PYTHON
I am trying to scrape Twitter using BeautifulSoup for an assignment and I keep getting 'Bad Request' error.
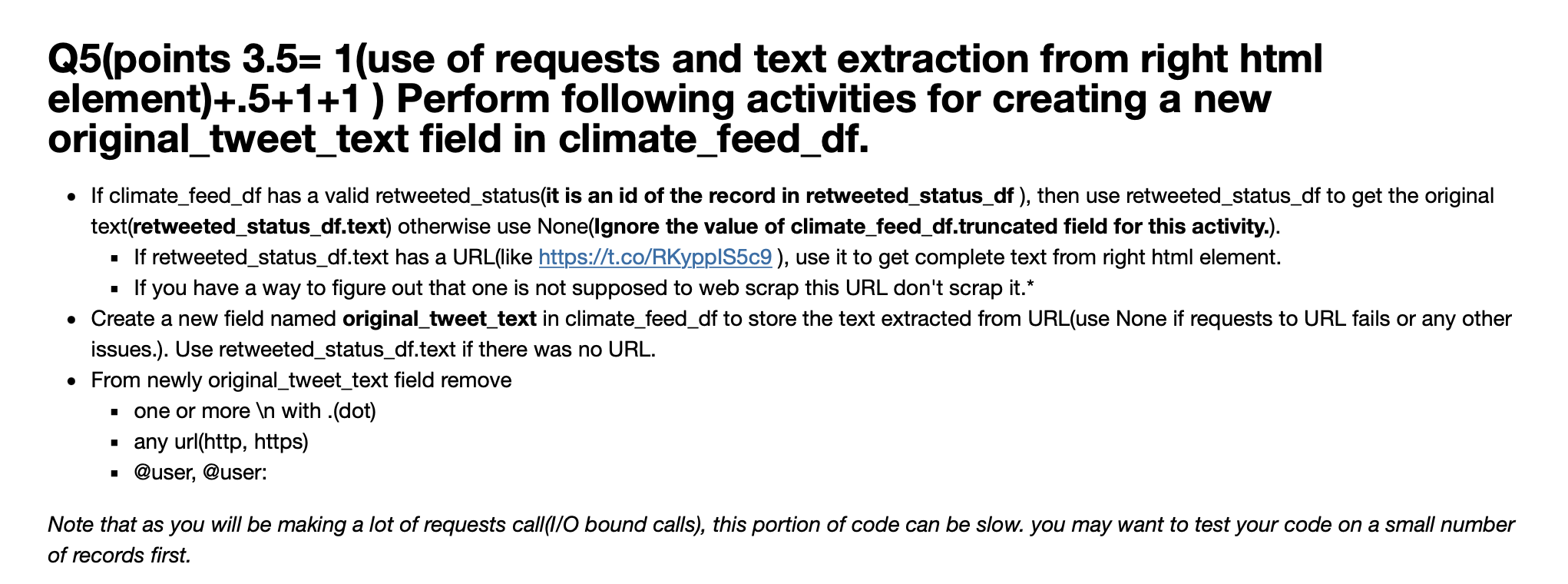
This is my assignment:
This is my code:
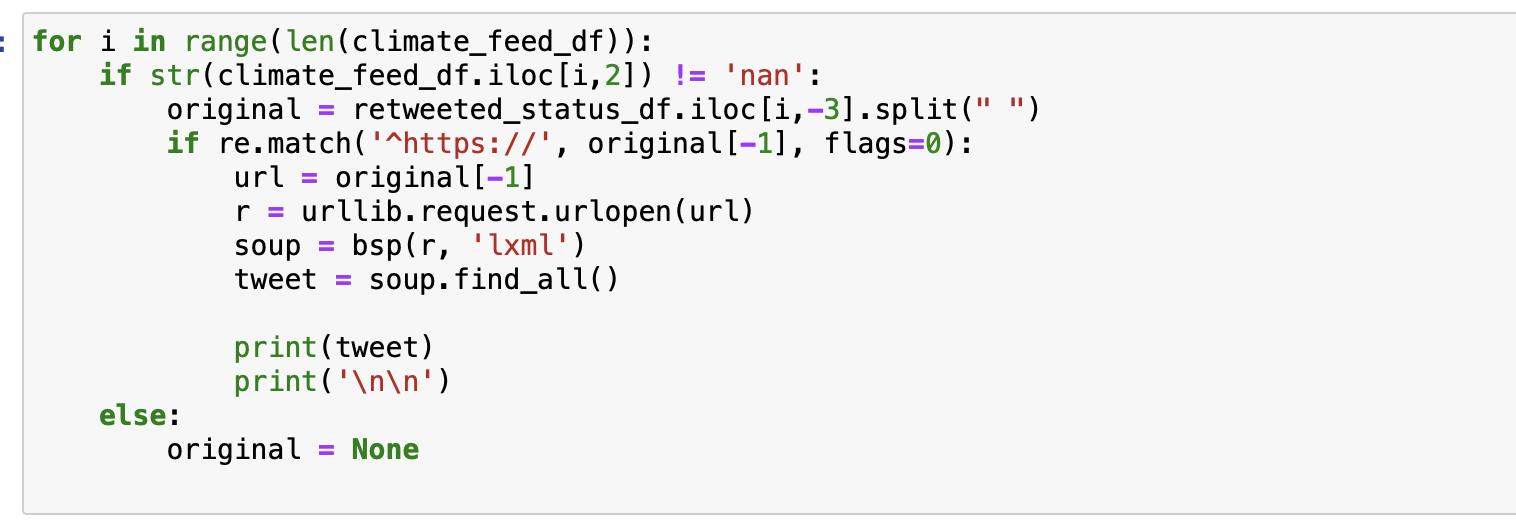


Q5(points 3.5= 1(use of requests and text extraction from right html element)+.5+1+1 ) Perform following activities for creating a new original_tweet_text field in climate_feed_df. If climate_feed_df has a valid retweeted_status(it is an id of the record in retweeted_status_df), then use retweeted_status_df to get the original text(retweeted_status_df.text) otherwise use None(Ignore the value of climate_feed_df.truncated field for this activity.). If retweeted_status_df.text has a URL(like https://t.co/RKypplS5c9), use it to get complete text from right html element. If you have a way to figure out that one is not supposed to web scrap this URL don't scrap it.* Create a new field named original_tweet_text in climate_feed_df to store the text extracted from URL(use None if requests to URL fails or any other issues.). Use retweeted_status_df.text if there was no URL. From newly original_tweet_text field remove one or more with .(dot) any url(http, https) @user, @user: Note that as you will be making a lot of requests call(I/O bound calls), this portion of code can be slow. you may want to test your code on a small number of records first. : for i in range(len(climate_feed_df)): if str(climate_feed_df.iloc[i,2]) != 'nan': original = retweeted_status_df.iloci,-3].split(" ") if re.match("^https://', original[-1), flags=0): url = original[-1] r = urllib.request.urlopen(url) soup bspar, 'lxml') tweet = soup.find_all() print(tweet) print(" ') else: original = None HTTPError Traceback (most recent call last)
in 4 if re.match("^https://', original[-1], flags=0): 5 url original[-1] 6 urllib.request.urlopen(url) 7 soup bspr, 'lxml') 8 tweet soup.find_all() r = ~/opt/anaconda3/lib/python3.8/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs) 647 class HTTPDefaultErrorHandler(BaseHandler): 648 def http_error_default(self, req, fp, code, msg, hdrs): --> 649 raise HTTPError(req. full_url, code, msg, hdrs, fp) 650 651 class HTTPRedirectHandler(BaseHandler): HTTPError: HTTP Error 400: Bad Request Q5(points 3.5= 1(use of requests and text extraction from right html element)+.5+1+1 ) Perform following activities for creating a new original_tweet_text field in climate_feed_df. If climate_feed_df has a valid retweeted_status(it is an id of the record in retweeted_status_df), then use retweeted_status_df to get the original text(retweeted_status_df.text) otherwise use None(Ignore the value of climate_feed_df.truncated field for this activity.). If retweeted_status_df.text has a URL(like https://t.co/RKypplS5c9), use it to get complete text from right html element. If you have a way to figure out that one is not supposed to web scrap this URL don't scrap it.* Create a new field named original_tweet_text in climate_feed_df to store the text extracted from URL(use None if requests to URL fails or any other issues.). Use retweeted_status_df.text if there was no URL. From newly original_tweet_text field remove one or more with .(dot) any url(http, https) @user, @user: Note that as you will be making a lot of requests call(I/O bound calls), this portion of code can be slow. you may want to test your code on a small number of records first. : for i in range(len(climate_feed_df)): if str(climate_feed_df.iloc[i,2]) != 'nan': original = retweeted_status_df.iloci,-3].split(" ") if re.match("^https://', original[-1), flags=0): url = original[-1] r = urllib.request.urlopen(url) soup bspar, 'lxml') tweet = soup.find_all() print(tweet) print(" ') else: original = None HTTPError Traceback (most recent call last) in 4 if re.match("^https://', original[-1], flags=0): 5 url original[-1] 6 urllib.request.urlopen(url) 7 soup bspr, 'lxml') 8 tweet soup.find_all() r = ~/opt/anaconda3/lib/python3.8/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs) 647 class HTTPDefaultErrorHandler(BaseHandler): 648 def http_error_default(self, req, fp, code, msg, hdrs): --> 649 raise HTTPError(req. full_url, code, msg, hdrs, fp) 650 651 class HTTPRedirectHandler(BaseHandler): HTTPError: HTTP Error 400: Bad Request




