Python SPYDER
1) Now add code to convert all your tokens to lower case.
2) Now add code to stem your tokens. Describe the parsed output has changed from the previous step.
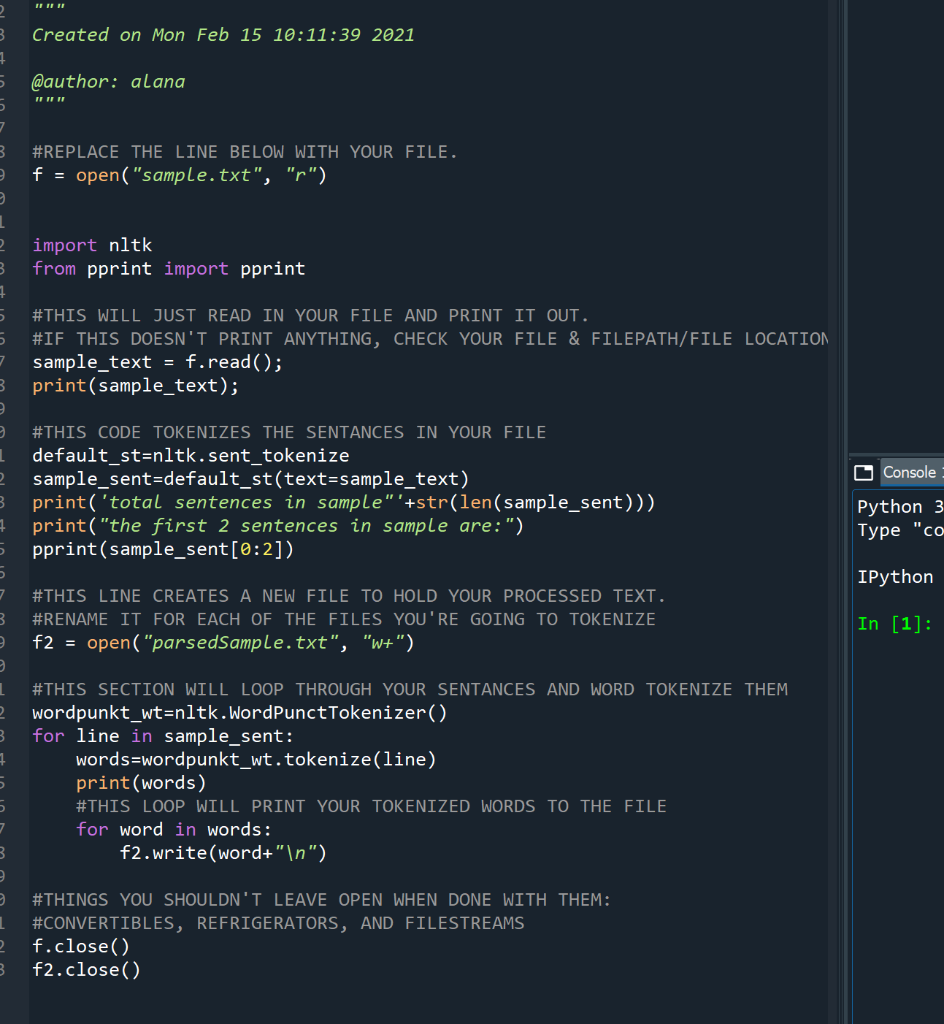
3 Created on Mon Feb 15 10:11:39 2021 1 @author: alana #REPLACE THE LINE BELOW WITH YOUR FILE. f = open("sample.txt", "r") 2 1 2 3 1 import nltk from pprint import pprint #THIS WILL JUST READ IN YOUR FILE AND PRINT IT OUT. #IF THIS DOESN'T PRINT ANYTHING, CHECK YOUR FILE & FILEPATH/FILE LOCATION sample_text = f.read(); print(sample_text); O Console #THIS CODE TOKENIZES THE SENTANCES IN YOUR FILE default_st=nltk.sent_tokenize sample_sent=default_st(text=sample_text) print('total sentences in sample"'+str(len( sample_sent))) print("the first 2 sentences in sample are:") pprint(sample_sent[0:2]) Python 3 Type "co IPython 3 #THIS LINE CREATES A NEW FILE TO HOLD YOUR PROCESSED TEXT. #RENAME IT FOR EACH OF THE FILES YOU'RE GOING TO TOKENIZE f2 = open("parsedSample.txt", "w+") In [1]: 2 3 1 #THIS SECTION WILL LOOP THROUGH YOUR SENTANCES AND WORD TOKENIZE THEM wordpunkt_wt=nltk.WordPunctTokenizer() for line in sample_sent: words=wordpunkt_wt.tokenize(line) print(words) #THIS LOOP WILL PRINT YOUR TOKENIZED WORDS TO THE FILE for word in words: f2.write(word+" ") 5 3 #THINGS YOU SHOULDN'T LEAVE OPEN WHEN DONE WITH THEM: #CONVERTIBLES, REFRIGERATORS, AND FILESTREAMS f.close() f2.close() 3 3 Created on Mon Feb 15 10:11:39 2021 1 @author: alana #REPLACE THE LINE BELOW WITH YOUR FILE. f = open("sample.txt", "r") 2 1 2 3 1 import nltk from pprint import pprint #THIS WILL JUST READ IN YOUR FILE AND PRINT IT OUT. #IF THIS DOESN'T PRINT ANYTHING, CHECK YOUR FILE & FILEPATH/FILE LOCATION sample_text = f.read(); print(sample_text); O Console #THIS CODE TOKENIZES THE SENTANCES IN YOUR FILE default_st=nltk.sent_tokenize sample_sent=default_st(text=sample_text) print('total sentences in sample"'+str(len( sample_sent))) print("the first 2 sentences in sample are:") pprint(sample_sent[0:2]) Python 3 Type "co IPython 3 #THIS LINE CREATES A NEW FILE TO HOLD YOUR PROCESSED TEXT. #RENAME IT FOR EACH OF THE FILES YOU'RE GOING TO TOKENIZE f2 = open("parsedSample.txt", "w+") In [1]: 2 3 1 #THIS SECTION WILL LOOP THROUGH YOUR SENTANCES AND WORD TOKENIZE THEM wordpunkt_wt=nltk.WordPunctTokenizer() for line in sample_sent: words=wordpunkt_wt.tokenize(line) print(words) #THIS LOOP WILL PRINT YOUR TOKENIZED WORDS TO THE FILE for word in words: f2.write(word+" ") 5 3 #THINGS YOU SHOULDN'T LEAVE OPEN WHEN DONE WITH THEM: #CONVERTIBLES, REFRIGERATORS, AND FILESTREAMS f.close() f2.close() 3




