

Question
Python Programming SQL Database name = movie.db Table name = moviesbygenres SQL screenshot attached. 1. Import the packages that you need. You will need more
Python Programming
SQL Database name = movie.db
Table name = moviesbygenres
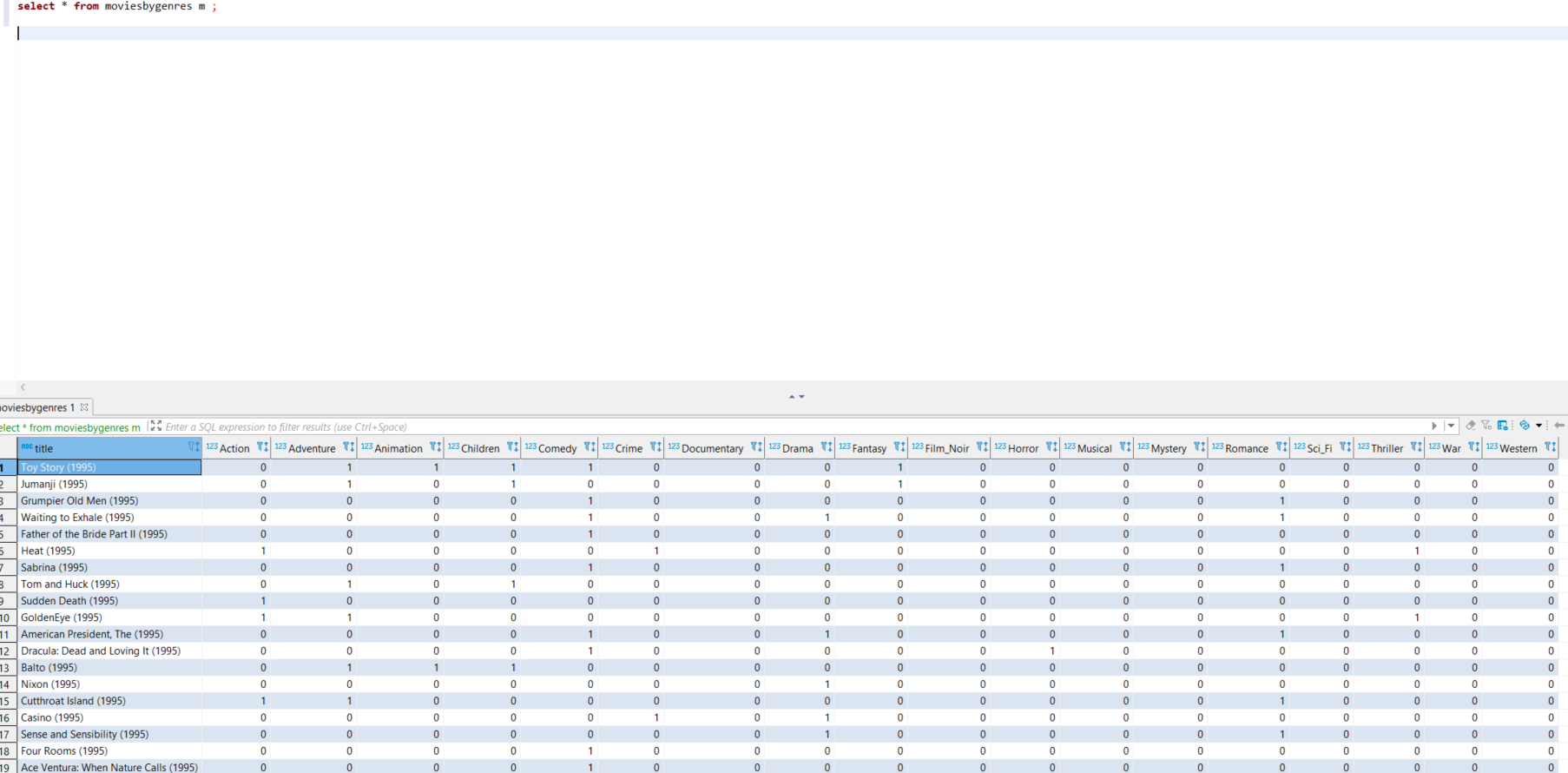
SQL screenshot attached.
1. Import the packages that you need. You will need more than just sqlite3.
import sqlite3
import numpy as np
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
from scipy.spatial import distance
2. Open a connection to MovieDB.db
3. Query the 1-hot-encoding table to get the matrix with the 0-1 values
4. Save the results from the query as an ndarray (numpy matrix).
5. Use function np.dot() to find the dot product of every row in the 0-1 matrix with every other row.
6. Make sure that the result from the step above is a square matrix where the size is the number of movies.
- Examine this matrix. Does it make sense to you?
- Can you look at the first few movies in the database and tell if it worked right?
7. Save the results from the matrix as a Pandas DataFrame where the column names are the movie titles. - You will need to get the movie titles from the database.
8. Add the movie titles as a starting column to the same dataframe from step 7.
9. Export the data for the first 10 movies from the DataFrame to a CSV file.
10. Once again check the CSV file to make sure that the results are accurate before you submit.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Financial management theory and practice
Authors: Eugene F. Brigham and Michael C. Ehrhardt
12th Edition
978-0030243998, 30243998, 324422695, 978-0324422696