

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Python 3 code. Please Problem program-py> plotter.py lndonesian1.txt English1txt eArabic1.txt eGerman1txt Polish!txt 1 from plotter import plot_scores 2 from hidden_lib import train_classifier 3 from hidden_lib
Python 3 code. Please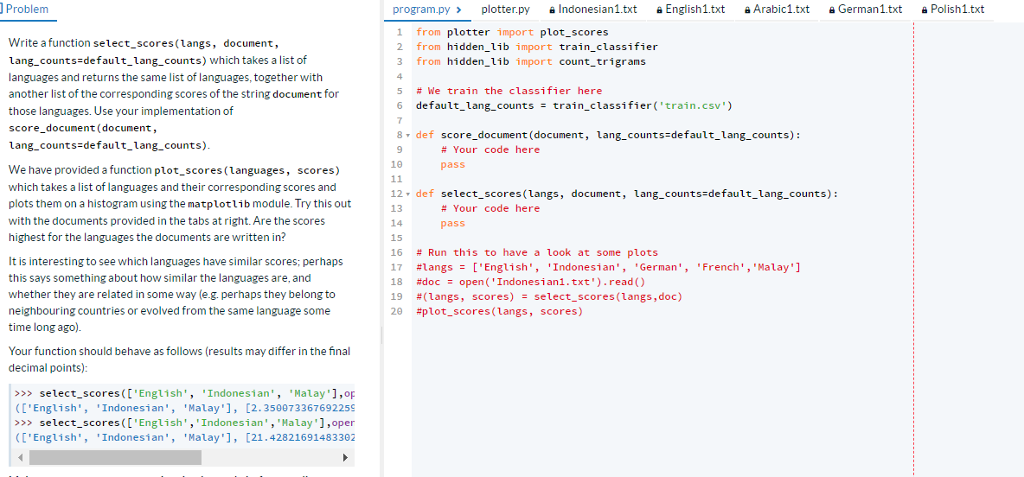
Problem program-py> plotter.py lndonesian1.txt English1txt eArabic1.txt eGerman1txt Polish!txt 1 from plotter import plot_scores 2 from hidden_lib import train_classifier 3 from hidden_lib import count trigrams Write a function select scores (langs, document, Lang_counts default_lang_counts) which takes a list of languages and returns the same list of languages, together with another list of the corresponding scores of the string document for those languages. Use your implementation of score document (docunent, lang_counts-default_lang_counts) 5 # We train the classifier here 6 default-lang-counts train-classifier ( 'train.csv.) = 8 def score_document (document, lang_counts default_lang_counts): # Your code here pass We have provided a function plot_scores(languages, scores) which takes a list of languages and their corresponding scores and plots them on a histogram using the matplotlib module. Try this out with the documents provided in the tabs at right. Are the scores highest for the languages the documents are written in? 12- def select_scores (langs, document, lang_counts default_lang_counts): 13 14 15 16 # Run this to have a look at some plots 17 #langs= ['English', 'Indonesian, 'German', 'French','Malay'] 18 #doc open ( ' Indonesian 1 . txt' ) . read ( ) 19 #(langs, scores) = select-scores(langs,doc) 29 #plot-scores(langs, scores) # Your code here pass It is interesting to see which languages have similar scores perhaps this says something about how similar the languages are, and whether they are related in some way (e.g. perhaps they belong to neighbouring countries or evolved from the same language some time long ago). Your function should behave as follows (results may differ in the final decimal points): >>> select scores (['English', 'Indonesian','Malay'1,op (['English' 'Indonesian' 'Malay'], [2.350973367692259 >>>select scores(['English', 'Indonesian', 'Halay'],oper C'English 'Indonesian''Malay'1, [21.42821691483302 Problem program-py> plotter.py lndonesian1.txt English1txt eArabic1.txt eGerman1txt Polish!txt 1 from plotter import plot_scores 2 from hidden_lib import train_classifier 3 from hidden_lib import count trigrams Write a function select scores (langs, document, Lang_counts default_lang_counts) which takes a list of languages and returns the same list of languages, together with another list of the corresponding scores of the string document for those languages. Use your implementation of score document (docunent, lang_counts-default_lang_counts) 5 # We train the classifier here 6 default-lang-counts train-classifier ( 'train.csv.) = 8 def score_document (document, lang_counts default_lang_counts): # Your code here pass We have provided a function plot_scores(languages, scores) which takes a list of languages and their corresponding scores and plots them on a histogram using the matplotlib module. Try this out with the documents provided in the tabs at right. Are the scores highest for the languages the documents are written in? 12- def select_scores (langs, document, lang_counts default_lang_counts): 13 14 15 16 # Run this to have a look at some plots 17 #langs= ['English', 'Indonesian, 'German', 'French','Malay'] 18 #doc open ( ' Indonesian 1 . txt' ) . read ( ) 19 #(langs, scores) = select-scores(langs,doc) 29 #plot-scores(langs, scores) # Your code here pass It is interesting to see which languages have similar scores perhaps this says something about how similar the languages are, and whether they are related in some way (e.g. perhaps they belong to neighbouring countries or evolved from the same language some time long ago). Your function should behave as follows (results may differ in the final decimal points): >>> select scores (['English', 'Indonesian','Malay'1,op (['English' 'Indonesian' 'Malay'], [2.350973367692259 >>>select scores(['English', 'Indonesian', 'Halay'],oper C'English 'Indonesian''Malay'1, [21.42821691483302
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Inductive Databases And Constraint Based Data Mining
Authors: Saso Dzeroski ,Bart Goethals ,Pance Panov
2010th Edition
1489982175, 978-1489982179