

Question
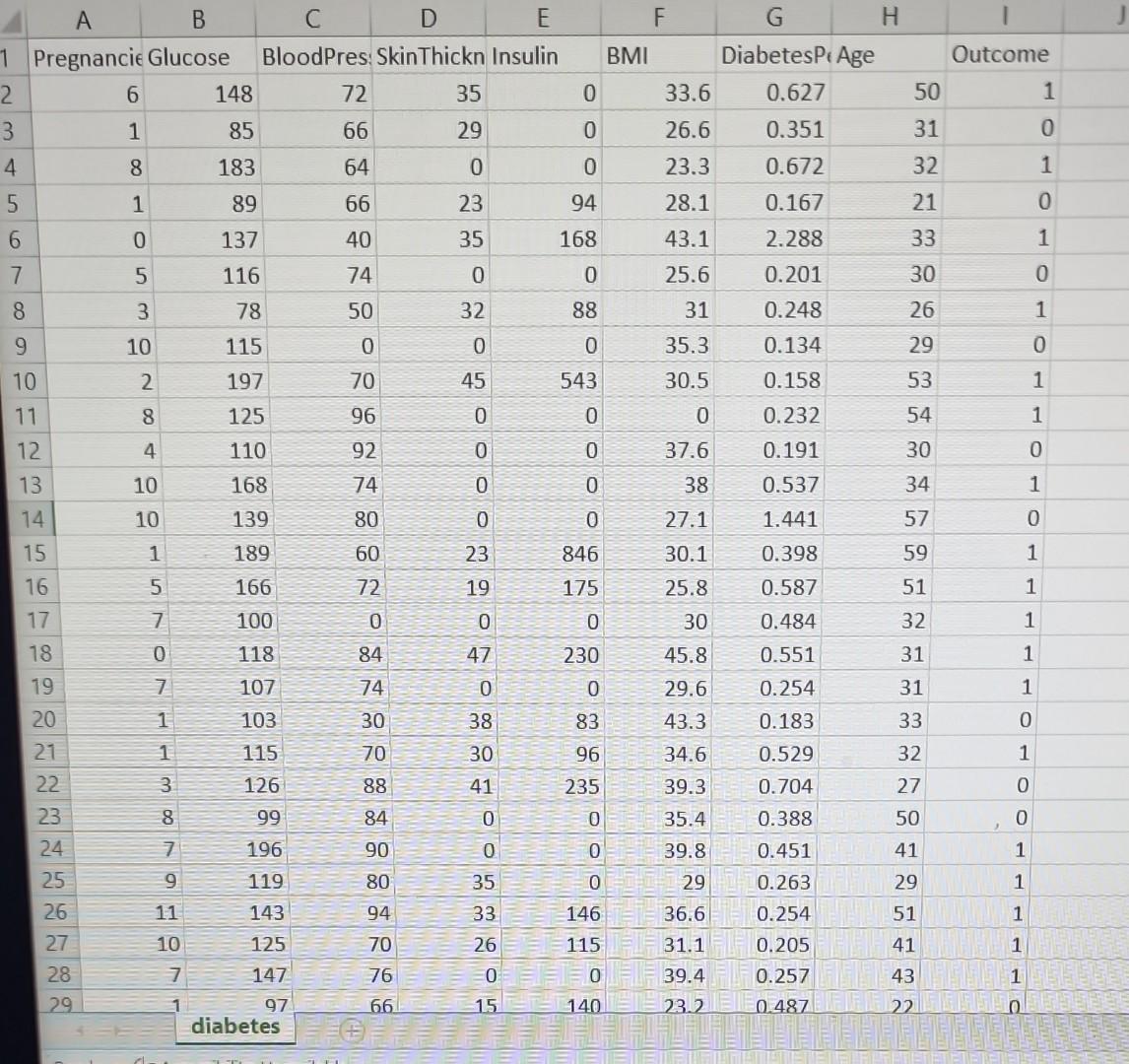
Read diabetes.csv into a Jupyter notebook. Differentiate between the independent variables and the dependent variable and assign them to variables x and y. Generate training
Read diabetes.csv into a Jupyter notebook. Differentiate between the independent variables and the dependent variable and assign them to variables x and y. Generate training and test sets comprising 80% and 20% of the data respectively. Use a MinMaxScaler and StandardScaler from sklearn.preprocessing. Fit these scalers on the train set and use these fit scalers to transform the train and test sets. Generate a multiple linear regression model using the training set. Use all of the independent variables. Print out the intercept and coefficients of the trained model Generate predictions for the test set . For these predictions, set all predicted values below 0.5 to 0 and all predicted values of 0.5 or above to 1. Compute the accuracy_score of your model on the test set. You can get the accuracy_score from sklearn.metrics.
Note. Ensure your notebook is well commented with topics and comments on what your code is accomplishing.
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started