Python 3 code. Please.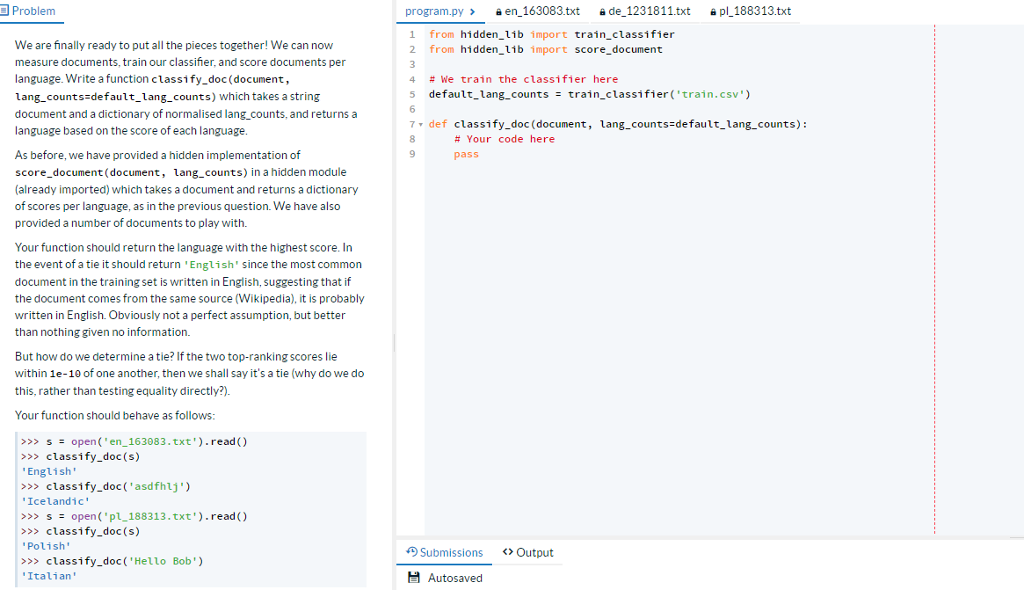
Problem program.pyen 163083.txt ade 1231811.txt a pl188313.txt 1 from hidden lib import train classifier We are finally ready to put all the pieces together! We can now measure documents, train our classifier, and score documents per language. Write a function classify_doc(document, lang_counts default_lang_counts) which takes a string document and a dictionary of normalised lang counts, and returns a language based on the score ofeach language 2 from hidden_lib import score document 4 # le train the classifier here 5 default-lang-counts= train-classifier('train.csv.) 6 7 def classifydoc (document, lang_counts-default lang_counts): # Your code here As before, we have provided a hidden implementation of score_document (document, lang counts) in a hidden module (already imported) which takes a document and returns a dictionary of scores per language, as in the previous question. We have also provided a number of documents to play with. pass Your function should return the language with the highest score. In the event of a tie it should return 'English' since the most common document in the training set is written in English, suggesting that if the document comes from the same source (Wikipedia), it is probably written in English. Obviously not a perfect assumption, but better than nothing given no information. But how do we determine a tie? If the two top-ranking scores lie within 1e-10 of one another, then we shall say it's a tie (why do we do this, rather than testing equality directly?). Your function should behave as follows sopen('en_163083.txt).read() >>> classify_doc(s) English' >>> classify_doc('asdfhlj') Icelandic' >>> s = open(.p1_188313.txt').read() >>> classify doc (s) Polish >>>classify_doc( 'Hello Bob) Italian' Submissions Output Autosaved Problem program.pyen 163083.txt ade 1231811.txt a pl188313.txt 1 from hidden lib import train classifier We are finally ready to put all the pieces together! We can now measure documents, train our classifier, and score documents per language. Write a function classify_doc(document, lang_counts default_lang_counts) which takes a string document and a dictionary of normalised lang counts, and returns a language based on the score ofeach language 2 from hidden_lib import score document 4 # le train the classifier here 5 default-lang-counts= train-classifier('train.csv.) 6 7 def classifydoc (document, lang_counts-default lang_counts): # Your code here As before, we have provided a hidden implementation of score_document (document, lang counts) in a hidden module (already imported) which takes a document and returns a dictionary of scores per language, as in the previous question. We have also provided a number of documents to play with. pass Your function should return the language with the highest score. In the event of a tie it should return 'English' since the most common document in the training set is written in English, suggesting that if the document comes from the same source (Wikipedia), it is probably written in English. Obviously not a perfect assumption, but better than nothing given no information. But how do we determine a tie? If the two top-ranking scores lie within 1e-10 of one another, then we shall say it's a tie (why do we do this, rather than testing equality directly?). Your function should behave as follows sopen('en_163083.txt).read() >>> classify_doc(s) English' >>> classify_doc('asdfhlj') Icelandic' >>> s = open(.p1_188313.txt').read() >>> classify doc (s) Polish >>>classify_doc( 'Hello Bob) Italian' Submissions Output Autosaved




