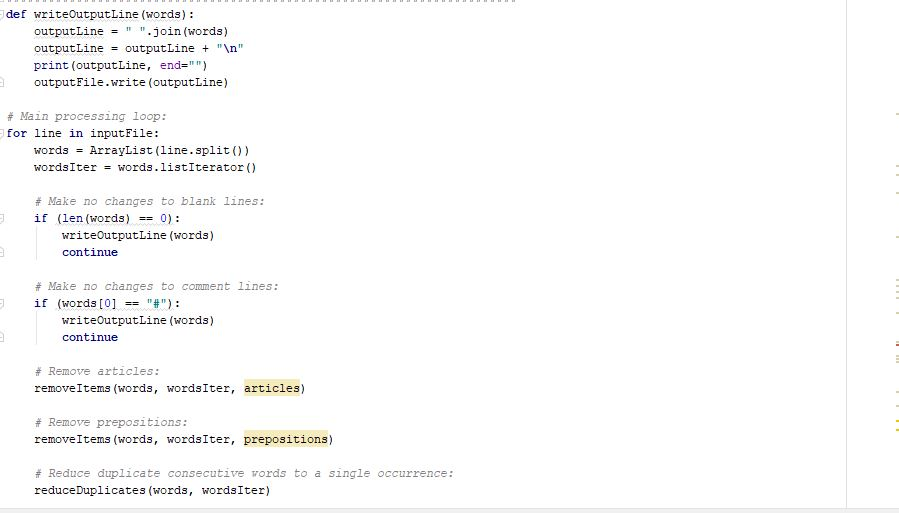

I completed part 1 part 3 and 4. I just need help with part 2 and 5. Please do not answer if you are not sure about the answer.
# This program exercises lists. | # The following files must be in the same folder: 3 4. 5 # abstractcollection.py |# abstractlist.py arraylist.py arrays.py 8 linkedlist.py node.py 10 # input.txt - the input text file. | # Input: input.txt 12 13 14 15 This file must be in the same folder. f To keep things simple: This file contains no punctuation | # This file contains only lovercase characters. | # Output: output.txt 16 17 18 19 20 21 f This file will be created in the same folder. # All articles are removed. Certain prepositions are removed Duplicate consecutive words are reduced to a single occurrence. # # Note: The vords "first" and "last" are not reduced. 23 24 | # certain misspelled words are flagged. occurrences of "first" are moved to the front of a line. # ipi # occurrences of "last" are moved to the end of a line. 25 26 27 import 29 30 31 | # Data: # This program exercises lists. | # The following files must be in the same folder: 3 4. 5 # abstractcollection.py |# abstractlist.py arraylist.py arrays.py 8 linkedlist.py node.py 10 # input.txt - the input text file. | # Input: input.txt 12 13 14 15 This file must be in the same folder. f To keep things simple: This file contains no punctuation | # This file contains only lovercase characters. | # Output: output.txt 16 17 18 19 20 21 f This file will be created in the same folder. # All articles are removed. Certain prepositions are removed Duplicate consecutive words are reduced to a single occurrence. # # Note: The vords "first" and "last" are not reduced. 23 24 | # certain misspelled words are flagged. occurrences of "first" are moved to the front of a line. # ipi # occurrences of "last" are moved to the end of a line. 25 26 27 import 29 30 31 | # DataStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
The World Wide Web And Databases International Workshop Webdb 98 Valencia Spain March 27 28 1998 Selected Papers Lncs 1590
Authors: Paolo Atzeni ,Alberto Mendelzon ,Giansalvatore Mecca
1st Edition
3540658904, 978-3540658900