

Question
The dataset bls.csv contains the median weekly earnings of full-time wage and salary workers by detailed occupation and sex. The data is structured as comma-separated
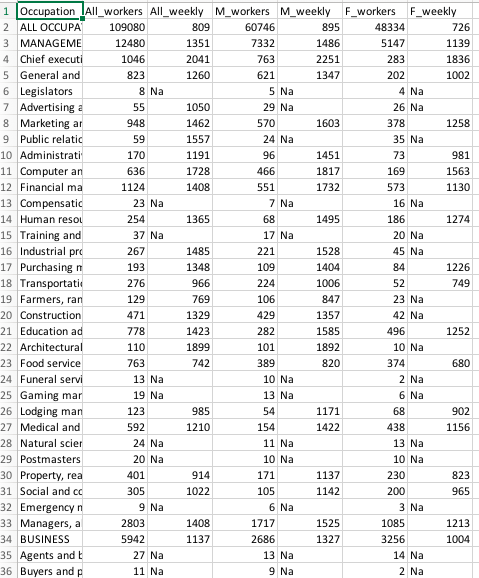
The dataset "bls.csv" contains the median weekly earnings of full-time wage and salary workers by detailed occupation and sex. The data is structured as comma-separated values (CSV). Each row has seven fields: Occupation: Job title as given from BLS. Industry summaries are given in ALL CAPS. All_workers: Number of workers male and female, in thousands. All_weekly: Median weekly income including male and female workers, in USD. M_workers: Number of male workers, in thousands. M_weekly: Median weekly income for male workers, in USD. F_workers: Number of female workers, in thousands. F_weekly: Median weekly income for female workers, in USD.
part 1:Create a dataframe that contains only the industry data (i.e., excluding the rows that are about occupations) and assign it to the variable industries. Notes: In the Occupation column, industries are designated by upper case letters. Occupations(types of jobs) are mixed case. Use this distinction to help you answer subquestion a. You may find the df.loc function helpful
Create a data frame with the ones in capitals only like ALL OCCUPATIONS, MANAGEMENT, BUSINESS etc. You should end up with less than 23 rows.
1 Occupation IAll_workers All_weekly M_workers M_weekly F_workers F_weekly 7 48334 9 12480 7332 26 Na 24 Na 1 7 1 16 Na 6 9 1 24 Na 2686 2 11 NaStep by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Fundamentals Of Database Systems
Authors: Sham Navathe,Ramez Elmasri
5th Edition
B01FGJTE0Q, 978-0805317558