

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
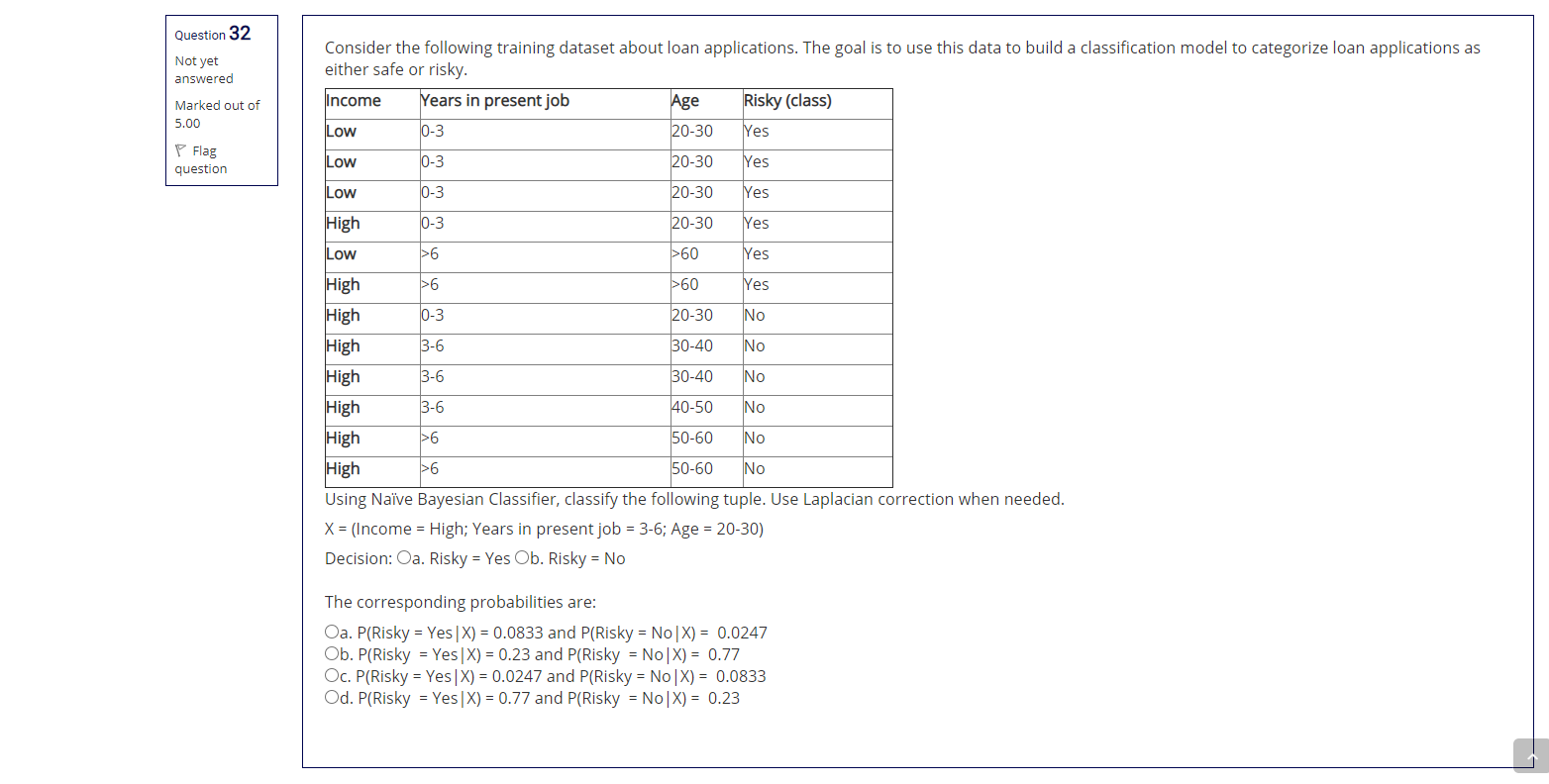
Question 32 Not yet answered Consider the following training dataset about loan applications. The goal is to use this data to build a classification model

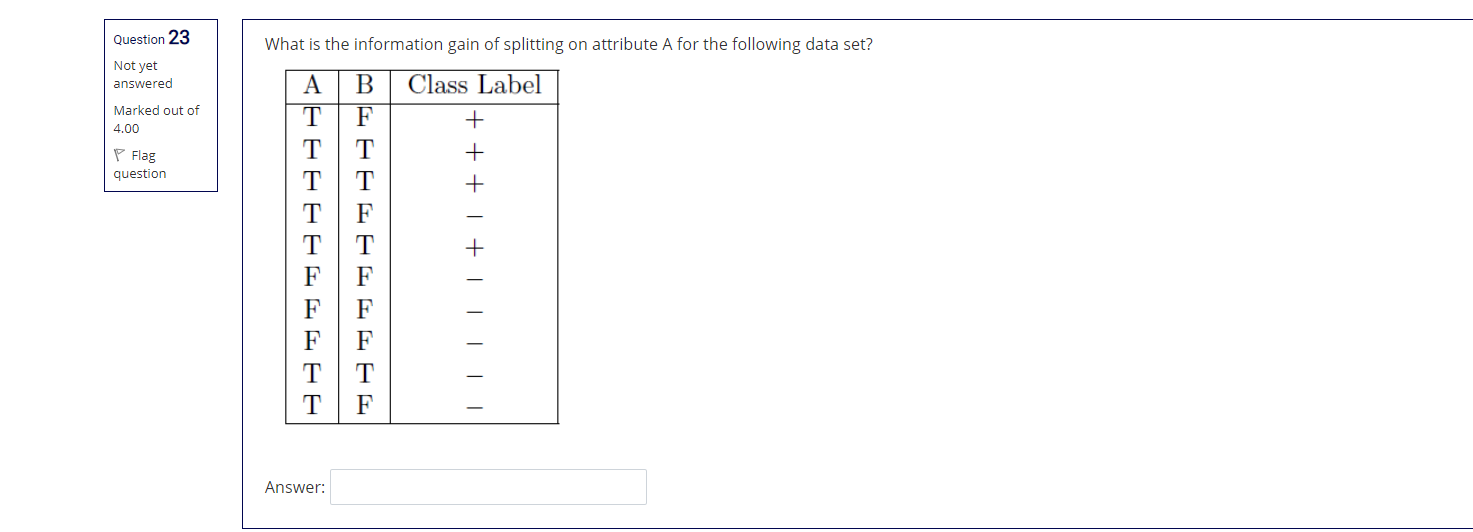
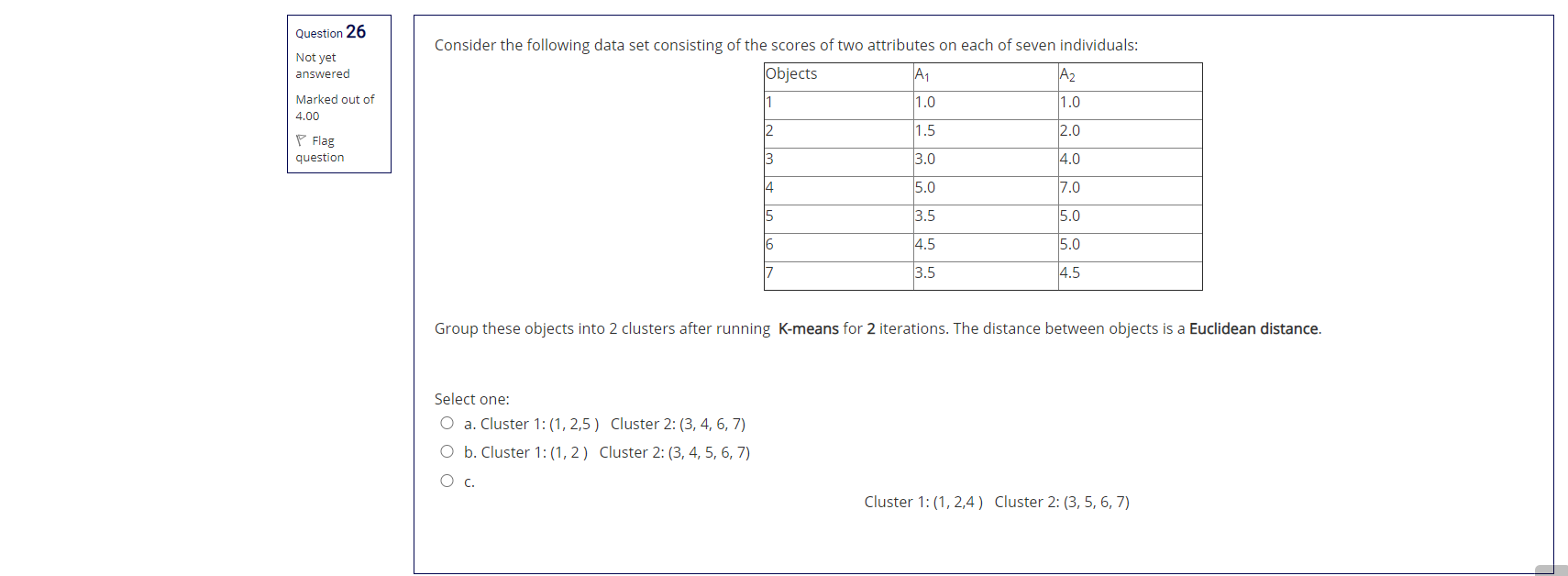
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Database Design Application And Administration
Authors: Michael Mannino, Michael V. Mannino
2nd Edition
0072880678, 9780072880670