

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
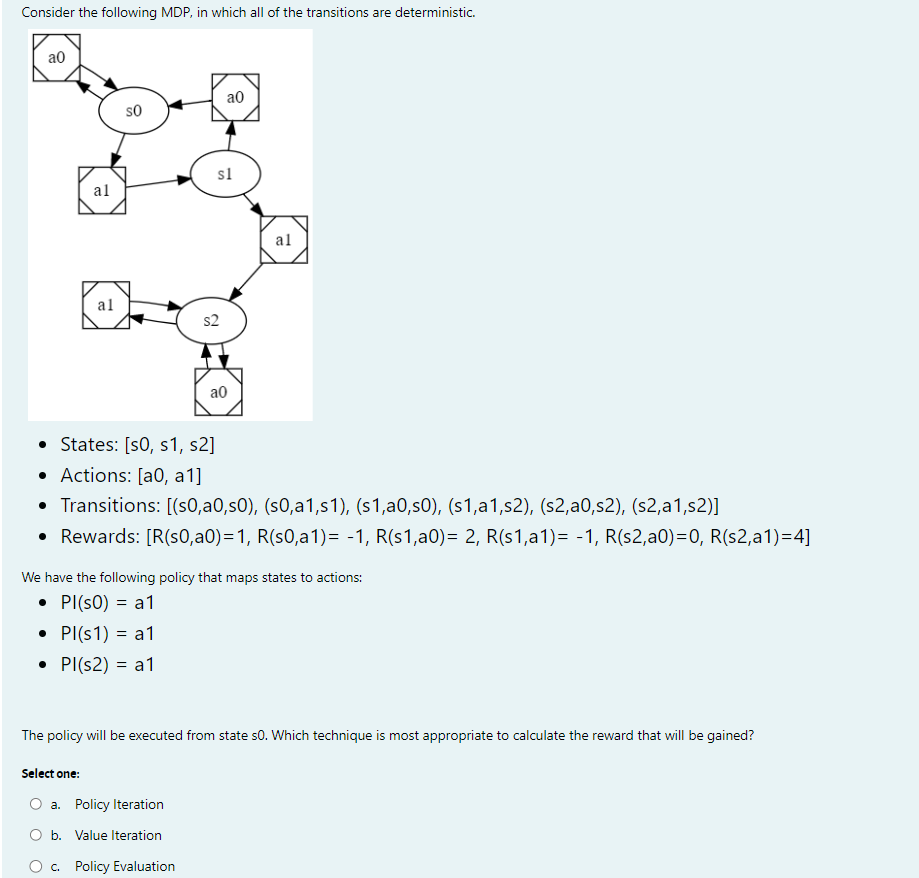
q 1 . Consider the following MDP , in which all of the transitions are deterministic. States: s 0 , s 1 , s 2
q Consider the following MDP in which all of the transitions are deterministic.
States:
Actions: a a
Transitions: sassassassassassas
Rewards:
We have the following policy that maps states to actions:
The policy will be executed from state Which technique is most appropriate to calculate the reward that will be gained?
Select one:
a Policy Iteration
b Value Iteration
c Policy Evaluation q The value of each state is initially set to
Vs for all s
Apply a single iteration of the Bellman Backup with discount factor gamma to update the estimated value of each state under the policy from question
What is the estimated value of state s q Perform a second iteration to improve the value estimates.
What is the new estimated value of state s q True or false: If the only difference between two MDPs is the value of the discount factor then they must have the same optimal policy. q True or false: For an infinitehorizon MDP with a finite number of states and actions, and discount factor gamma value iteration is guaranteed to converge.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Concepts
Authors: David Kroenke, David J. Auer
3rd Edition
0131986252, 978-0131986251