Read the case study below and answer the following questions in a substantive manner:
1. Why are the SLA monitors important? What are the two monitors that DTGOV is using?
2. What are their roles? How important is it to ensure that these monitors and their logs are protected against manipulation?
3. What are some ways to ensure that they are protected from manipulation?

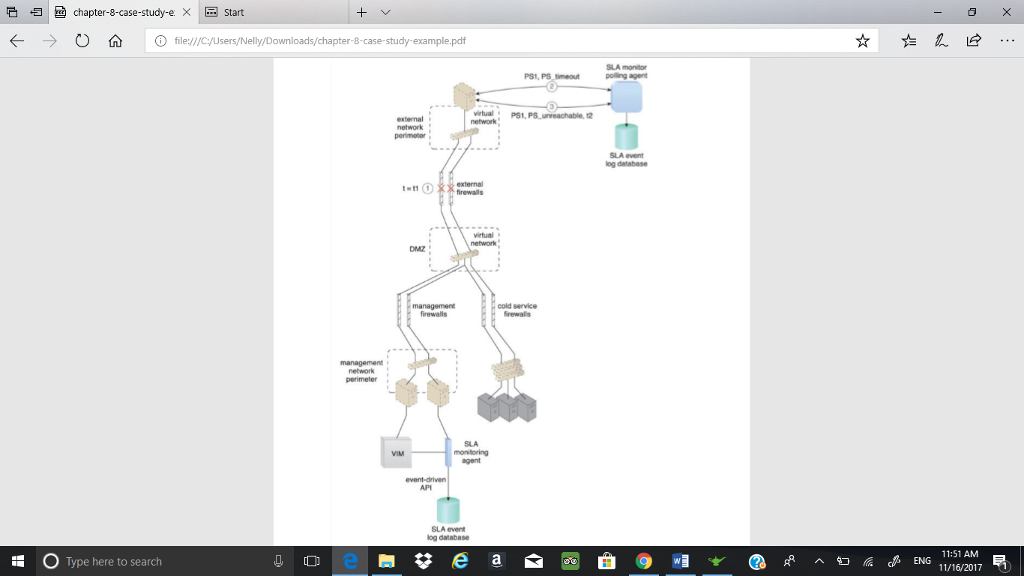
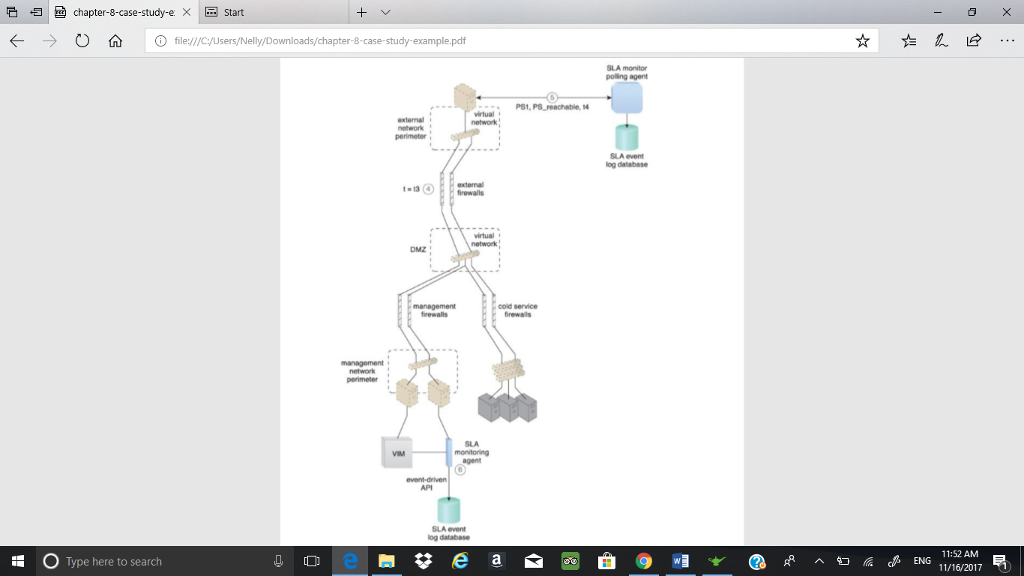
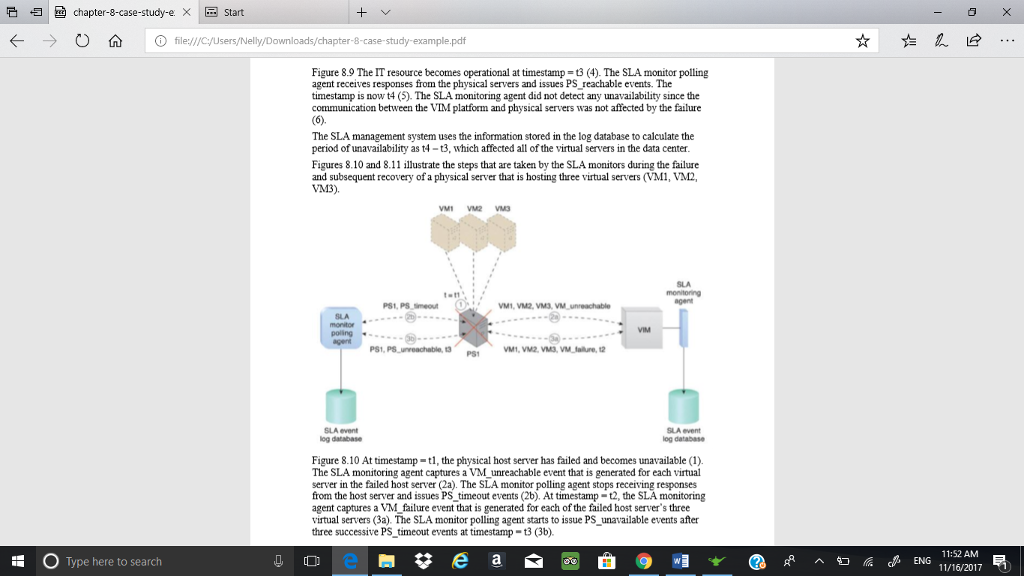
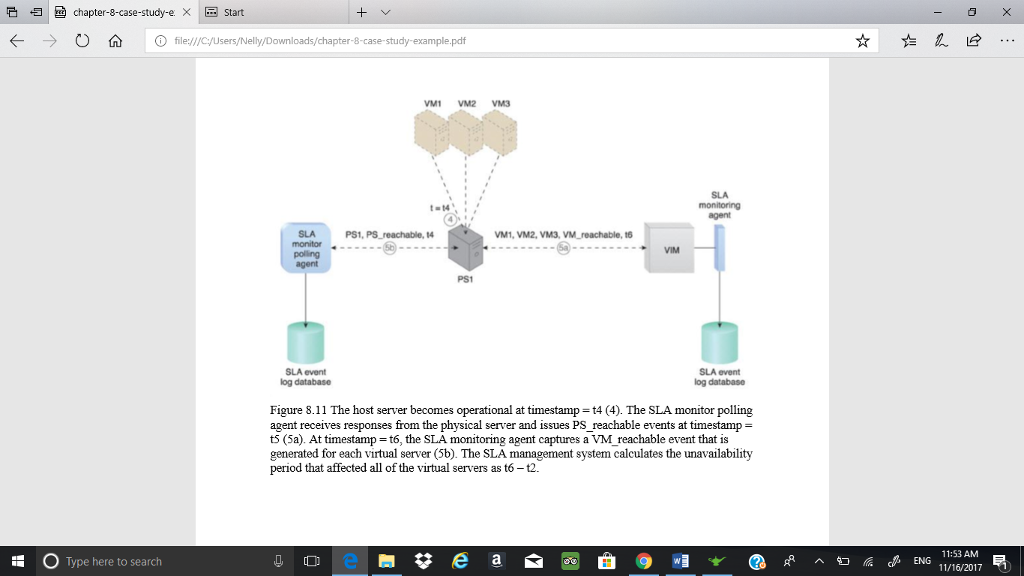
chapter-8-case-study-ex start C) file/ycyusers/Nelly/Downloads/chapter-8-case-study-example.pdf Case Study Example The standard SLA for virtual servers in DTGOV's leasing agreements defines a minimum IT resource availability of 99.95%, which is tracked using two SLA monitors: one based on a polling agent and the other based on a regular monitoring agent implementation. SLA Monitor Polling Agent DTGOV's polling SLA monitor runs in the external perimeter network to detect physical server timeouts. It is able to identify data center network, hardware, and software failures (with minute granuty) that result in physical server non-responsiveness. Three consecutive timeouts of 20 second polling periods are required to declare IT resource unavailability. Three types of events are generated PS_Timeout - the physical server polling has timed out PS_Unreachable-the physical server polling has consecutively timed out three times PS_Reachable the previously unavailable physical server becomes responsive to polling again SLA Monitoring Agent The VIM's event-driven API implements the SLA monitor as a monitoring agent to generate the following three events: .VM Unreachable the VIM cannot reach the VMM VM Failure the VM has failed and is unavailable . VM Reachable-the VM is reachable The events generated by the polling agent have timestamps that are logged into an SLA event log database and used by the SLAmanagement system to calculate IT resource availability. Complex rules are used to correlate events from different polling SLA monitors and the affected virtual servers, and to discard any false positives for periods of unavailability. Figures 8.8 and 8.9 show the steps taken by SLA monitors during a data center network failure and recovery O Type here to search 11:50 AM 11/16/2017 chapter-8-case-study-ex start C) file/ycyusers/Nelly/Downloads/chapter-8-case-study-example.pdf Case Study Example The standard SLA for virtual servers in DTGOV's leasing agreements defines a minimum IT resource availability of 99.95%, which is tracked using two SLA monitors: one based on a polling agent and the other based on a regular monitoring agent implementation. SLA Monitor Polling Agent DTGOV's polling SLA monitor runs in the external perimeter network to detect physical server timeouts. It is able to identify data center network, hardware, and software failures (with minute granuty) that result in physical server non-responsiveness. Three consecutive timeouts of 20 second polling periods are required to declare IT resource unavailability. Three types of events are generated PS_Timeout - the physical server polling has timed out PS_Unreachable-the physical server polling has consecutively timed out three times PS_Reachable the previously unavailable physical server becomes responsive to polling again SLA Monitoring Agent The VIM's event-driven API implements the SLA monitor as a monitoring agent to generate the following three events: .VM Unreachable the VIM cannot reach the VMM VM Failure the VM has failed and is unavailable . VM Reachable-the VM is reachable The events generated by the polling agent have timestamps that are logged into an SLA event log database and used by the SLAmanagement system to calculate IT resource availability. Complex rules are used to correlate events from different polling SLA monitors and the affected virtual servers, and to discard any false positives for periods of unavailability. Figures 8.8 and 8.9 show the steps taken by SLA monitors during a data center network failure and recovery O Type here to search 11:50 AM 11/16/2017




