

Question: *PYTHON COURSE* Can someone please help me answer this question for my class. My professor mentioned it using pandas and I honestly dont know what

 *PYTHON COURSE* Can someone please help me answer this question for my class. My professor mentioned it using pandas and I honestly dont know what that is. There are a lot of pictures that I believe are just there to just help explain what to do. The problem is at the end. I will 100% like you solving my answering. Thank you so much!!!!
*PYTHON COURSE* Can someone please help me answer this question for my class. My professor mentioned it using pandas and I honestly dont know what that is. There are a lot of pictures that I believe are just there to just help explain what to do. The problem is at the end. I will 100% like you solving my answering. Thank you so much!!!!
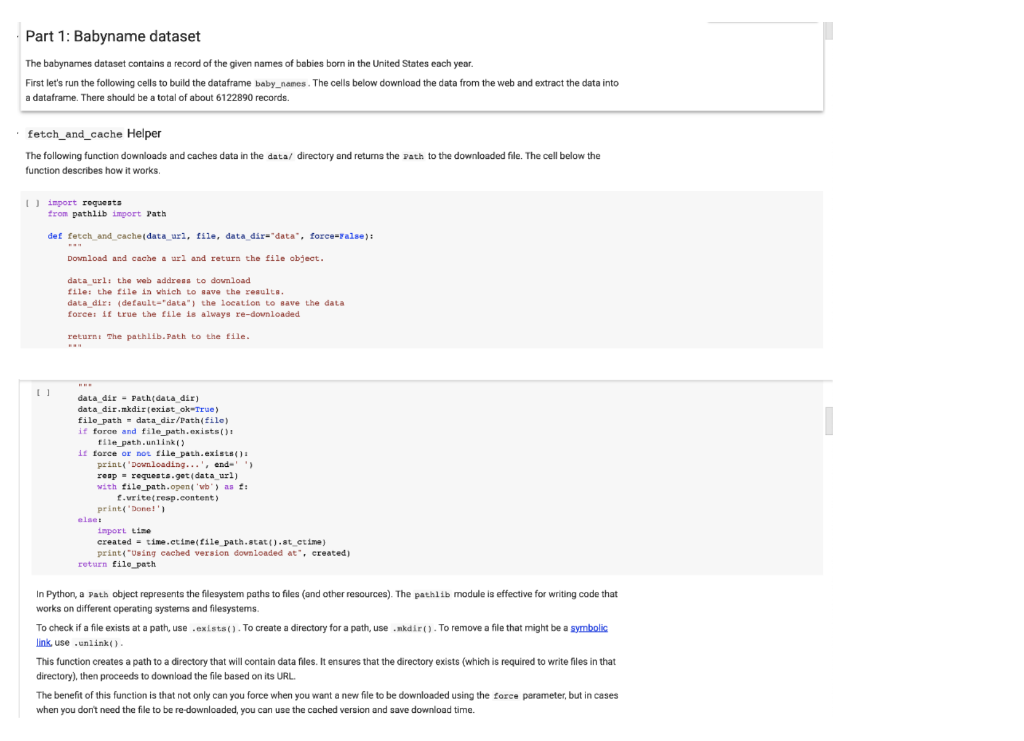
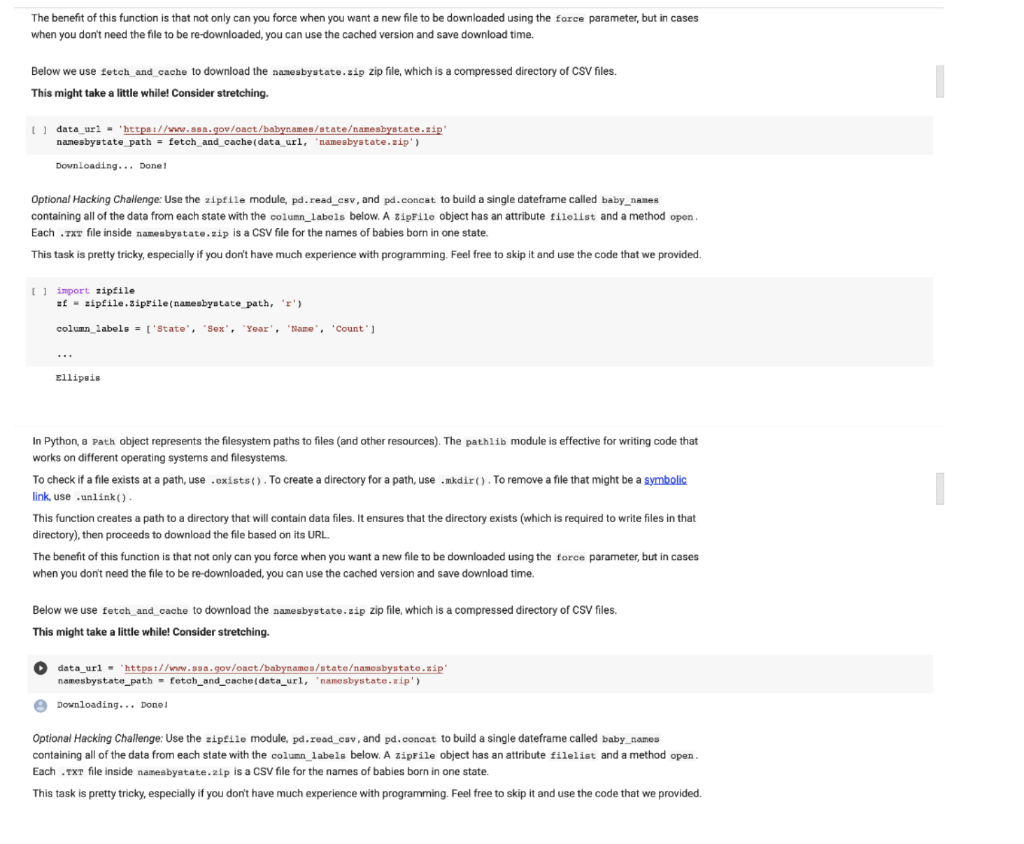
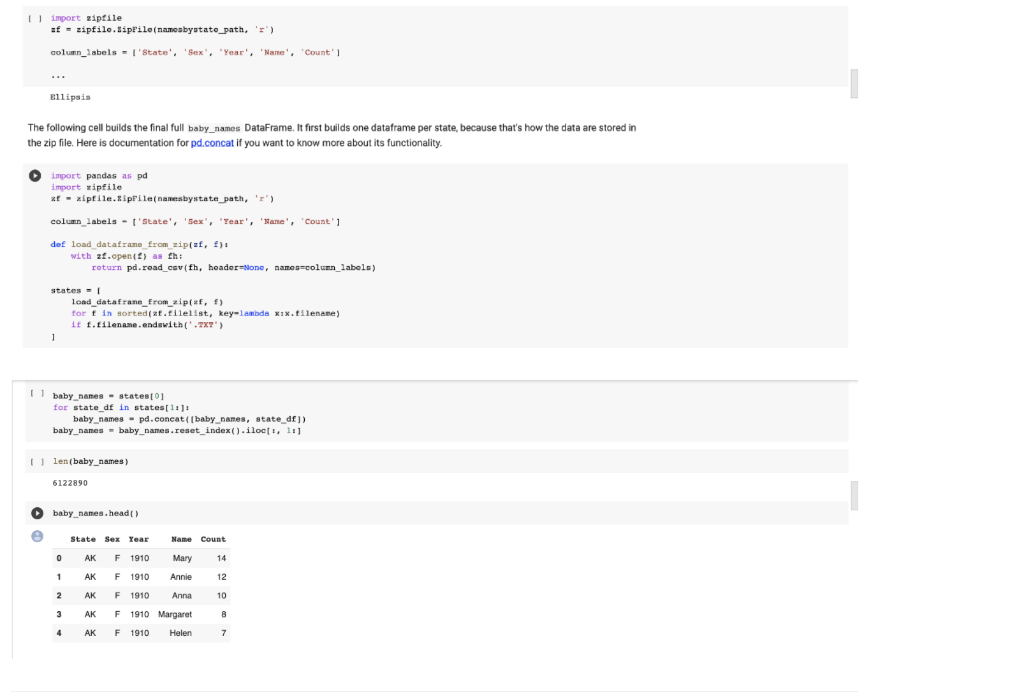
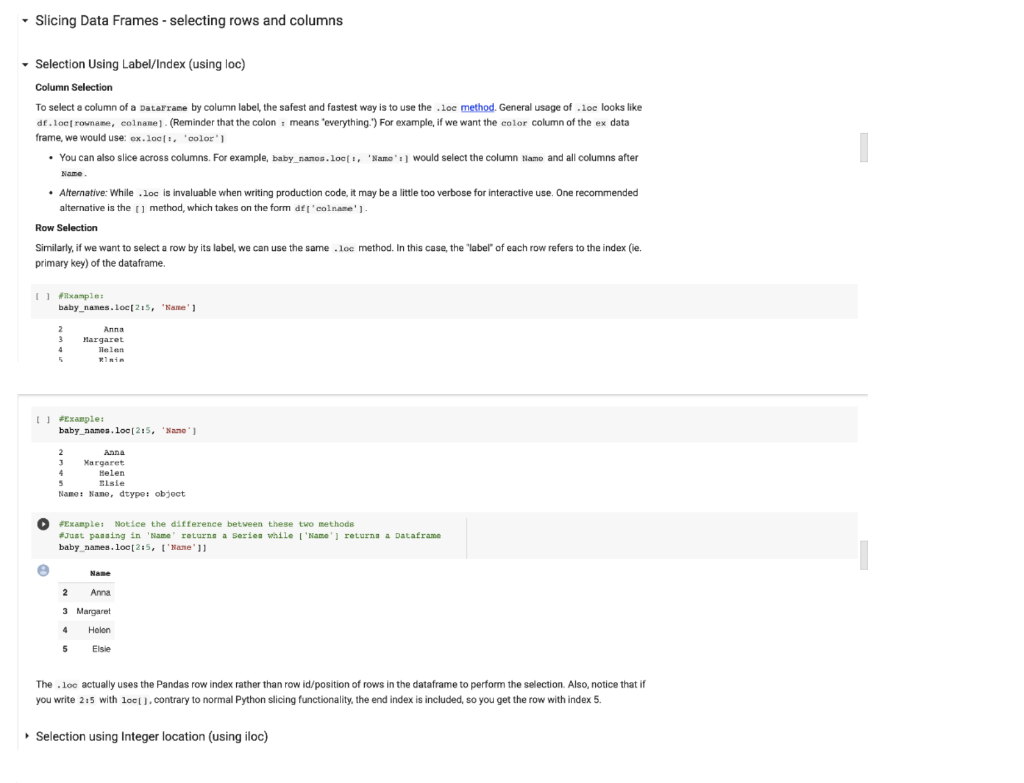
Part 1: Babyname dataset The babynames dataset contains a record of the given names of babies born in the United States each year. First let's run the following cells to build the dataframe baby_names. The cells below download the data from the web and extract the data into a dataframe. There should be a total of about 6122890 records. fetch_and_cache Helper The following function downloads and caches data in the data/ directory and returns the path to the downloaded file. The cell below the function describes how it works import requests from pathlib import Path def fetch_and_cache data_ari, file, data_dir="data", force-False): Download and cache a url and return the file object. data url: the web address to download file: the file in which to save the results. data dir: (default"data") the location to save the data force: if true the file is always re-downloaded return the pathlib.Path to the file. ] I data dir - Path(data dir) data dir.mkdir (exist okrue) filo_path = data_dir/Path(file) it force and file_path.exists(): file_path.unlink() if force or not file_path.exists(). print("Downloading...', end-' ' resp = requests.get(data_url) with file_path.open('b') as t: f.write(resp.content) print('Done!') else: import time created = time.ctime(file path.stat().st_ctime) print("Using cached version downloaded at, created) return file_path In Python, a Path object represents the filesystem paths to files (and other resources). The pathlib module is effective for writing code that works on different operating systems and filesystems. To check if a file exists at a path, use .exists(). To create a directory for a path, use .nkdir(). To remove a file that might be a symbolic link use.unlink() This function creates a path to a directory that will contain data files. It ensures that the directory exists (which is required to write files in that directory), then proceeds to download the file based on its URL. The benefit of this function is that not only can you force when you want a new file to be downloaded using the force parameter, but in cases when you don't need the file to be re-downloaded, you can use the cached version and save download time. The benefit of this function is that not only can you force when you want a new file to be downloaded using the force parameter, but in cases when you don't need the file to be re-downloaded, you can use the cached version and save download time. Below we use fetch_and_cache to download the namesbystate.zip zip file, which is a compressed directory of CSV files. This might take a little while! Consider stretching. [ ] data_uri = 'https://www.852.gov/oact/babynames/atateamesbystate.zip namesbystate_path = fetch_and_cache (data_url, 'namesbystate.zip') Downloading... Done! Optional Hacking Challenge: Use the zipfile module, pd. read_csv, and pd.concat to build a single dateframe called baby names containing all of the data from each state with the column_labels below. A zipFile object has an attribute filelist and a method open. Each .txt file inside namesbystate.zip is a CSV file for the names of babies born in one state. This task pretty tricky, especially if you don't have much experience with programming. Feel free to skip it and use the code that we provided. [] import zipfile af - zipfile. Ziprile (namesbystate_path, 'r') column_labels = ['State', 'Sex', 'Year', 'Name', 'Count'] Ellipsis In Python, a Path object represents the filesystem paths to files and other resources). The pathlib module is effective for writing code that works on different operating systems and filesystems. To check if a file exists at a path, use .exists(). To create a directory for a path, use .mkdir(). To remove a file that might be a symbolic link, use unlink(). This function creates a path to a directory that will contain data files. ensures that the directory exists (which is required to write files in that directory), then proceeds to download the file based on its URL. The benefit of this function is that not only can you force when you want a new file to be downloaded using the force parameter, but in cases when you don't need the file to be re-downloaded, you can use the cached version and save download time. Below we use fetch_and_cache to download the namesbystate.zip zip file, which is a compressed directory of CSV files. This might take a little while! Consider stretching. data_url = "https://www.ssa.gov/oact/babynames/stateamesbystate.zip namesbystate_path - fetch_and_cache(data_url, 'namesbystate.zip) Downloading... Done! Optional Hacking Challenge: Use the zipfile module, pd. read_csv, and pd.concat to build a single dateframe called baby names containing all of the data from each state with the column_labels below. A zipFile object has an attribute filelist and a method open Each .txt file inside namesbystate.zip is a CSV file for the names of babies born in one state. This task is pretty tricky, especially if you don't have much experience with programming. Feel free to skip it and use the code that we provided. import Bipfile af - zipfile. SipFile namesbystato_path, ':') column_labels - l'State', 'sex', 'Year', 'Name', 'Count' ellipais The following cell builds the final full baby_names DataFrame. It first builds one dataframe per state, because that's how the data are stored in the zip file. Here is documentation for pd.concat if you want to know more about its functionality. import pandas as pd import zipfile ut - zipfile.lipFile(namesbystate_path, '') column_labels - State', 'sex', 'Year', 'Name', 'Count'] def load dataframe from zip(zf, f) with zf.open(?) as th: return pd.road_csvfh, hoader one, names-column_labels) states - load dataframe_from_zip(x, f) for fin sorted at Filelist, key-lambda xix.filename) it 1.filename.endswith('.TXT) 1 U baby names - states[0] for state_df in states[1.]: baby names - pd.concat(baby names, state_df]) () baby_names - baby names.reset_index().loc!, 1:] len (baby names) 6122890 baby names.head() e State Sex Year Name Count 0 AK Mary 14 F 1910 F 1910 1 AK Annie 12 2 AK F 1910 Anna 10 3 AK F 1910 Margaret B AK F 1910 Helen 7 Slicing Data Frames - selecting rows and columns Selection Using Label/Index (using loc) Column Selection To select a column of a DataFrame by column label the safest and fastest way is to use the loc method. General usage of .loc looks like df.locrownane, colnane) (Reminder that the colon means 'everything.") For example, if we want the color column of the ex data frame, we would use: ex.loc., 'color) . You can also slice across columns. For example, baby_nanos.loc :, 'Name') would select the column Name and all columns after Name Alternative: While .loc is invaluable when writing production code, it may be a little too verbose for interactive use. One recommended alternative is the method, which takes on the form df ['colname'). Row Selection Similarly, if we want to select a row by its label, we can use the same loc method. In this case, the "label" of each row refers to the index (ie. primary key) of the dataframe. U fixample: baby_names.loc[215, 'Name'] Anna Margaret Helen L] Example: baby names.loc(215, 'Name') Aana argaret 4 Helen 5 Elsie Name: Nano, dtyper object #Example: Notice the difference between these two methods #Just passing in 'Name' returns a series while ['Name') returns a Dataframe baby names.loc[2:5, ['Name']] Name 2 Anna 3 Margaret 4 Holon 5 Elsie The .loc actually uses the Pandas row index rather than row id/position of rows in the dataframe to perform the selection. Also, notice that if you write 2.5 with loc(), contrary to normal Python slicing functionality, the end index is included, so you get the row with index 5. Selection using Integer location (using iloc) (11 pts) Problem 1 Selecting multiple columns is easy. You just need to supply a list of column names. Select the name and Year in that order from the baby_names table. [name_and_year = ... name_and_year[:51 Note that .loc[] can be used to re-order the columns within a dataframe. (11 pts) Problem 2 Using a boolean array, select the names in Year 2000 (from baby_names) that have larger than 3000 counts. Keep all columns from the original baby names dataframe. Note: Any time you use p & q to filter the dataframe, make sure to use df[ (df [p]) & (df [9]) or df.loc[(df[p]) & (df[q])]. That is, make sure to wrap conditions with parentheses. Remember that both slicing and loc will achieve the same result, it is just that loc is typically faster in production. You are free to use whichever one you would like. [] result = ... result.head() (11 pts) Problem 3 Some names gain/lose popularity because of cultural phenomena such as a political figure coming to power. Below, we plot the popularity of the female name Hillary in Calfiornia over time. What do you notice about this plot? What might be the cause of the steep drop? ( hillary_baby_name = baby names[(baby_names['Name'] == 'Hillary') & (baby_names[ 'State'] == 'CA') & (baby_names['sex'] == 'F')] plt.plot(hillary_baby_name[ 'Year'), hillary_baby_name['Count']) plt.title("Hillary Popularity Over Time") plt.xlabel('Year') plt.ylabel('Count'); Write your answer here, replacing this text
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts