


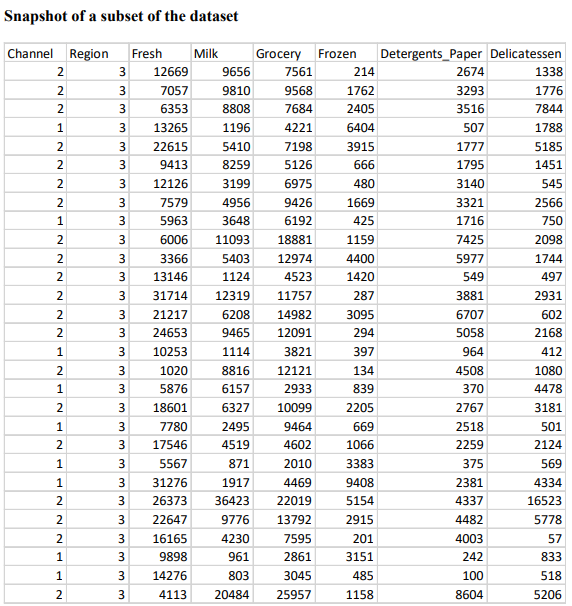
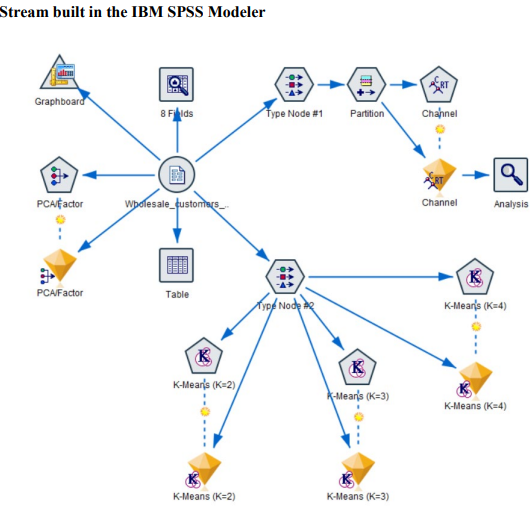
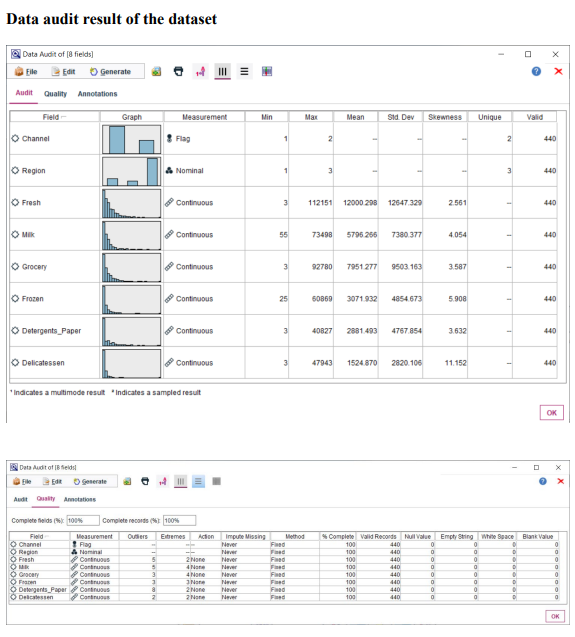
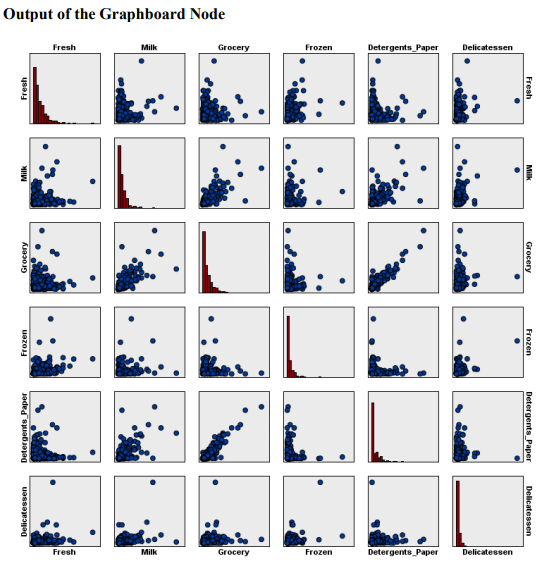
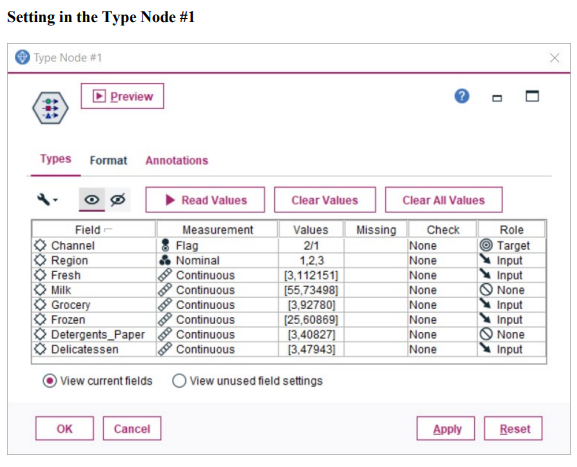
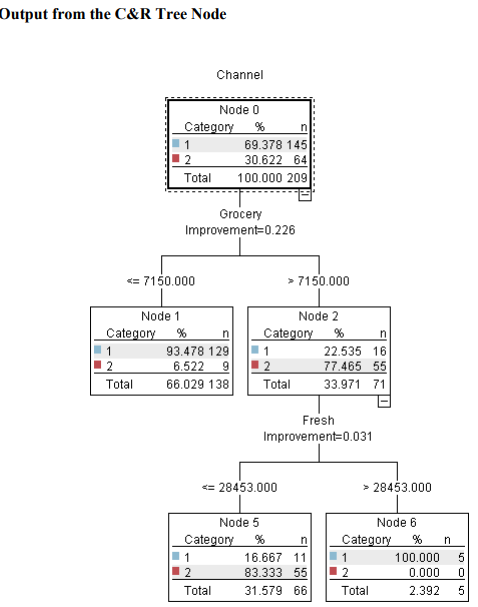
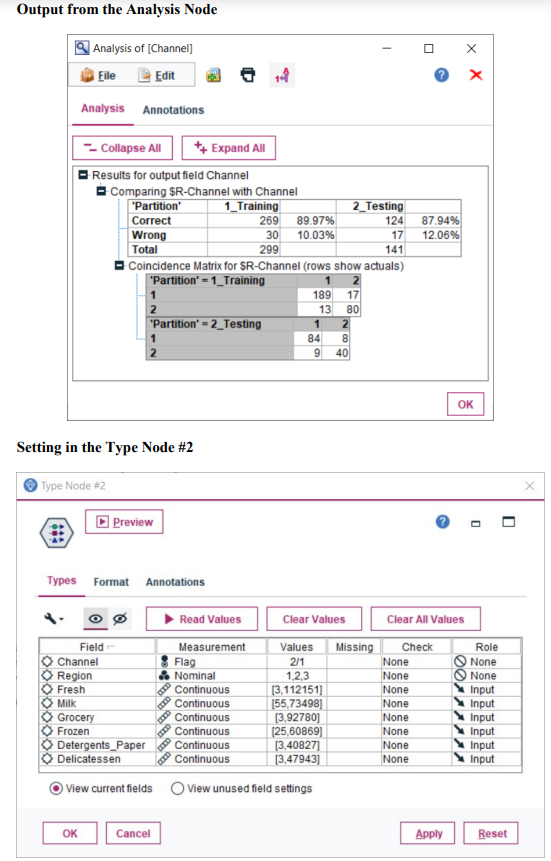
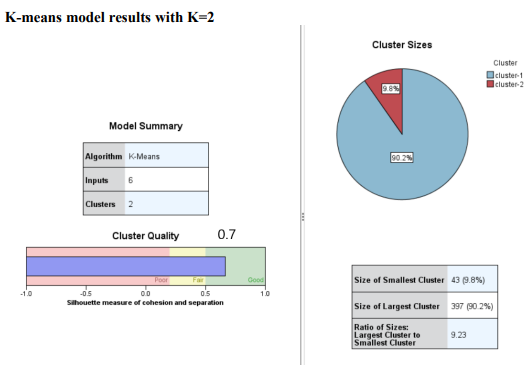
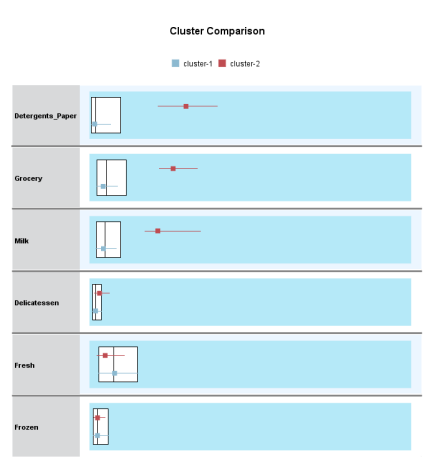
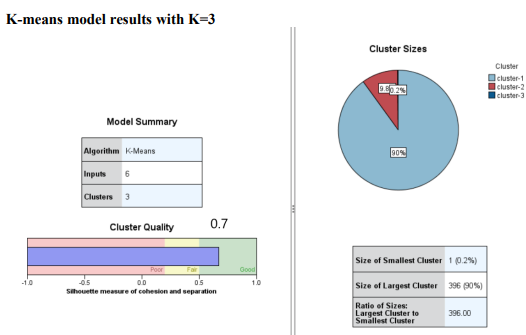
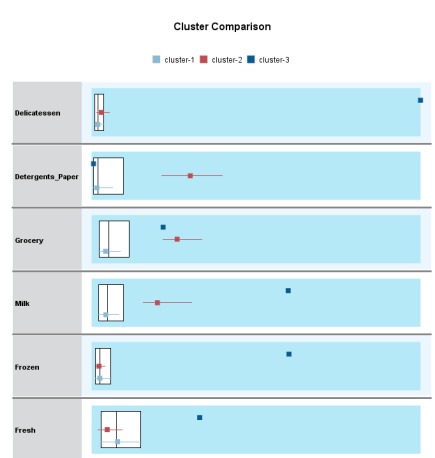
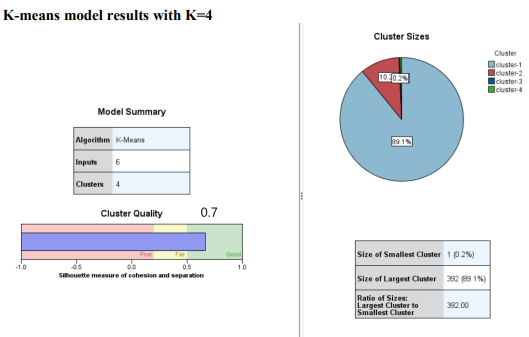
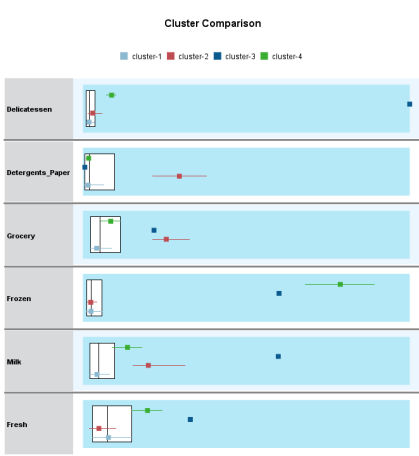
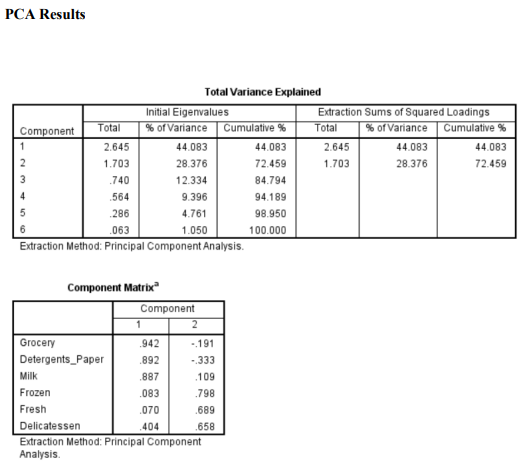
Question 1 Complete the following tasks by referring to relevant information provided in the Appendix. When necessary, state which part of the Appendix you have used to answer a question. You do not need to use the IBM SPSS Modeler software to complete the following tasks. You can generally assume that the results are obtained using default settings of the software; but you can also assume otherwise if there is sufficient information available for you to do so. (a) Based on the given dataset details and using any other information you can obtain from the Appendix, describe a potential business objective that can be achieved by applying clustering. After this, define the data mining objective. (10 marks) (b) Using relevant details given in the Appendix, discuss if there is a need to transform the variables before clustering is applied. (10 marks) (c) Someone suggested using Principal Component Analysis (PCA) on the input variables before clustering. Analyse the PCA results from the Appendix and discuss why this may or may not be a good suggestion. (10 marks) (d) Using relevant details given in the Appendix, interpret the result of the K-means model with K=2. Then, compare the results of the models with K=2,K=3 and K=4. Which model will you recommend for deployment? (10 marks) (e) Discuss any interesting correlation(s) among variables based on the output of the Graphboard Node. Then, propose one (1) predictive model that can be built based on the correlation(s). (10 marks) (f) Using relevant details given in the Appendix, state the data mining objective of the CART model. Next, identify the decision rules generated by the model and evaluate the performance of the model. (20 marks) (g) Assume that the wholesale distributor would like to develop marketing strategies targeting the Lisbon market based on the customers' buying patterns by using association analysis. With reference to Phases 3-6 of the CRISP-DM framework, discuss how the wholesale distributor can conduct this project, given that the dataset described in the Appendix has been collected. Your answer should be less than 500 words. (20 marks) h) As shown in the Appendix, the models are built using the IBM SPSS Modeler Desktop version. In your opinion, is it worthwhile for the wholesale distributor to perform analytics on a cloud platform? State two (2) reasons to support your point of view. Appendix Dataset details Name of the dataset: Wholesale_customer_data.csv Description of the dataset: The dataset refers to 440 customers of a wholesale distributor. The customers are either from the Hotel/Restaurant/Caf channel or the Retail channel, located in various regions such as Lisbon and Oporto. Each record in the dataset contains a customer's annual spending in monetary units (m.u.) on product categories, including fresh products, milk products, grocery, frozen products, detergents and paper products and delicatessen. It contains a total of 8 fields, described as follows: Other information: The dataset is originated from a larger database referred on: Abreu, N. (2011). Analise do perfil do cliente Recheio e desenvolvimento de um sistema promocional. Mestrado em Marketing, ISCTE-IUL, Lisbon. It can be accessed from: https://archive.ics.uci.edu /ml/ datasets / wholesale + customers\# C4.. - 1.-4r2 Stream built in the IBM SPSS Modeler Data audit result of the dataset Data Mudit of [8 fields] File andit Generate () IIII 'Indicates a multimode result "Indicates a sampled result F. Dats Audi of IE Seidil file generate 14 Compiote felds (W) Complete necorts (*): C Setting in the Type Node \#1 Output from the C.RR Tree Node Output from the Analysis Node Analysis of [Channel] File Edit 14 Annotations Results for output field Channel Comparing \$R-Channel with Channel - Coincidence Matrix for \$R-Channel (ro Setting in the Type Node \#2 Type Node \#2 K-means model results with K=2 Model Summary Cluster Comparison cluster-1 cluster-2 Detergents_Paper Grocery Milk Delicatessen Fresh Irozen K-means model results with K=3 Model Summary Cluster Comparison cluster-1 cluster-2 cluster-3 Delisates-8en Detergenta_Paper Grocery Milk frozen fresh K-means model results with K=4 Cluster Comparison cluster-1 cluster-2 cluster-3 dingter-4 Delicatessen Detergents_Paper Grocery Frazen Milk Fresh PCA Results Total Variance Explained Extraction Method: Principal Component Analysis. Component Matrix a Extraction Method: Principal Component Analysis




