

Question: Python and most Python libraries are free to download or use, though many users use Python through a paid service. Paid services help IT organizations
Python and most Python libraries are free to download or use, though many users use Python through a paid service. Paid services help IT organizations manage the risks associated with the use of open-source software, such as security, licensing, and access control. . [4 marks] (e) How might the sentence in Part (a)(ii) be altered so that it has the same meaning but is easier to process? Explain your reasoning. Experiment with a compression utility (e.g., compress, gzip, or pkzip). What compression ratios are you able to achieve? See if you can generate data files for which
you can achieve 5:1 or 10:1 compression ratios.
18 Suppose a file contains the letters a, b, c, and d. Nominally, we require 2 bits per
letter to store such a file.
(b) What is the percentage of compression you achieve above? (This is the average of the compression percentages achieved for each letter, weighted by the
letter's frequency.)
(c) Repeat this, assuming a and b each occur 40% of the time, c occurs 15% of
the time, and d occurs 5% of the time.. [2 marks] (iii) Priority reversal can likewise emerge between two strings associated with process synchronization - for instance, when one string utilizes a semaphore to flag finishing of work. For what reason could carrying out need reversal be more troublesome with process synchronization than with shared rejection? [4 marks] (iv) What might we at some point do to tackle the issue in (b)(iii)? [4 marks] 8 CST.2013.5.9 8 Concurrent and Distributed Systems Analyze the activity of every choice and legitimize a determination that gives the best granularity of command over burden to the substance servers and a choice that will serve every client from the nearest CDN server. [12 marks] (c) You have looked into the IP address of your number one internet searcher on the University organization and saw the response is not quite the same as that given to your companion when he did the query in Newfoundland, Canada. Faor every choice above, show why it may, or could not, be utilized by your number one internet searcher to further develop website page execution. [4 marks] 6 CST.2013.5.7 6 Computer Networking (a) Considering either TCP/IP or UDP/IP, compose a depiction of how server-port, client-port, source-port and objective port connect with one another. You might wish to give models and use graphs as fitting. [4 marks] (b) What is a directing circle? Remember a chart for your response. [4 marks] (c) Describe an instrument that forestalls directing circles in Ethernet organizations. [4 marks] (d) (I) Describe and, with the guide of a model, represent the IP Time-To-Live (TTL) instrument for limiting the effect of steering circles. [2 marks] (ii) Assuming, to some degree (d)(i), an ideal execution, portray an impediment of the methodology including the side effects that may be knowledgeable about an organization subject to this burden, and a test that might distinguish the issue. [2 marks] (e) Explain the specialized and compositional contention behind the choice in IPv6 to hold header TTL however not a header checksum. [2 marks] (f ) Explain why there is uncertainty about taking care of parcels with TTL upsides of 1 and give a useful arrangement. [2 marks] 7 (TURN OVER) CST.2013.5.8 7 Concurrent and Distributed Systems (a) Deadlock is an exemplary issue in simultaneous frameworks. (I) What are the four essential circumstances for stop? [4 marks] (ii) Deadlock is many times made sense of utilizing the Dining Philosopher's Problem. In this pseudo-code, each fork is addressed by a lock: Lock forks[] = new Lock[5];//Code for every scholar (I) while (valid) { think(); lock(fork[i]); lock(fork[(i + 1) % 5]); eat(); unlock(fork[i]); unlock(fork[(i + 1) % 5]); } Partial requesting is a typical halt anticipation plot. Depict adjustments to the above code, changing just exhibit files, with the end goal that rationalists can be taken care of securely, yet in addition halt free, utilizing a halfway request. Portray a calculation that draws the quadratic Be'zier bend, utilizing straight
lines just, to inside a resistance τ . You might utilize the calculation from section (a)
also, you might accept that you as of now have a calculation for drawing a straight
line. [8 marks]
(c) Consider the control of detail in a bend that is addressed by a grouping of
many straight line portions. Portray how Douglas and P¨ucdker's calculation
can be utilized to eliminate unnecessary focuses. You might utilize the calculation from
section (a).
(a) Consider a straightforward arbitrary walk, Sn, characterized by S0 = an and Sn = Sn−1 + Xn
for n ≥ 1 where the arbitrary factors Xi (I = 1, 2, . . .) are autonomous and
indistinguishably circulated with P(Xi = 1) = p and P(Xi = −1) = 1 − p for some
consistent p with 0 ≤ p ≤ 1.
(I) Find E(Sn) and Var (Sn) as far as a, n and p. [4 marks]
(ii) Use as far as possible hypothesis to infer an inexact articulation
for P(Sn > k) for huge n. You might leave your response communicated in wording
of the conveyance work Φ(x) = P(Z ≤ x) where Z is a norm
Ordinary arbitrary variable with zero mean and unit difference. [6 marks]
(b) Consider the Gambler's ruin issue characterized as partially (a) however with the
expansion of engrossing obstructions at 0 and N where N is some sure whole number.
Determine an articulation for the likelihood of ruin (that is, being assimilated at the
zero obstruction) while beginning at position S0 = a for each a = 0, 1, . . . , N in the
t
2
5 Logic and Proof
(a) State (with legitimization) whether the accompanying recipe is satisfiable, legitimate or
not one or the other. Note that an and b are constants.
h
∀x [q(x) → r(x)] ∧ ¬r(a) ∧ ∀x [¬r(x) ∧ ¬q(a) → p(x) ∨ q(x)]i
→ p(b) ∨ r(b)
(b) Attempt to demonstrate the recipe [∃x ∀y R(x, y)] → ∃x ∀z R(x, f(z)) by goal,
with brief clarifications of each progression, including the change to statement structure.
[4 marks]
(c) Give a model for the accompanying arrangement of provisos, or demonstrate that none exists.
{¬R(x, y), ¬R(y, x)}
{R(x, f(x))}
{¬R(x, y), ¬R(y, z), R(x, z)}
The Prolog predicate perm(+In,- Out) creates all stages of the info list
In. A developer carries out perm/2 as follows:
perm([],[]).
perm(L,[H|T]) :- take(L,H,R), perm(R,T).
The predicate take(+L,- E,- R) eliminates one component (E) from the info list L and
brings together R with the rest of L. In this manner, the rundown R has one component less than L.
(a) Consider the perm/2 predicate:
(I) Explain momentarily in words the activity of the perm/2 predicate.
(ii) Provide an execution of the take/3 predicate.
(iii) Give the total grouping of replies (properly aligned)
by perm([1,2,3],A).
(b) An understudy endeavors to summon the inquiry perm(A,[1,2,3]).
(I) Explain what occurs and why. [5 marks]
(ii) Implement a predicate sameLength/2 which is valid if the two boundaries
are arrangements of a similar length.
(iii) Using sameLength/2, etc., give an execution of
safePerm/2 which creates stages no matter what the request in
which the boundaries are given: both safePerm(+In,- Out) and
safePerm(- Out,+In) ought to create all changes of In. The request
in which these changes are created isn't significant.
[4 marks] (b) (a) The ACID properties are frequently used to characterize conditional semantics. (I) Define "atomicity" as utilized in the ACID setting. [1 mark] (ii) Define "solidness" as utilized in the ACID setting. [1 mark] (b) Write-ahead logging is a normally utilized plan to achieve value-based semantics while putting away a data set on a square stockpiling gadget, like a hard circle. (I) Under what conditions, during compose ahead log recuperation, might an exchange in the UNDO at any point list be moved to the REDO list? [2 marks] (ii) Synchronously flushing commit records to circle is costly. How might we securely lessen coordinated I/O procedure on a high-throughput framework without forfeiting ACID properties? [2 marks] (iii) Describe two execution changes that could emerge from utilizing your answer for part (b)(ii). [2 marks] (c) (I) Transaction records in a compose ahead logging plan contain five fields: hTransactionID, ObjID, Operation, OldValue, NewValuei, yet putting away the total old and new qualities can consume critical measures of room. One methodology that may be utilized, for reversible activities being applied to certain information like XOR by a consistent, is to store just the steady contentions, instead of the full when information. What issues could happen because of this plan decision? [4 marks] (ii) Write-ahead logging frameworks should know the genuine on-circle area size for the compose ahead log to accurately act. A wayward circle seller chooses to rebrand its 512-byte area plates as 2K-area plates, and changes the worth announced back to the information base framework. How should this influence information base trustworthiness? [4 marks] (iii) Explain how an information base merchant who knows about the issue portrayed to some degree (c)(ii) alleviate this issue in programming, and what restrictions could there be to this methodology. [4 marks] 9 (TURN OVER) CST.2013.5.10 9 Concurrent and Distributed Systems Sun's Network File System (NFS) is the standard dispersed document framework utilized with UNIX, and has gone through a movement of adaptations (2, 3, 4) that have step by step better execution and semantics. (a) Remote strategy call (RPC) (I) Explain how Sun RPC handle byte request (endianness). [2 marks] (ii) This approach might bring about pointless work. State when this happens and how should this be kept away from. [2 marks] (b) Network File System adaptation 2 (NFSv2) and variant 3 (NFSv3) (I) A key plan premise for NFS was that the server be "stateless" as for the client. State how this affects disseminated record securing in NFSv2 and NFSv3. [2 marks] (ii) Another key plan premise for NFSv2 was the "idempotence" of RPCs; what's the significance here? [2 marks] (iii) One critical improvement in NFSv3 was the expansion of the READDIRPLUS RPC. Make sense of for what reason did this helps execution. [4 marks] (iv) NFSv3 executes what is named "near open consistency" for record information reserving: assuming client C1 keeps in touch with a document, shuts the document, and client C2 currently opens the document for read, then it should see the consequences of all composes gave by C1 before close. Be that as it may, in the event that C2 opens the record before C1 has shut it, C2 might see some, all, or none of the composes gave by C1 (and in inconsistent request). Near open consistency is accomplished through cautious utilization of coordinated RPC semantics, joined with document timestamp data piggybacked onto server answers on all RPCs that work on records. Make sense of how near open consistency permits execution to be gotten to the next level. [4 marks] (v) NFSv3 adds another RPC, ACCESS, permitting the client to appoint access control checks at document open opportunity to the server, as opposed to performing them on the client. This permits client and server security models to contrast
4 Using library functions like htonl and Unix's bcopy or Windows' CopyMemory,
implement a routine that generates the same on-the-wire representation of the
structures given in Exercise 1 as XDR does. If possible, compare the performance
of your "by-hand" encoder/decoder with the corresponding XDR routines.
5 Use XDR and htonl to encode a 1000-element array of integers. Measure and
compare the performance of each. How do these compare to a simple loop that
reads and writes a 1000-element array of integers? Perform the experiment on a
computer for which the native byte order is the same as the network byte order,
as well as on a computer for which the native byte order and the network byte
order are different.
6 Write your own implementation of htonl. Using both your own htonl and (if
little-endian hardware is available) the standard library version, run appropriate
experiments to determine how much longer it takes to byte-swap integers versus
merely copying them.
572 7 End-to-End Data
7 Give the ASN.1 encoding for the following three integers. Note that ASN.1 integers, like those in XDR, are 32 bits in length.
(a) 101
(b) 10,120
(c) 16,909,060
8 Give the ASN.1 encoding for the following three integers. Note that ASN.1 integers, like those in XDR, are 32 bits in length.
(a) 15
(b) 29,496,729
(c) 58,993,458
9 Give the big-endian and little-endian representation for the integers from
Exercise 7.
10 Give the big-endian and little-endian representation for the integers from
Exercise 8.
11 XDR is used to encode/decode the header for the SunRPC protocol illustrated
by Figure 5.20. The XDR version is determined by the RPCVersion field. What
potential difficulty does this present? Would it be possible for a new version of
XDR to switch to little-endian integer format?
12 The presentation formatting process is sometimes regarded as an autonomous
protocol layer, separate from the application. If this is so, why might including
data compression in the presentation layer be a bad idea?
13 Suppose you have a machine with a 36-bit word size. Strings are represented as
five packed 7-bit characters per word. What presentation issues on this machine
have to be addressed for it to exchange integer and string data with the rest of the
world?
14 Using the programming language of your choice that supports user-defined automatic type conversions, define a type netint and supply conversions that enable assignments and equality comparisons between ints and netints. Can a generalization of this approach solve the problem of network argument
marshalling?
Exercises 573
15 Different architectures have different conventions on bit order as well as byte
order—whether the least significant bit of a byte, for example, is bit 0 or bit 7.
[Pos81] defines (in its Appendix B) the standard network bit order. Why is bit
order then not relevant to presentation formatting?
16 Let p ≤ 1 be the fraction of machines in a network that are big-endian; the remaining 1 − p fraction are little-endian. Suppose we choose two machines at random
and send an int from one to the other. Give the average number of byte-order conversions needed for both big-endian network byte order and receiver-makes-right,
for p = 0.1, p = 0.5, and p = 0.9. Hint: The probability that both endpoints are
big-endian is p
2
; the probability that the two endpoints use different byte orders
is
19 Suppose we have a compression function c, which takes a bit string s to a compressed string c(s).
(a) Show that for any integer N there must be a string s of length N for which
length(c(s)) ≥ N; that is, no effective compression is done.
(b) Compress some already compressed files (try compressing with the same utility
several times in sequence). What happens to the file size?
(c) Given a compression function c as in (a), give a function c
′
such that for all bit
strings s, length(c
′Each pair of Rockwell surfboards requires 3 labor hours in the fabrication department and 1.5
labor hours in finishing. The Limestone model requires 4.5 labor-hours in fabrication and 2 labor-hours in finishing. The
company operates 6 days a week. It makes a per-unit profit of $60 on the Rockwell model and $75 on the Limestone
model. Approximately 4.1 Rockwell models and 8.4 Limestone models are produced per day.Networking is not simply an information exchange between you and another person. It involves establishing relationships with people who will often become your friends and community of colleagues as you go through your career. They may be able to help you advance your career in many ways, just as you may be able to help them advance theirs. A networking contact might result in any of the following:
Inside information on what's happening in your field of interest, such as an organization's plan to expand operations or release a new product.
Job search advice specific to your field of interest, like where jobs are typically listed.
Tips on your job hunting tools (i.e. resume and/or portfolio).
Names of people to contact about possible employment or informational interviews.
Follow-up interview and possible job offer.
Developing your network is easy because you know more people than you think you know. Consider:
family, friends, roommates, and significant others
iSchool faculty and staff, fellow students, and alumni
past and present co-workers
neighbors
club, organization, and association members
people at the gym, the local coffee house, and neighborhood store
people in your religious community
These people are all part of your current network, professional and personal. Keep an on-going list of the names and contact information of the people in your network. Ask your contacts to introduce you to their contacts and keep your list growing (don't forget to offer to reciprocate!). Opportunities to network with people arise at any time and any place. Never underestimate an opportunity to make a connecti
There are many different programming languages for various applications, such as data science, machine learning, signal processing, numerical optimization, and web development. Therefore, it is essential to know how to decide which programming language is more suitable for your application.
In this article, I will discuss the advantages and disadvantages of using Python, R, and Matlab. I will explain when and for what applications these programming languages are more suitable. I organize the outline based on popular research and work done extensively in the real-world.Generic programming tasks are problems that are not specific to any application. For example, reading and saving data to a file, preprocessing CSV or text file, writing scripts or functions for basic problems like counting the number of occurrences of an event, plotting data, performing basic statistical tasks such as computing the mean, median, standard deviation, etc.
For these problems, either Python, R, or Matlab can be used with no problem. Python and Matlab are relatively comparable in speed, depending on how you write your code and how many built-in functions you are using, Matlab may or may not be faster than Python. They are both faster than R. To learn more about these comparisons please look at the following links.Matlab, R, and Python all have very strong visualizations and plotting capabilities. R thanks to ggplot2 package and Python thanks to numerous packages such as matplotlib, seaborn, ggplot, and bokeh produce stunning looking graphs. Matlab provides inherent support for matrix and vector manipulation while Python has better support for saving, reading, and performing various operations on CSV and text data, thanks to the Pandas library. To see comparisons in terms of other criteria such as ease of use, installation, speed, and support community.This is the area where Python and R have a clear advantage over Matlab. They both have access to numerous libraries and packages for both classical (random forest, regression, SVM, etc.) and modern (deep learning and neural networks such as CNN, RNN, etc.) machine learning models. However, Python is the most widely used language for modern machine learning research in industry and academia. It is the number one language for natural language processing (NLP), computer vision (CV), and reinforcement learning, thanks to many available packages such as NLTK, OpenCV, OpenAI Gym, etc.
Python is also the number one language for most research or work involving neural networks and deep learning, thanks to many available libraries and platforms such as Tensorflow, Pytorch, Keras Probabilistic graphical models are a class of models for inference and learning on graphs. They are divided into undirected graphical models or sometimes referred to as Markov random field and directed graphical models or Bayesian network.
Python, R, and Matlab all have support for PGM. However, Python and R are outperforming Matlab in this area. Matlab, thanks to the BNT (Bayesian Network Toolbox) by Kevin Murphy, has support for the static and dynamic Bayesian network. The Matlab standard library (hmmtrain) supports the discrete hidden Markov model (HMM), a well-known class of dynamic Bayesian networks. Matlab also supports the conditional random field Python has excellent support for PGM thanks to hmmlearn (Full support for discrete and continuous HMM), pomegranate, bnlearn (a wrapper around the bnlearn in R), pypmc, bayespy, pgmpy, etc. It also has better support for CRF through sklearn-crfsuite.
R has excellent support for PGM (both in the structure learning discussed in the next section and parameter learning and inference). It has numerous stunning packages and libraries such as bnlearn, bnstruct, depmixS4, etc. The support for CRF is done through the CRF and crfsuite packages.R by far is the most widely used language in causal inference research (along with SAS and STATA; however, R is free while the other two are not). It has numerous libraries such as bnlearn, bnstruct for causal discovery (structure learning) to learn the DAG (directed acyclic graph) from data. It has libraries and functions for various techniques such as outcome regression, IPTW, g-estimation, etc.
Python also, thanks to the dowhy package by Microsoft research, is capable of combining the Pearl causal network framework with the Rubin potential outcome model and provides an easy interface for causal inference modeling.R is also the strongest and by far the most widely used language for time series analysis and forecasting. Numerous books have been written about time series forecasting using R. There are many libraries to implement algorithms such as ARIMA, Holt-Winters, exponential smoothing. For example, the forecast package by Rob Hyndman is the most used package for time series forecasting.
Python, thanks to neural networks, especially the LSTM, receives lots of attention in time series forecasting ¹. Furthermore, the Prophet package by Facebook written in both R and Python provides excellent and automated support for time series analysis and forecasting.This is the area where Matlab is the strongest and is used often in research and industry. Matlab communications toolbox provides all functionalities needed to implement a complete communication system. It has functionalities to implement all well-known modulation schemes, channel and source coding, equalizer, and necessary decoding and detection algorithms in the receiver. The DSP system toolbox provides all functionalities to design IIR (Infinite Impulse Response), FIR (Finite Impulse Response), and adaptive filters. It has complete support for FFT (Fast Fourier Transform), IFFT, wavelet, etc.
programming (LP), mixed-integer linear programming (MILP), quadratic programming (QP), second-order cone programming (SOCP), nonlinear programming (NLP), constrained linear least squares, nonlinear least squares, nonlinear equations, etc. CVX is another strong package in Matlab written by Stephen Boys and his Ph.D. student for convex optimization.
Python supports optimization through various packages such as CVXOPT, pyOpt (Nonlinear optimization), PuLP(Linear Programming), and CVXPY (python version of CVX for convex optimization problems).
R supports convex optimization through CVXR (Similar to CVX and CVXPY), optimx (quasi-Newton and conjugate gradient method), and ROI (linear, quadratic, and conic optimization problems).
Web Development
This is an area where Python outperforms R and Matlab by a large margin. Actually, neither R nor Matlab are used for any web development design.
Python, thanks to Django and Flask, is a compelling language for backend development. Many existing websites, such as Google, Pinterest, and Instagram, use Python as part of their backend development.
Matlab
Advantage:
Many wonderful libraries and the number one choice in signal processing, communication system, and control theory.
Simulink: One of the best toolboxes in MATLAB is used extensively in control and dynamical system applications.
Lots of available and robust packages for optimization, control, and numerical analysis.
Nice toolbox for graphical work (Lets you plot beautiful looking graphs) and inherent support for matrix and vector manipulation.
Easy to learn and has a user-friendly interface.
Disadvantage:
Proprietary and not free or open-source, which makes it very hard for collaboration.
Lack of good packages and libraries for machine learning, AI, time series analysis, and causal inference.
Limited in terms of functionality: cannot be used for web development and app design.
Not object-oriented language.
Smaller user community compared to Python.
Python
Advantage:
Many wonderful libraries in machine learning, AI, web development, and optimization.
Number one language for deep learning and machine learning in general.
Open-source and free.
A large community of users across GitHub, Stackoverflow, and ...
It can be used for other applications besides engineering, unlike MATLAB. For example, GUI (Graphical User Interface) development using Tkinter and PyQt.
Object-oriented language.
Easy to learn and user-friendly syntax.
Disadvantage:
Lack of good packages for signal processing and communication (still behind for engineering applications).
Steeper learning curve than MATLAB since it is an object-oriented programming(OOP) language and is harder to master.
Requires more time and expertise to setup and install the working environment.
Advantage:
So many wonderful libraries in statistics and machine learning.
Open-source and free.
Number one language for time series analysis, causal inference, and PGM.
A large community of researchers, especially in academia.
Ability to create web applications, for example, through the Shiney app.
Disadvantage:
Slower compared to Python and Matlab.
More limited scope in terms of applications compared to Python. (Cannot be used for game development or cannot be as a backend for web developments)
Not object-oriented language.
Lack of good packages for signal processing and communication (still behind for engineering applications).
Smaller user communities compared to Python.
Harder and not user-friendly compared to Python and Matlab.
To summarize, Python is the most popular language for machine learning, AI, and web development while it provides excellent support for PGM and optimization. On the other hand, Matlab is a clear winner for engineering applications while it has lots of good libraries for numerical analysis and optimization. The biggest disadvantage of Matlab is that it is not free or open-source. R is a clear winner for time series analysis, causal inference, and PGM. It also has excellent support for machine learning and data science applications.
Python, although is not as capable as Matlab in this area but has support for digital communication algorithms through CommPy and Komm packages.Matlab is still the most widely used language for implementing the control and dynamical system algorithms thanks to the control system toolbox. It has extensive supports for all well-known methods such as PID controller, state-space design, root locus, transfer function, pole-zero diagrams, Kalman Filter, and many more. However, the main strength of Matlab is coming from its excellent and versatile graphical editor Simulink. Simulink lets you simulate the real-world system using drag and drop blocks (It is similar to the LabView). The Simulink output can then be imported to Matlab for further analysis.
Python has support for control and dynamical system through the control and dynamical systems library.
Optimization and Numerical Analysis
All three programming languages have excellent support for optimization problems such as linear programming (LP), convex optimization, nonlinear optimization with and without constraint.
The support for optimization and numerical analysis in Matlab is done through the optimization toolbox. This supports linear
If we get the pivot 'just right' (e.g., choosing 5 in the above example), then the split will be as even as possible. Unfortunately, there is no quick guaranteed way of finding the optimal pivot. If the keys are integers, one could take the average value of all the keys, but that requires visiting all the entries to sample their key, adding considerable overhead to the algorithm, and if the keys are more complicated, such as strings, you cannot do this at all. More importantly, it would not necessarily give a pivot that is a value in the array. Some sensible heuristic pivot choice strategies are: • Use a random number generator to produce an index k and then use a[k]. • Take a key from 'the middle' of the array, that is a[(n-1)/2]. • Take a small sample (e.g., 3 or 5 items) and take the 'middle' key of those. Note that one should never simply choose the first or last key in the array as the pivot, because if the array is almost sorted already, that will lead to the particularly bad choice mentioned above, and this situation is actually quite common in practice. Since there are so many reasonable possibilities, and they are all fairly straightforward, we will not give a specific implementation for any of these pivot choosing strategies, but just assume that we have a choosePivot(a,left,right) procedure that returns the index of the pivot for a particular sub-array (rather than the pivot value itself). The partitioning. In order to carry out the partitioning within the given array, some thought is required as to how this may be best achieved. This is more easily demonstrated by an example than put into words. For a change, we will consider an array of strings, namely the programming languages: [c, fortran, java, ada, pascal, basic, haskell, ocaml]. The ordering we choose is the standard lexicographic one, and let the chosen pivot be "fortran". We will use markers | to denote a partition of the array. To the left of the left marker, there will be items we know to have a key smaller than or equal to the pivot. To the right of the right marker, there will be items we know to have a key bigger than or equal to the pivot. In the middle, there will be the items we have not yet considered. Note that this algorithm proceeds to investigate the items in the array from two sides. We begin by swapping the pivot value to the end of the array where it can easily be kept separate from the sub-array creation process, so we have the array: [|c, ocaml, java, ada, pascal, basic, haskell | fortran]. Starting from the left, we find "c" is less than "fortran", so we move the left marker one step to the right to give [c | ocaml, java, ada, pascal, basic, haskell | fortran]. Now "ocaml" is greater than "fortran", so we stop on the left and proceed from the right instead, without moving the left marker. We then find "haskell" is bigger than "fortran", so we move the right marker to the left by one, giving [c | ocaml, java, ada, pascal, basic, | haskell, fortran]. Now "basic" is smaller than "fortran", so we have two keys, "ocaml" and "basic", which are 'on the wrong side'. We therefore swap them, which allows us to move both the left and the right marker one step further towards the middle. This brings us to [c, basic | java, ada, pascal | ocaml, haskell, fortran]. Now we proceed from the left once again, but "java" is bigger than "fortran", so we stop there and switch to the right. Then "pascal" is bigger than "fortran", so we move the right marker again. We then find "ada", which is smaller than the pivot, so we stop. We have now got [c, basic | java, ada, | pascal, ocaml, haskell, fortran]. As before, we want to swap "java" and "ada", which leaves the left and the right markers in the same place: [c, basic, ada, java | | pascal, ocaml, haskell, fortran], so we 76 stop. Finally, we swap the pivot back from the last position into the position immediately after the markers to give [c, basic, ada, java | | fortran, ocaml, haskell, pascal]. Since we obviously cannot have the marker indices 'between' array entries, we will assume the left marker is on the left of a[leftmark] and the right marker is to the right of a[rightmark]. The markers are therefore 'in the same place' once rightmark becomes smaller than leftmark, which is when we stop. If we assume that the keys are integers, we can write the partitioning procedure, that needs to return the final pivot position, as: partition(array a, int left, int right) { pivotindex = choosePivot(a, left, right) pivot = a[pivotindex] swap a[pivotindex] and a[right] leftmark = left rightmark = right - 1 while (leftmark = pivot) rightmark-- if (leftmark mid ) while ( rcount What Is Python?
Python is a general-purpose programming language with an extensive collection of libraries that are used for a wide range of applications, including web development, enterprise application development, and data science.
What Is MATLAB?
MATLAB is a computing platform that is used for engineering and scientific applications like data analysis, signal and image processing, control systems, wireless communications, and robotics. MATLAB includes a programming language, interactive apps, highly specialized libraries for engineering applications, and tools for automatically generating embedded code. MATLAB is also the foundation for Simulink, a block diagram environment for simulating complex multi-domain systems.
Language Comparison
The language of Python and MATLAB can be used interactively (a single command at a time) or to develop large-scale applications. Both languages support scripting, procedural and object-oriented programming.
Python has largely replaced Java as the first language for people who want to learn how to program because it is easy to learn and can be used for various programming tasks. MATLAB language is the first (and often only) programming language for many engineers and scientists because the matrix math and array orientation of the language makes it easy to learn and apply to engineering and scientific problem-solving. Apps and other interactive tools automatically generate MATLAB code, further reducing the barrier to entry.
User Base
Both Python and MATLAB have large user bases, though the user base for MATLAB is primarily comprised of engineers and scientists. As of May 2022, LinkedIn searches return about 7.6 million Python users and 4.1 million MATLAB users. People who do not work in engineering or science are often surprised to learn how widespread MATLAB is adopted, including:
Millions of users in colleges and universities
Thousands of startups
Thousands of people at every major company and organization where engineers and scientists work, such as Apple, Google, Airbus, Tesla, and the International Monetary Fund
Support and Documentation
Stack Overflow and similar sites are the primary support mechanism for most Python users. With so many users worldwide, it is easy to find or start a discussion online that can help answer just about any question. Documentation is available via docstrings and individual websites for Python and most libraries.
MATLAB licenses include free live support, so users can pick up the phone or send an email to get help from a MATLAB expert on their specific project. Additional free support from MathWorks worldwide engineers can help users figure out the best way to assemble available technology for their application, research, or teaching. MATLAB Answers provides an online question and answer forum specific to MATLAB, similar to Stack Overflow. MATLAB includes an integrated documentation system that combines professionally authored documentation for all MATLAB and Simulink products, help for user-authored packages, and additional online resources such as MATLAB Answers and videos.
Cost
Paid services also provide access to packaged or hosted distributions that eliminate much of the pain of configuring a Python installation with compatible versions of libraries.
MATLAB is not free, though it is more accessible and costs less than people assume. Approximately 8 million people have unlimited access to MATLAB through their school, research institution, or employer, including at most universities worldwide that grant engineering and science degrees. Institutions choose to invest in MATLAB because they recognize the value of the increased productivity from providing their engineers and scientists with purpose-built tools.
OUTPUT:
RAJU is defined. So, this line will be added in this C file
B) Example of #IFNDEF AND #ENDIF IN C:
#ifndef exactly acts as reverse as #ifdef directive. If particular macro is not defined, "If" clause statements are included in source file.
Otherwise, else clause statements are included in source file for compilation and execution.
#include
OUTPUT:
SELVA is not defined. So, now we are going to define here
C) Example of #IF, #ELSE AND #ENDIF IN C*:*
"If" clause statement is included in source file if given condition is true.
Otherwise, else clause statement is included in source file for compilation and execution.
#include
OUTPUT:
This line will be added in this C file since a = 100
D) Example of #UNDEF IN C LANGUAGE:
This directive undefines existing macro in the program.
#include
OUTPUT:
First defined value for height : 100 value of height after undef & redefine : 600
E) Example of PRAGMA IN C LANGUAGE:
Pragma is used to call a function before and after main function in a C program
#include
OUTPUT:
Function1 is called before main function call Now we are in main function Function2 is called just before end of main function
More on PRAGMA directive in C LANGUAGE:
Pragma command Description
#Pragma startup
#Pragma exit
#pragma warn - rvl If function doesn't return a value, then warnings are suppressed by this directive while compiling.
#pragma warn - par If function doesn't use passed function parameter , then warnings are suppressed
#pragma warn - rch If a non reachable code is written inside a program, such warnings are suppressed by this directive.
Why do we use '#include
We're lazy! We don't want to declare the printf function. It's already done for us inside the file 'stdio.h'. The #include includes the text of the file as part of our file to be compiled.
Specifically, the #include directive takes the file stdio.h (which stands for standard input and output) located somewhere in your operating system, copies the text, and substitutes it where the #include was.
stdio.h - part of the C Standard Library
other important header files: ctype.h, math.h, stdlib.h, string.h, time.h
Included files must be on include path
-Idirectory with gcc: specify additional include directories
standard include directories assumed by default
include "stdio.h" - searches ./ for stdio.h first
Questions
Consider the statement:
double ans = 18.0/squared(2+1);
For each of the four versions of the function macro squared() below, write the corresponding value of ans.
1. #define squared(x) x*x Answer: 18.0/2 + 1 ∗ 2 + 1 = 9 + 2 + 1 = 12. 2. #define squared(x) (x*x) Answer: 18.0/(2 + 1 ∗ 2 + 1) = 18/5 = 3.6. 3. #define squared(x) (x)(x) Answer: 18.0/(2 + 1) ∗ (2 + 1) = 6 ∗ 3 = 18. 4. #define squared(x) ((x)*(x)) Answer: 18.0/((2 + 1) ∗ (2 + 1)) = 18/9 = 2.
The main() function
main(): entry point for C program
Simplest version: no inputs, outputs 0 when successful, and nonzero to signal some error
int main(void);
Two-argument form of main(): access command-line arguments
int main(int argc, char ∗∗argv);
Question
Describe the difference between the literal values 7, "7", and '7'.
The first literal describes an integer of value 7.
The second describes a null-terminated string consisting of the character '7'.
The third describes the character '7', whose value is its ASCII character code (55).
Console I/O
stdout, stdin: console output and input streams
puts(string): print string to stdout
putchar(char): print character to stdout
char = getchar(): return character from stdin
string = gets(string): read line from stdin into string
Variables and Data Types
A variable is as named link/reference to a value stored in the system's memory or an expression that can be evaluated.
The datatype of an object in memory determines the set of values it can have and what operations that can be performed on it.
C is a weakly typed language. It allows implicit conversions as well as forced (potentially dangerous) casting.
Data types and sizes
C has a small family of datatypes.
Numeric (int, float, double)
Character (char)
User defined (struct,union)
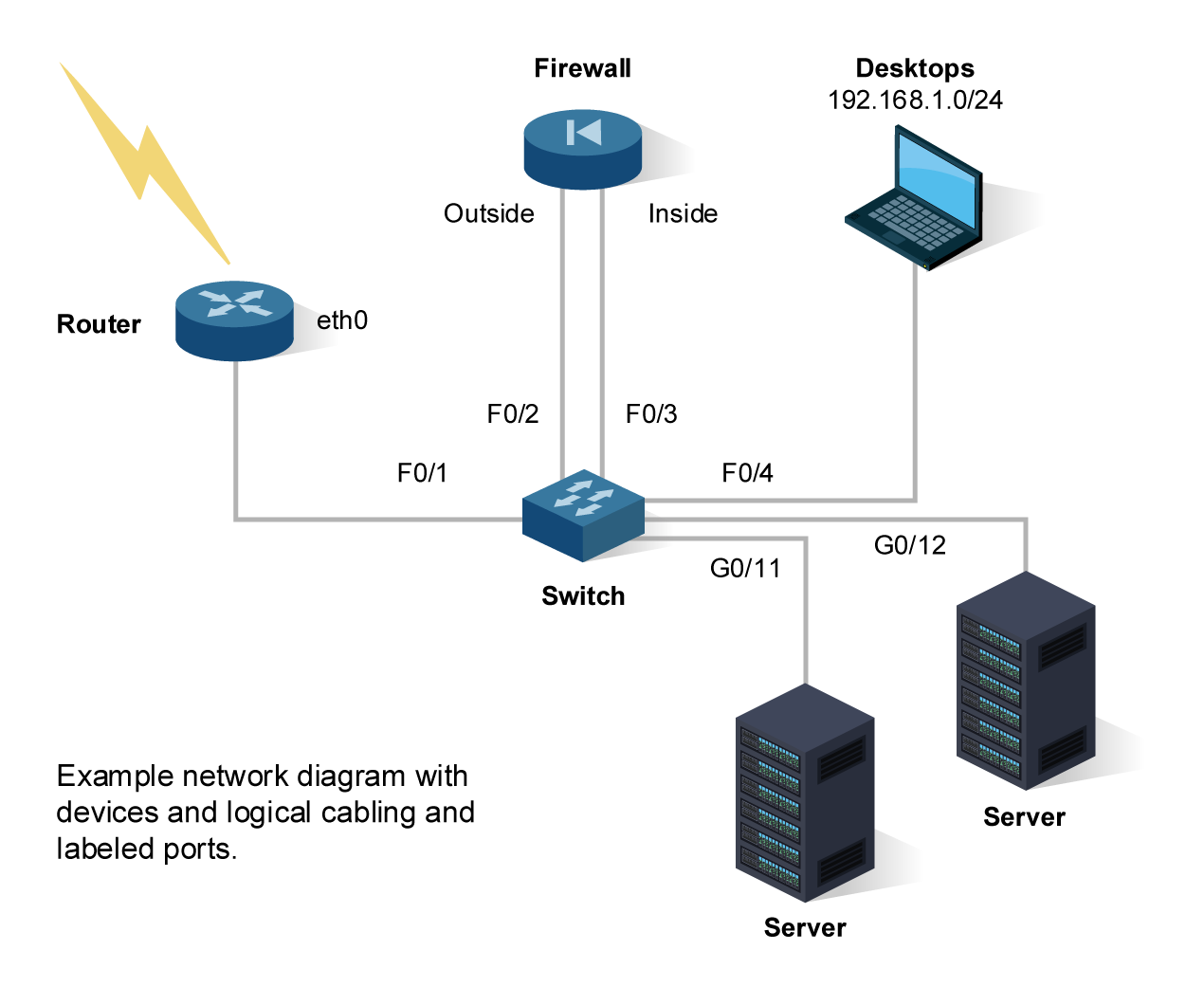
Router * eth0 Outside F0/1 Firewall Example network diagram with devices and logical cabling and labeled ports. F0/2 Switch Inside F0/3 F0/4 G0/11 Desktops 192.168.1.0/24 Server G0/12 Server
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts