python question help, answer/debug question 1.7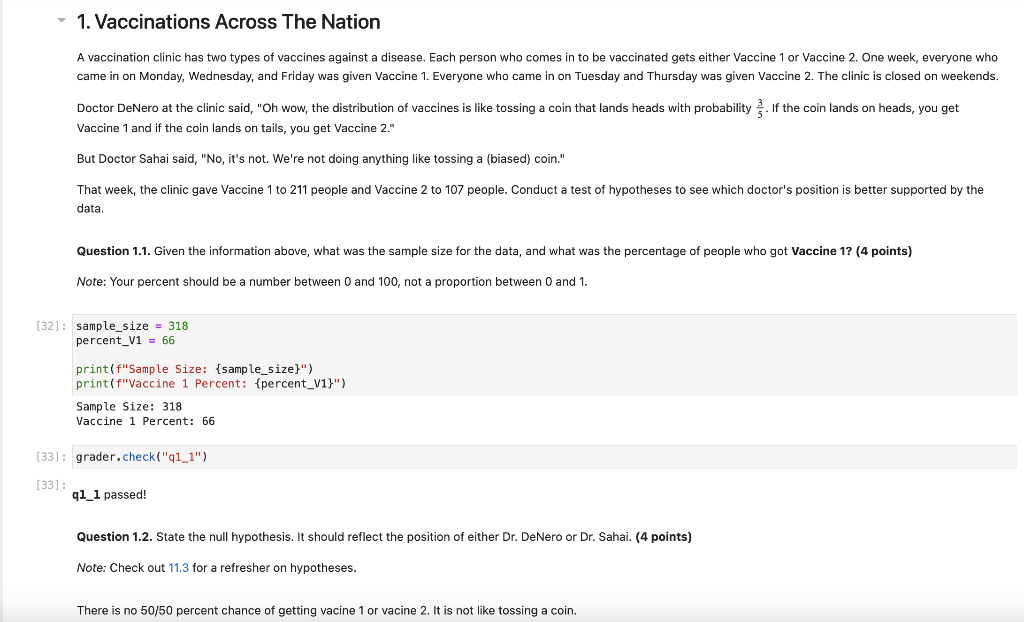
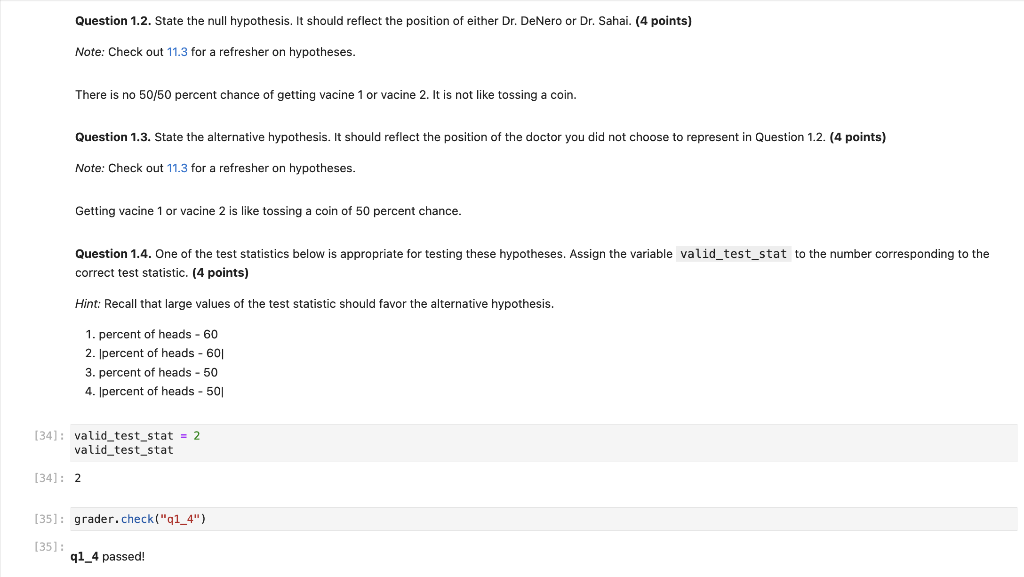
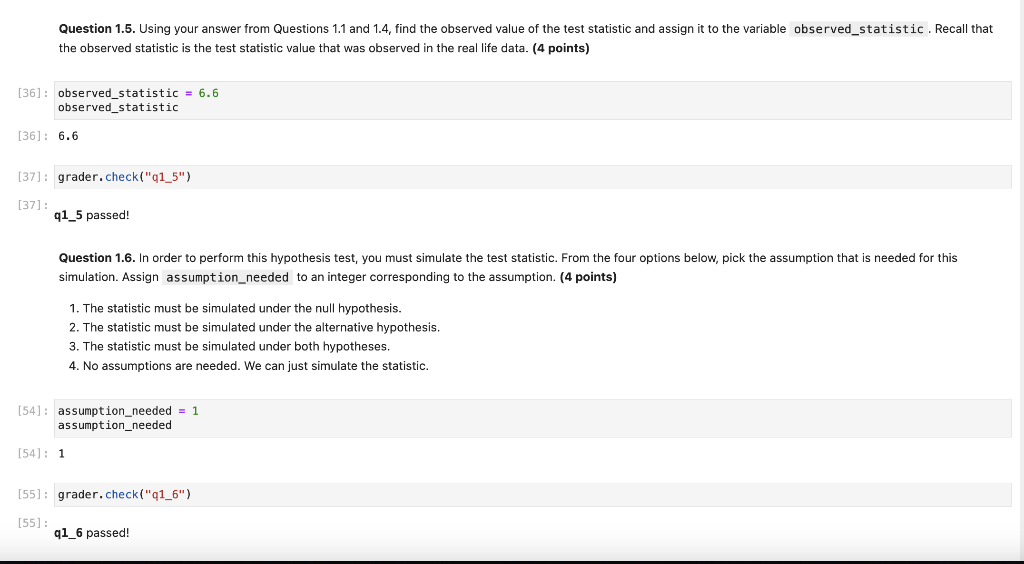
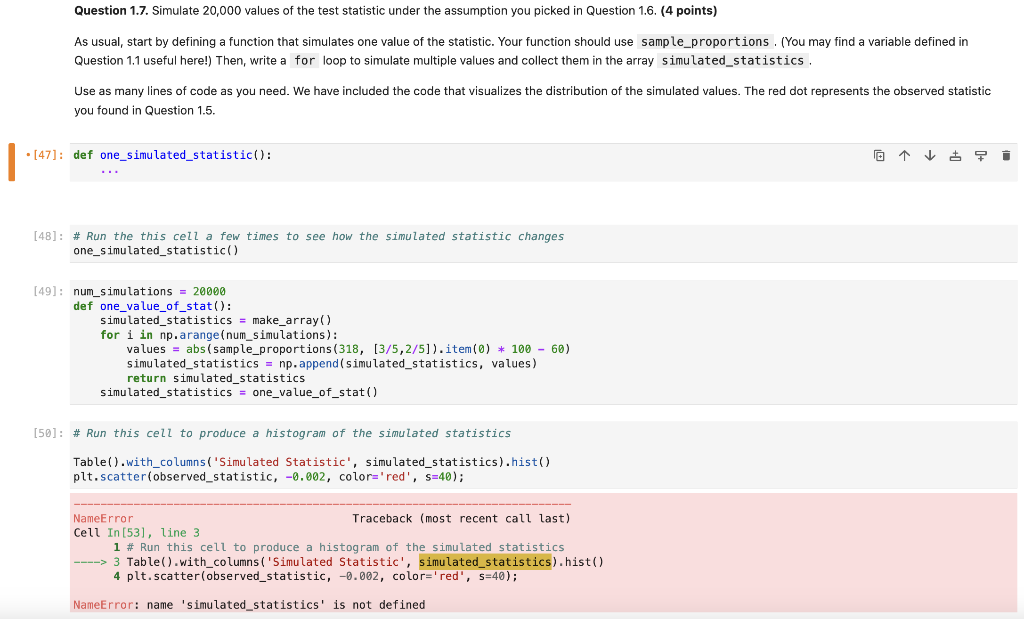
1. Vaccinations Across The Nation A vaccination clinic has two types of vaccines against a disease. Each person who comes in to be vaccinated gets either Vaccine 1 or Vaccine 2 . One week, everyone who came in on Monday, Wednesday, and Friday was given Vaccine 1. Everyone who came in on Tuesday and Thursday was given Vaccine 2. The clinic is closed on weekends. Doctor DeNero at the clinic said, "Oh wow, the distribution of vaccines is like tossing a coin that lands heads with probability 53. If the coin lands on heads, you get Vaccine 1 and if the coin lands on tails, you get Vaccine 2." But Doctor Sahai said, "No, it's not. We're not doing anything like tossing a (biased) coin." That week, the clinic gave Vaccine 1 to 211 people and Vaccine 2 to 107 people. Conduct a test of hypotheses to see which doctor's position is better supported by the data. Question 1.1. Given the information above, what was the sample size for the data, and what was the percentage of people who got Vaccine 1? (4 points) Note: Your percent should be a number between 0 and 100 , not a proportion between 0 and 1. ]: sample_size =318 percent_V1 =66 print(f"Sample Size: \{sample_size\}") print(f"Vaccine 1 Percent: \{percent_V1\}") Sample Size: 318 Vaccine 1 Percent: 66 ]: grader.check("q1_1") ]: q1_1 passed! Question 1.2. State the null hypothesis. It should reflect the position of either Dr. DeNero or Dr. Sahai. (4 points) Note: Check out 11.3 for a refresher on hypotheses. There is no 50/50 percent chance of getting vacine 1 or vacine 2 . It is not like tossing a coin. Getting vacine 1 or vacine 2 is like tossing a coin of 50 percent chance. Question 1.4. One of the test statistics below is appropriate for testing these hypotheses. Assign the variable valid_test_stat to the number corresponding to the correct test statistic. ( 4 points) Hint: Recall that large values of the test statistic should favor the alternative hypothesis. 1. percent of heads 60 2. |percent of heads 60 3. percent of heads 50 4. |percent of heads 50 Question 1.5. Using your answer from Questions 1.1 and 1.4, find the observed value of the test statistic and assign it to the variable observed_statist ic . Recall that the observed statistic is the test statistic value that was observed in the real life data. (4 points) observed_statistic =6.6 observed_statistic 6.6 grader. check (" q1_5 ") q1_5 passed! Question 1.6. In order to perform this hypothesis test, you must simulate the test statistic. From the four options below, pick the assumption that is needed for this simulation. Assign assumption_needed to an integer corresponding to the assumption. (4 points) 1. The statistic must be simulated under the null hypothesis. 2. The statistic must be simulated under the alternative hypothesis. 3. The statistic must be simulated under both hypotheses. 4. No assumptions are needed. We can just simulate the statistic. Question 1.7. Simulate 20,000 values of the test statistic under the assumption you picked in Question 1.6. (4 points) As usual, start by defining a function that simulates one value of the statistic. Your function should use sample_proportions . (You may find a variable defined in Question 1.1 useful here!) Then, write a for loop to simulate multiple values and collect them in the array simulated_statistics . Use as many lines of code as you need. We have included the code that visualizes the distribution of the simulated values. The red dot represents the observed statistic you found in Question 1.5. def one_simulated_statistic(): ... \# Run the this cell a few times to see how the simulated statistic changes one_simulated_statistic() num_simulations =20000 def one_value_of_stat (): simulated_statistics = make_array () for i in np.arange(num_simulations): values = abs (sample_proportions (318,[3/5,2/5]) item ()100 - 60) simulated_statistics =n np.append (simulated_statistics, values) return simulated_statistics simulated_statistics = one_value_of_stat () \# Run this cell to produce a histogram of the simulated statistics Table().with_columns('Simulated Statistic', simulated_statistics).hist() plt.scatter(observed_statistic, 0.002, color='red', s=40 ); NameError Traceback (most recent call last) Cell In [53], line 3 1 \# Run this cell to produce a histogram of the simulated statistics 3 Table().with_columns('Simulated Statistic', simulated_statistics).hist() 4 plt.scatter(observed_statistic, 0.002, color='red', s=40 ); NameError: name 'simulated_statistics' is not defined




