

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
Source Code: (Please if instructions can be provided because I am struggling with this problem. It is in C++ which i do not have much


 Source Code:
Source Code:
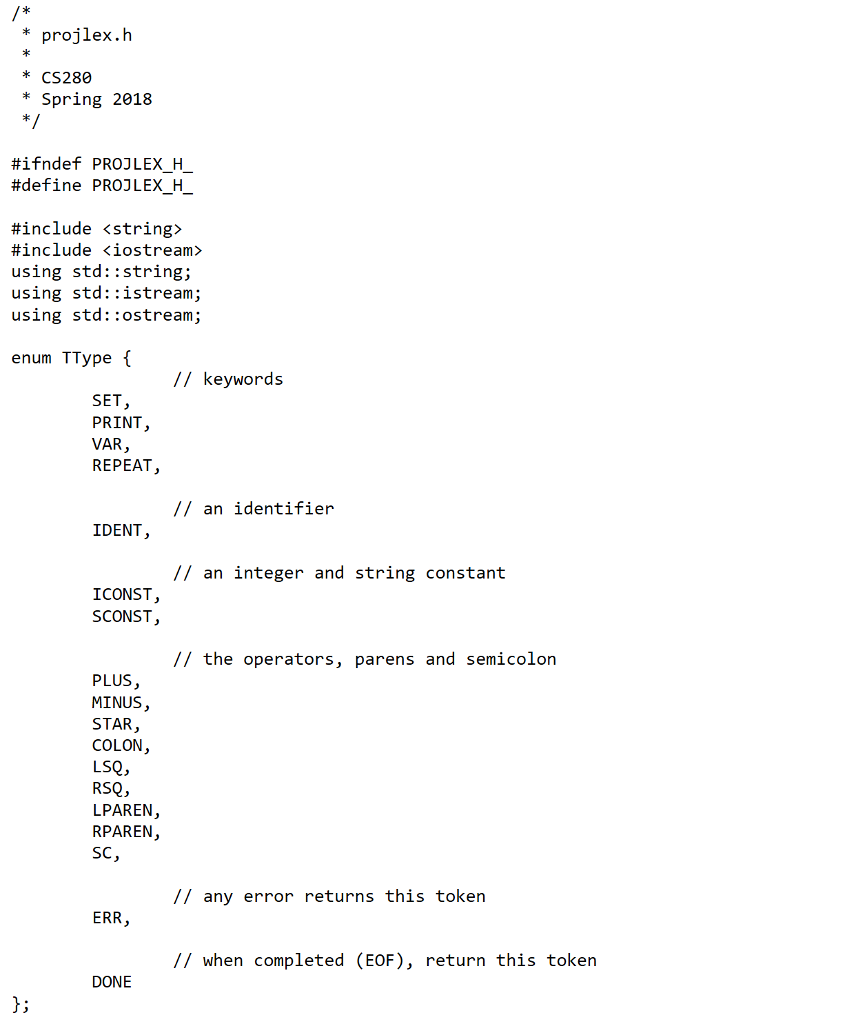

(Please if instructions can be provided because I am struggling with this problem. It is in C++ which i do not have much experience on. I only need help in part 1. Thank You)
For the lexical analyzer, you will be provided with a description of the lexical syntax of the language. You will produce a lexical analysis function and a program to test it. The lexical analyzer function will have the following calling signature: Token getNextToken (istream *in, int *linenumber) ; The first argument to getNextToken is a pointer to an istream that the function should read from. The second argument to getNextToken is a pointer to an integer that contains the current line number. getNextToken will update this integer every time it reads a new line. getNextToken returns a Token. A Token is a class that contains a TType, a string for the lexeme, and the line number that the token was found on. A header file, projlex.h, will be provided for you. You MUST use the provided header file. You may NOT change it. The lexical rules of the language are as follows: . The language has identifiers, which are defined to be a letter followed by zero or more letters or numbers. This will be the token IDENT. The language has integer constants, which are defined to be an optional leading dash (for a negative number), followed by one or more digits. This will be the token ICONST. iii. The language has string constants, which are a double-quoted sequence of characters, all on the same line. This will be the token SCONST. The language has reserved the keywords var, print, set, and repeat. They will be the tokens VAR, PRINT, SET, and REPEAT. The language has several single-character tokens. They are + -*:[](); which will be the tokens PLUS MINUS STAR COLON LSQ RSQ LPAREN RPAREN SC. vi. A comment is all characters from a # to the end of the line; it is ignored and is not returned as a token. NOTE that a # in the middle of an SCONST is NOT a comment! vii. Whitespace between tokens can be used for readability. It serves to delimit tokens. viii. The newline should be recognized so that lines can be counted. ix. An error will be denoted by the ERR token. X. End of file will be denoted by the DONE token. V. Note that any error detected by the lexical analyzer will result in the ERR token, with the lexeme value equal to the string recognized when the error was detected. For the lexical analyzer, you will be provided with a description of the lexical syntax of the language. You will produce a lexical analysis function and a program to test it. The lexical analyzer function will have the following calling signature: Token getNextToken (istream *in, int *linenumber) ; The first argument to getNextToken is a pointer to an istream that the function should read from. The second argument to getNextToken is a pointer to an integer that contains the current line number. getNextToken will update this integer every time it reads a new line. getNextToken returns a Token. A Token is a class that contains a TType, a string for the lexeme, and the line number that the token was found on. A header file, projlex.h, will be provided for you. You MUST use the provided header file. You may NOT change it. The lexical rules of the language are as follows: . The language has identifiers, which are defined to be a letter followed by zero or more letters or numbers. This will be the token IDENT. The language has integer constants, which are defined to be an optional leading dash (for a negative number), followed by one or more digits. This will be the token ICONST. iii. The language has string constants, which are a double-quoted sequence of characters, all on the same line. This will be the token SCONST. The language has reserved the keywords var, print, set, and repeat. They will be the tokens VAR, PRINT, SET, and REPEAT. The language has several single-character tokens. They are + -*:[](); which will be the tokens PLUS MINUS STAR COLON LSQ RSQ LPAREN RPAREN SC. vi. A comment is all characters from a # to the end of the line; it is ignored and is not returned as a token. NOTE that a # in the middle of an SCONST is NOT a comment! vii. Whitespace between tokens can be used for readability. It serves to delimit tokens. viii. The newline should be recognized so that lines can be counted. ix. An error will be denoted by the ERR token. X. End of file will be denoted by the DONE token. V. Note that any error detected by the lexical analyzer will result in the ERR token, with the lexeme value equal to the string recognized when the error was detectedStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Beginning PostgreSQL On The Cloud Simplifying Database As A Service On Cloud Platforms
Authors: Baji Shaik ,Avinash Vallarapu
1st Edition
1484234464, 978-1484234464