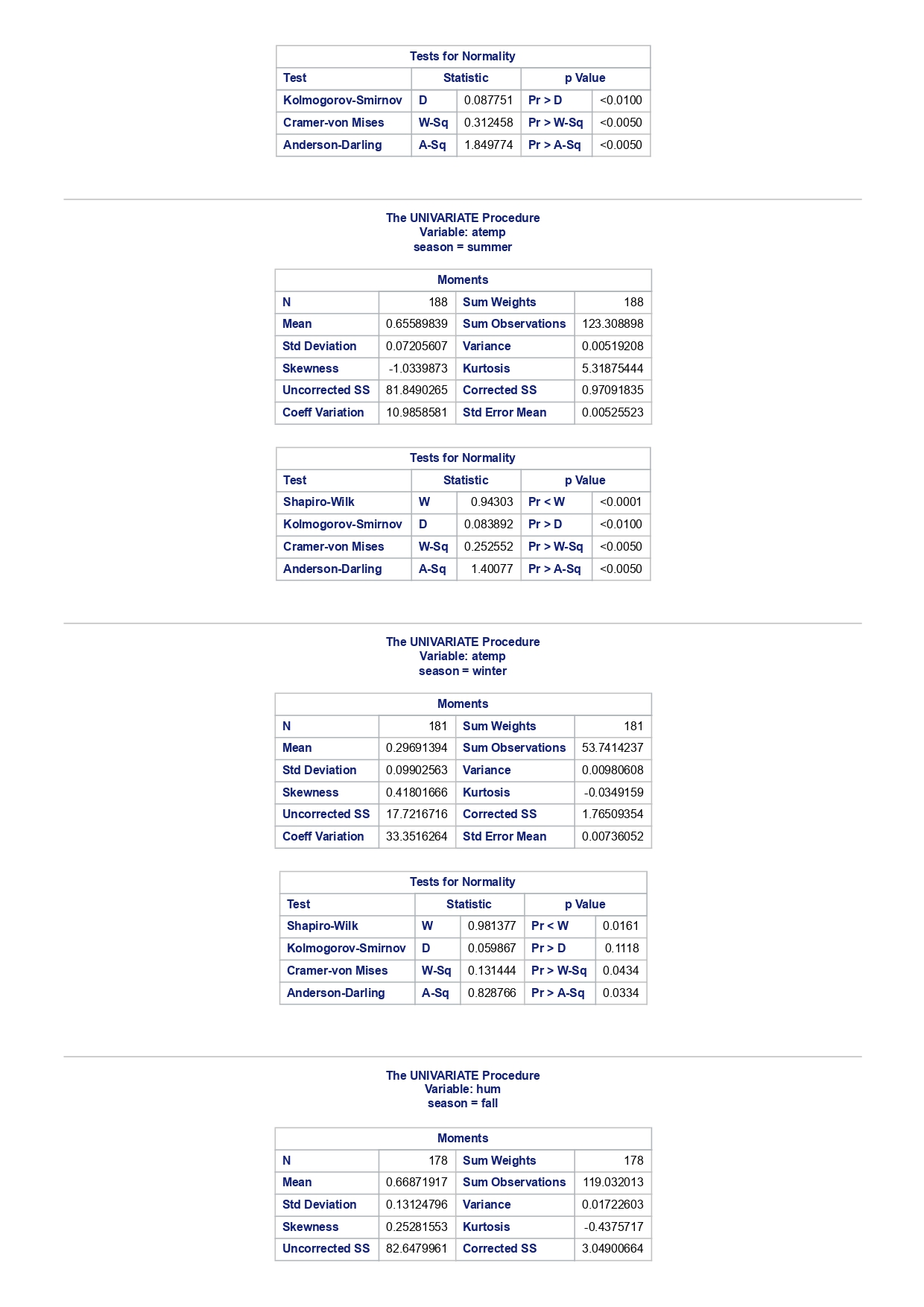
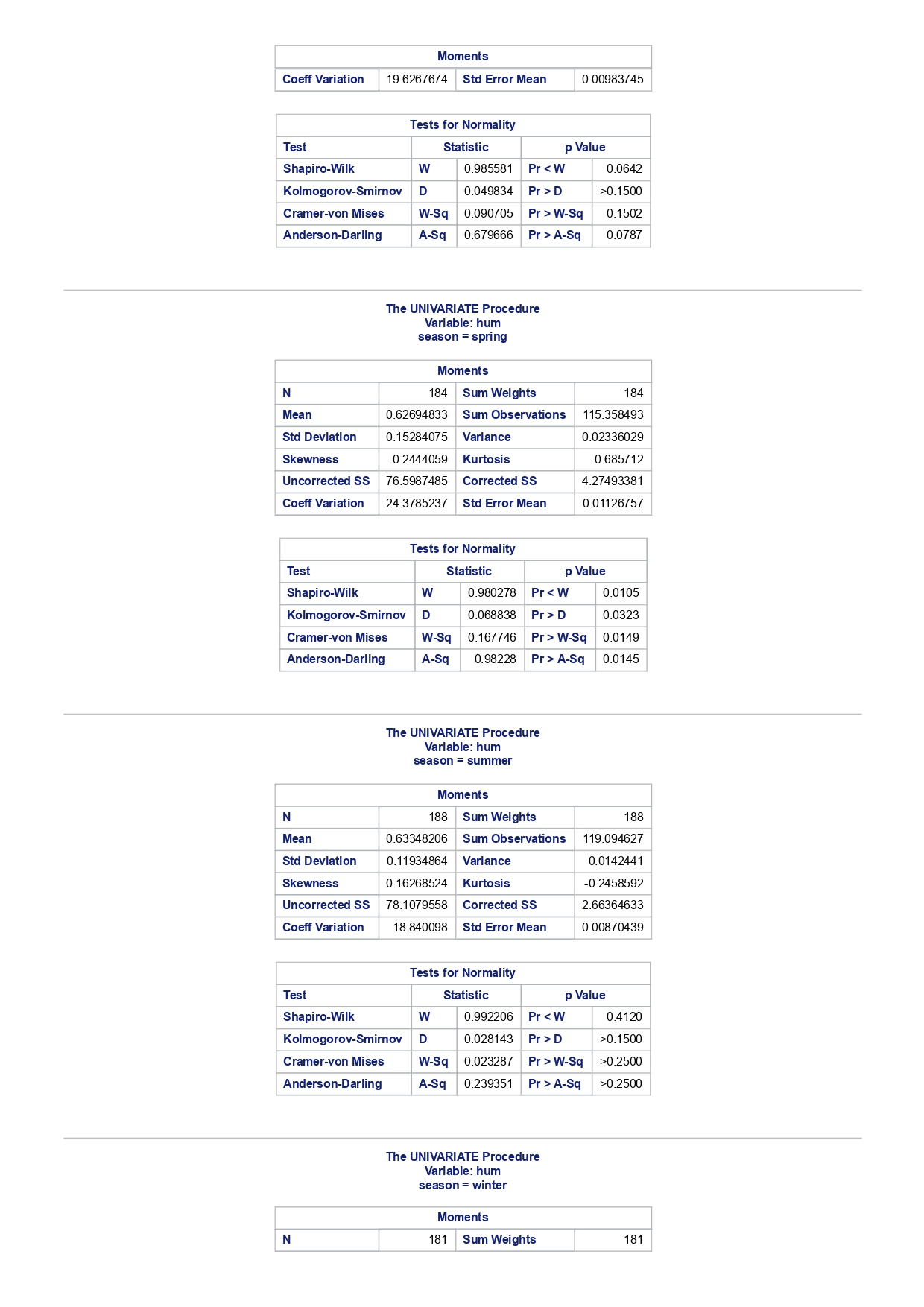
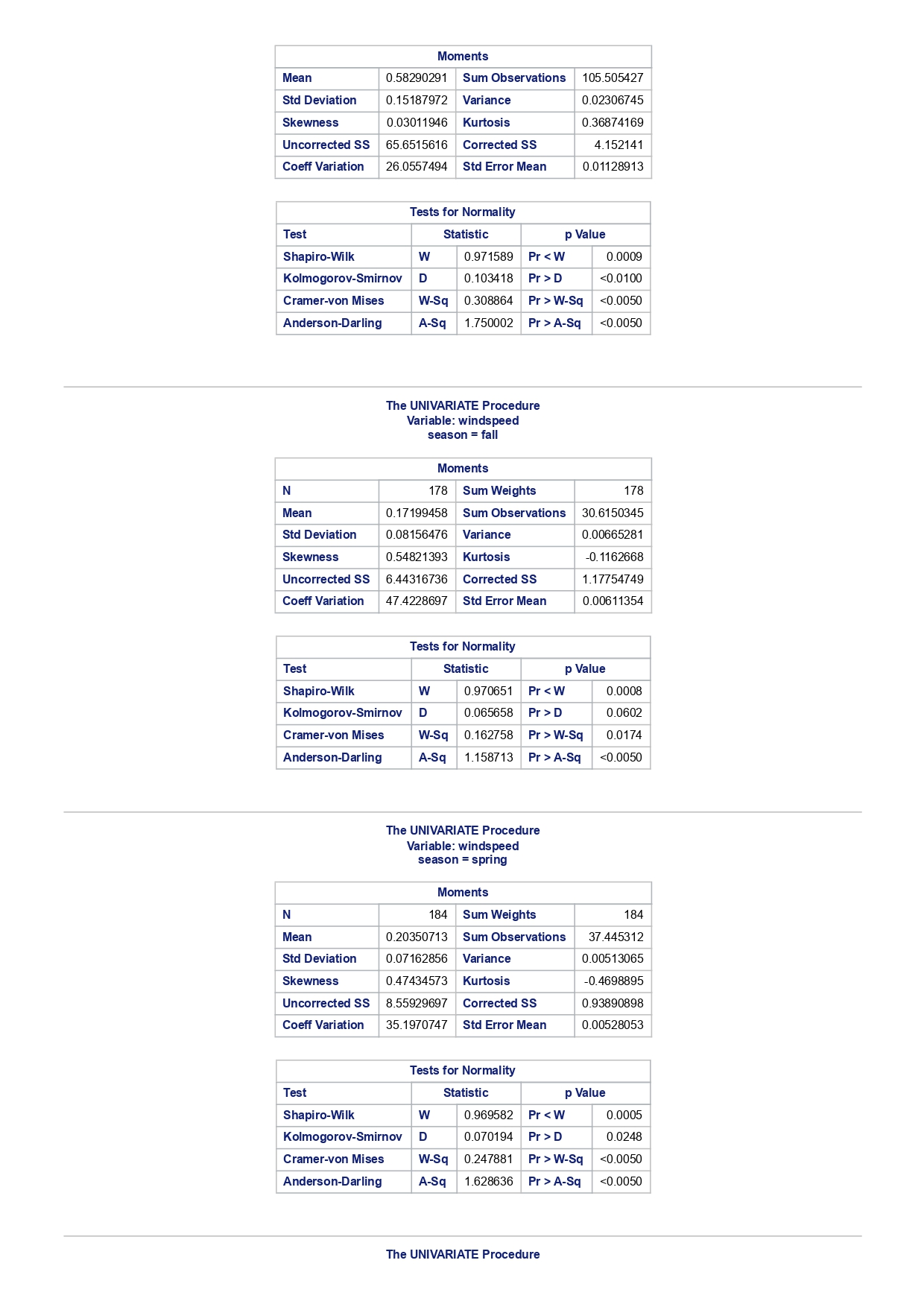
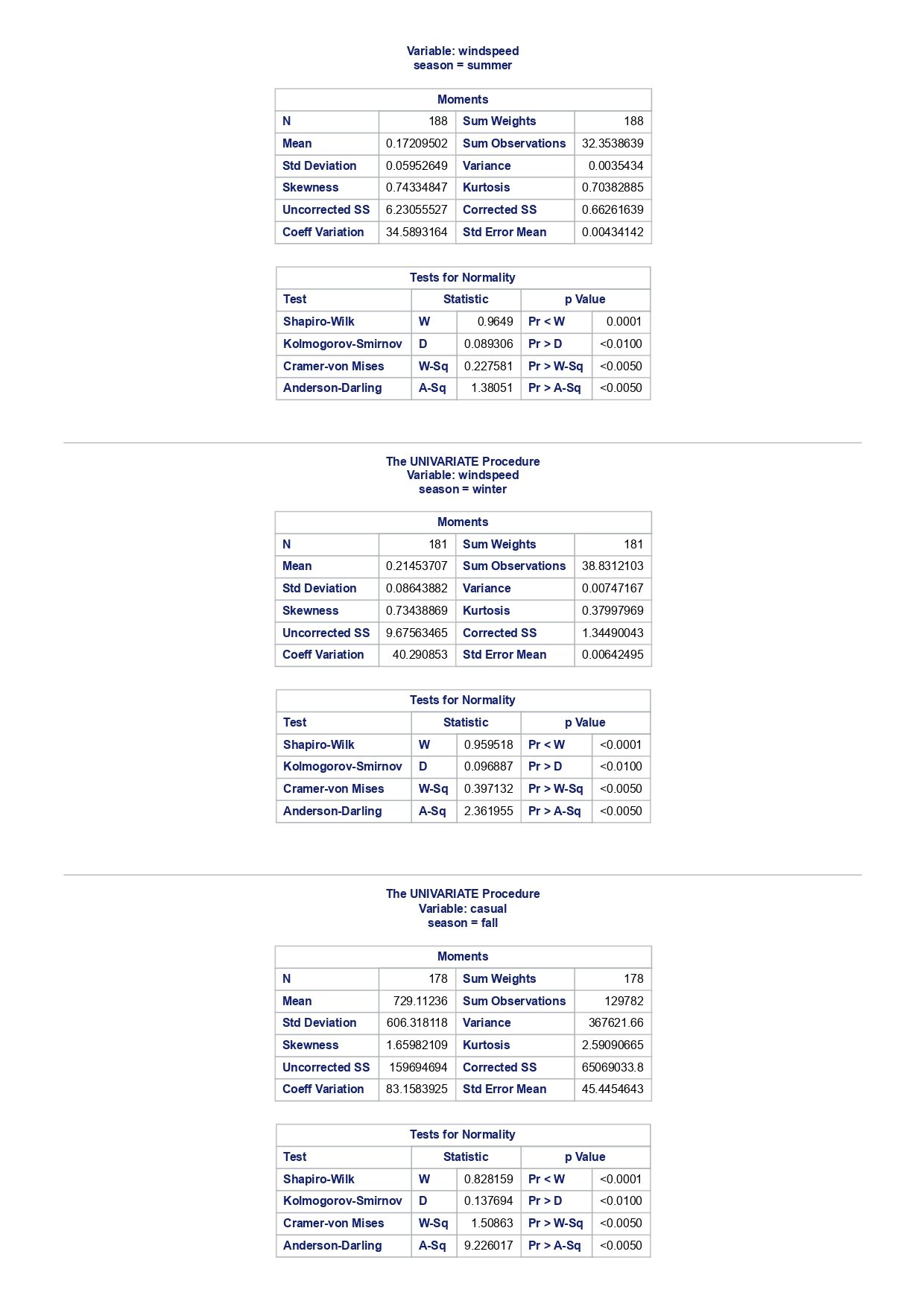
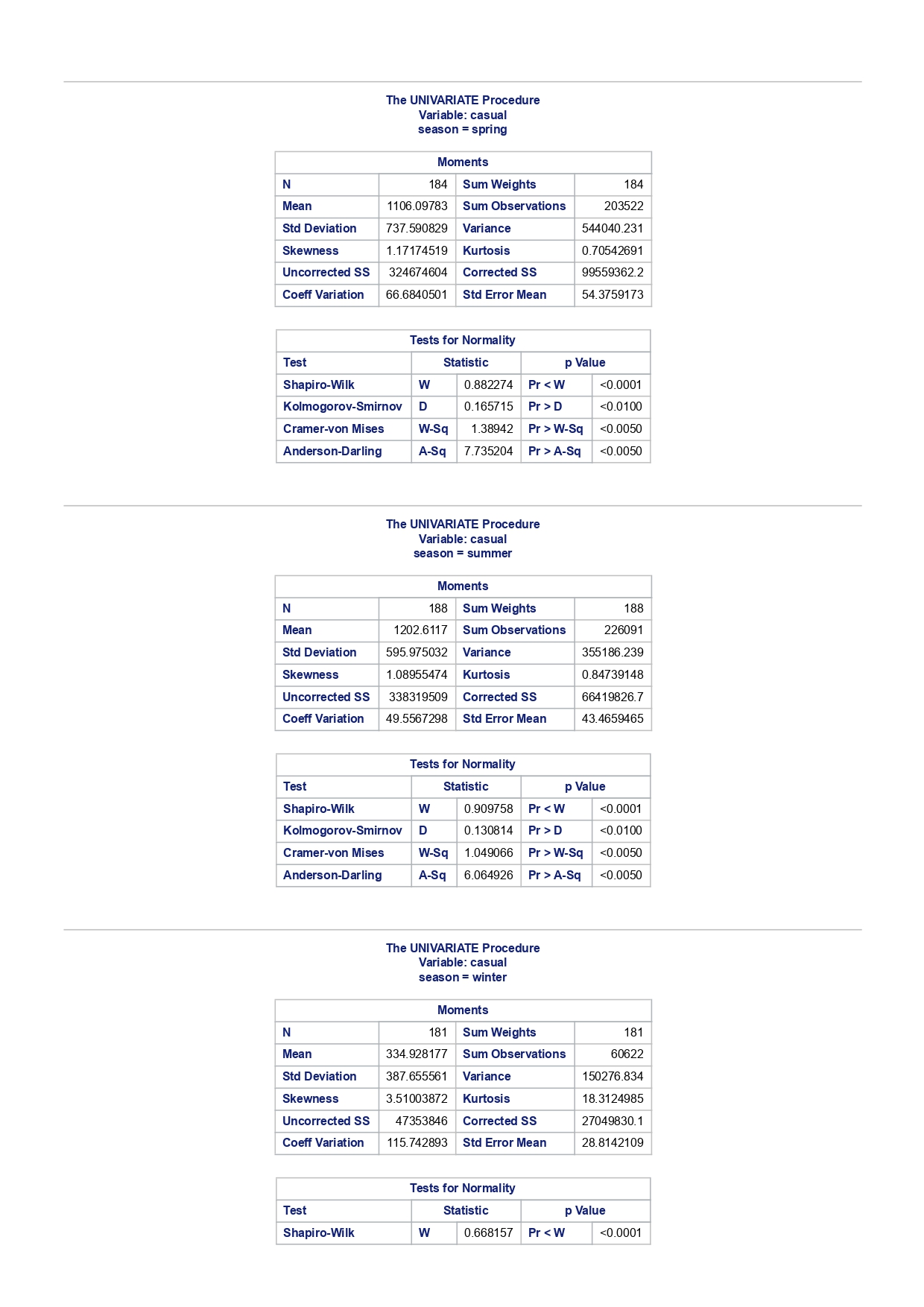
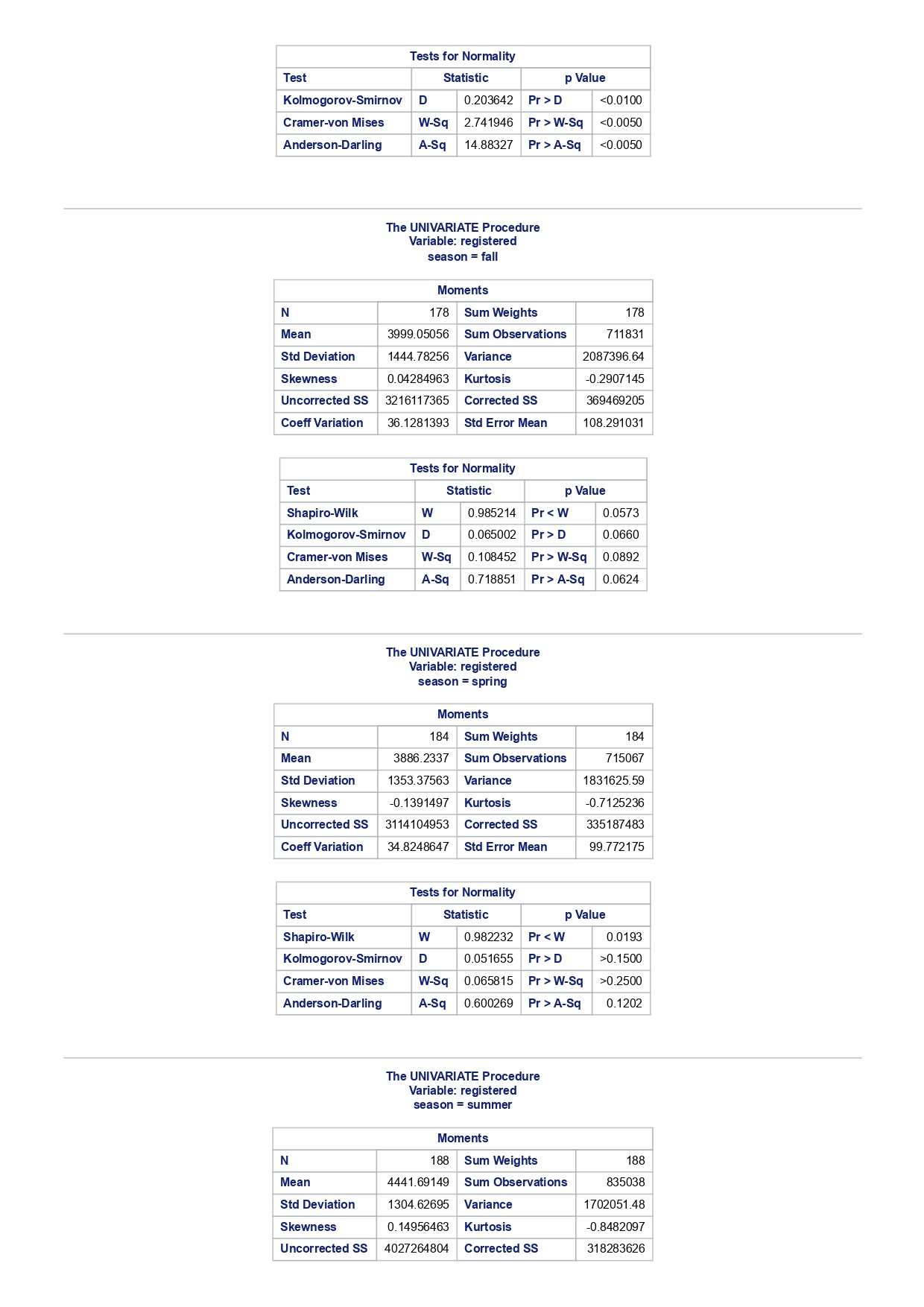
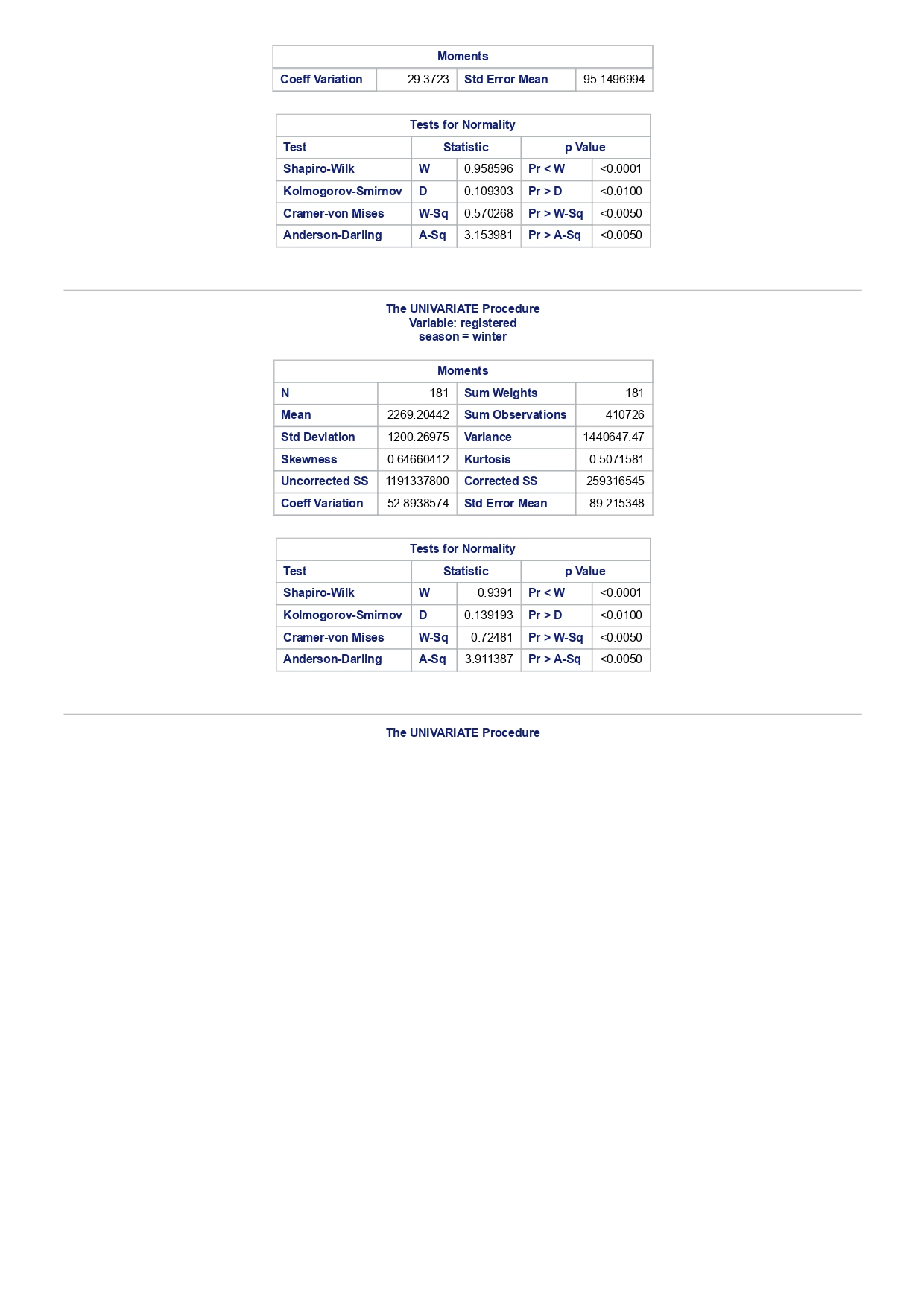
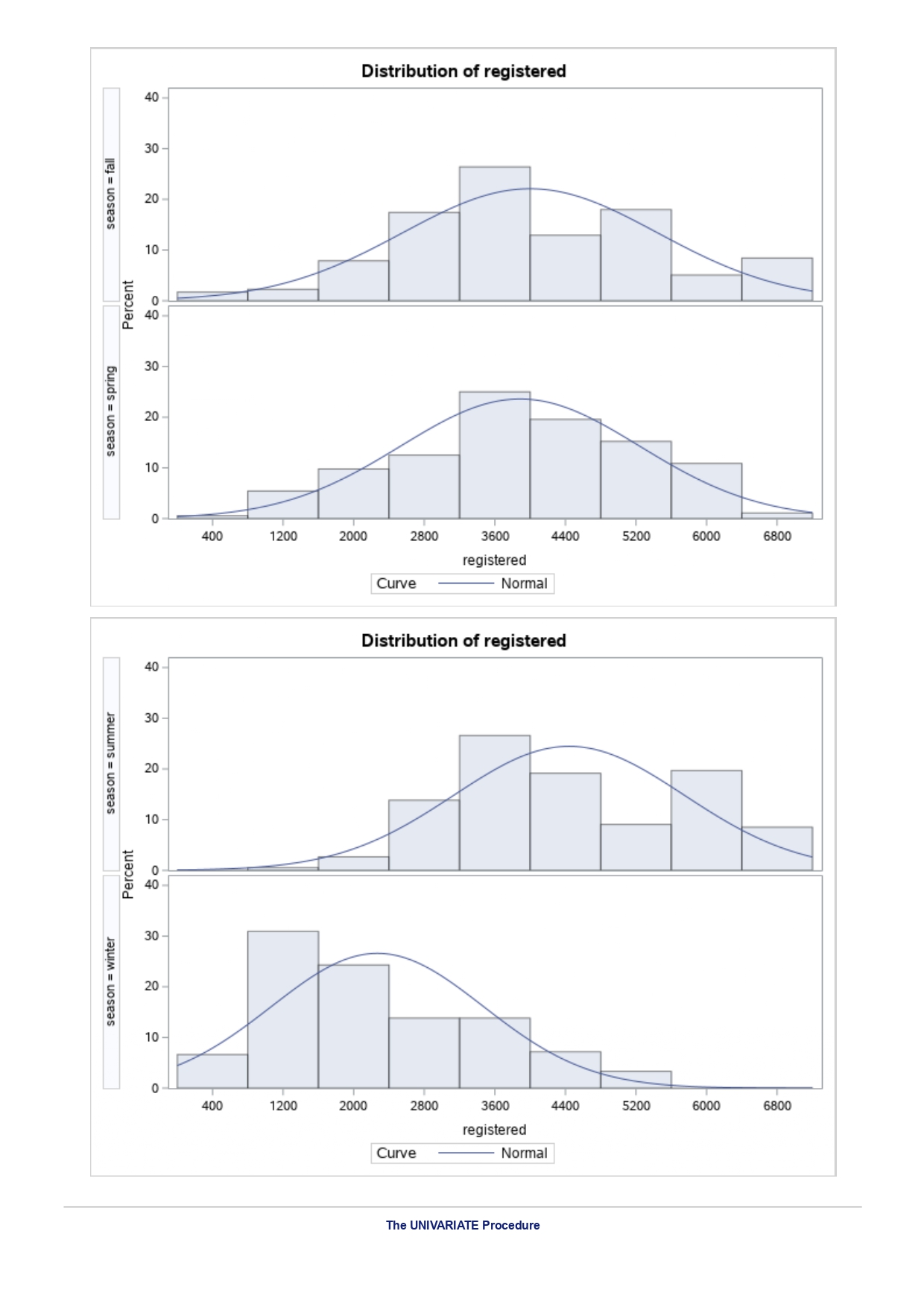
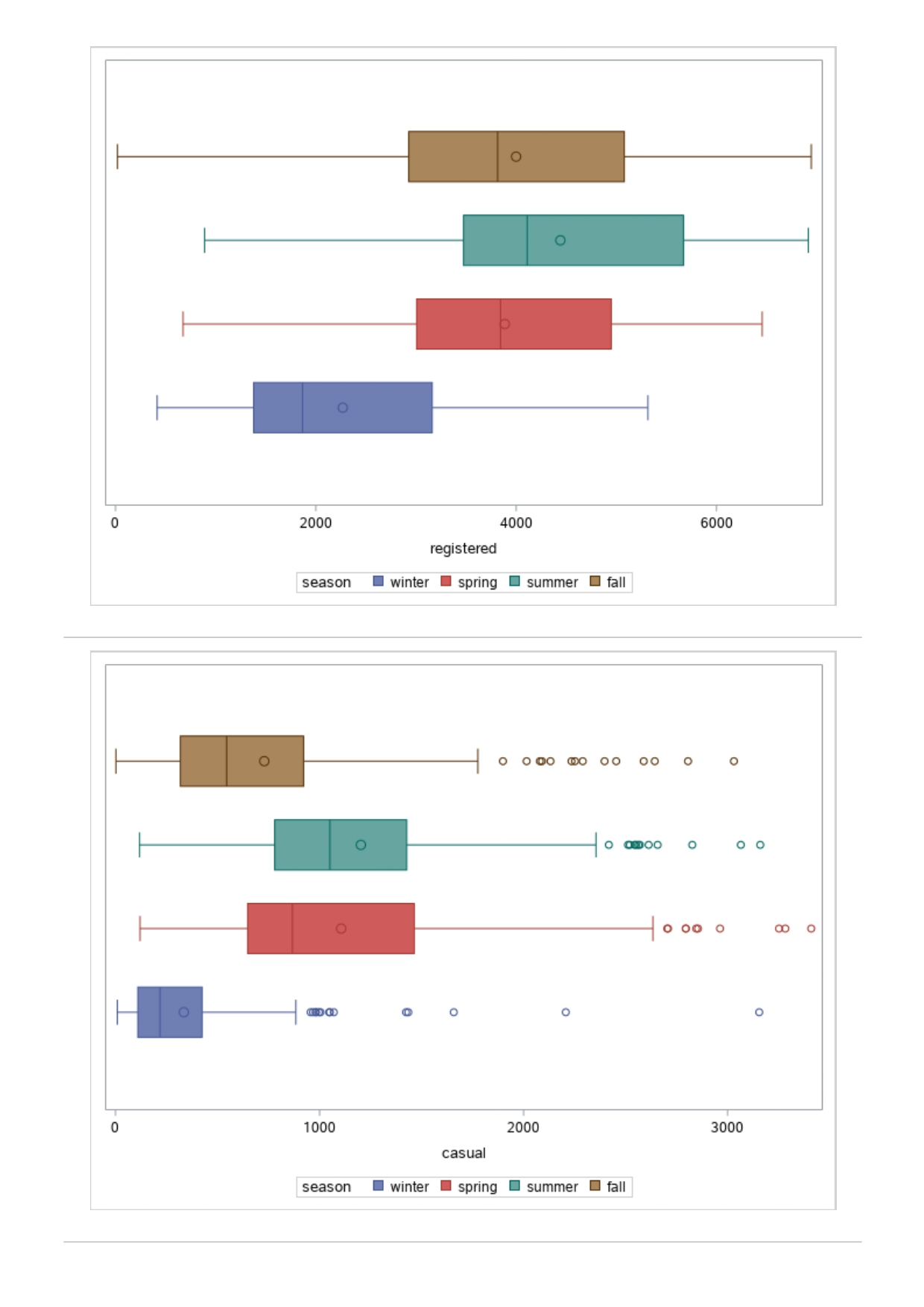
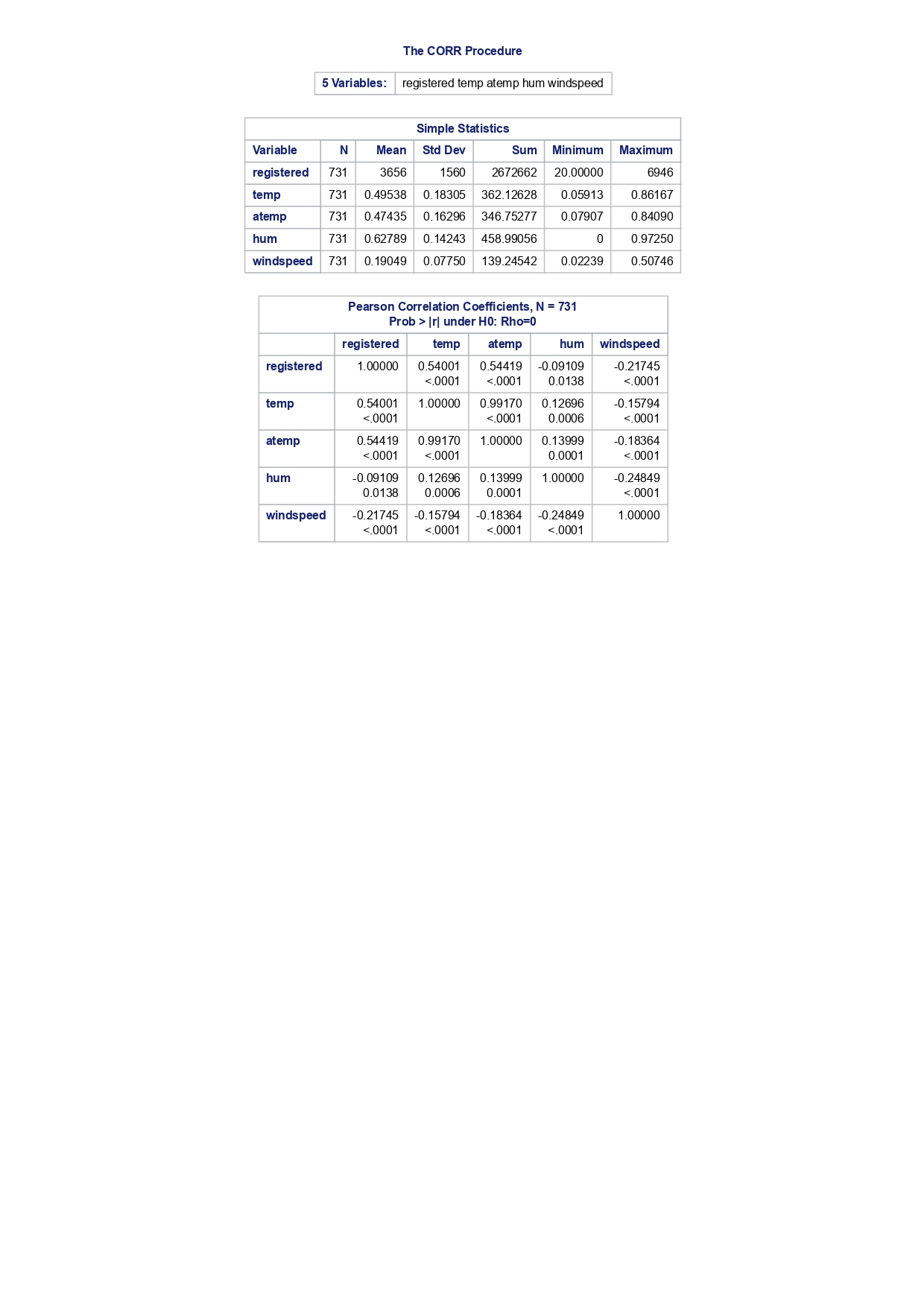
The MEANS Procedure Analysis Variable : registered Lower 95% Upper 95% N Obs N Mean Minimum Maximum Skewness Kurtosis CL for Mean CL for Mean
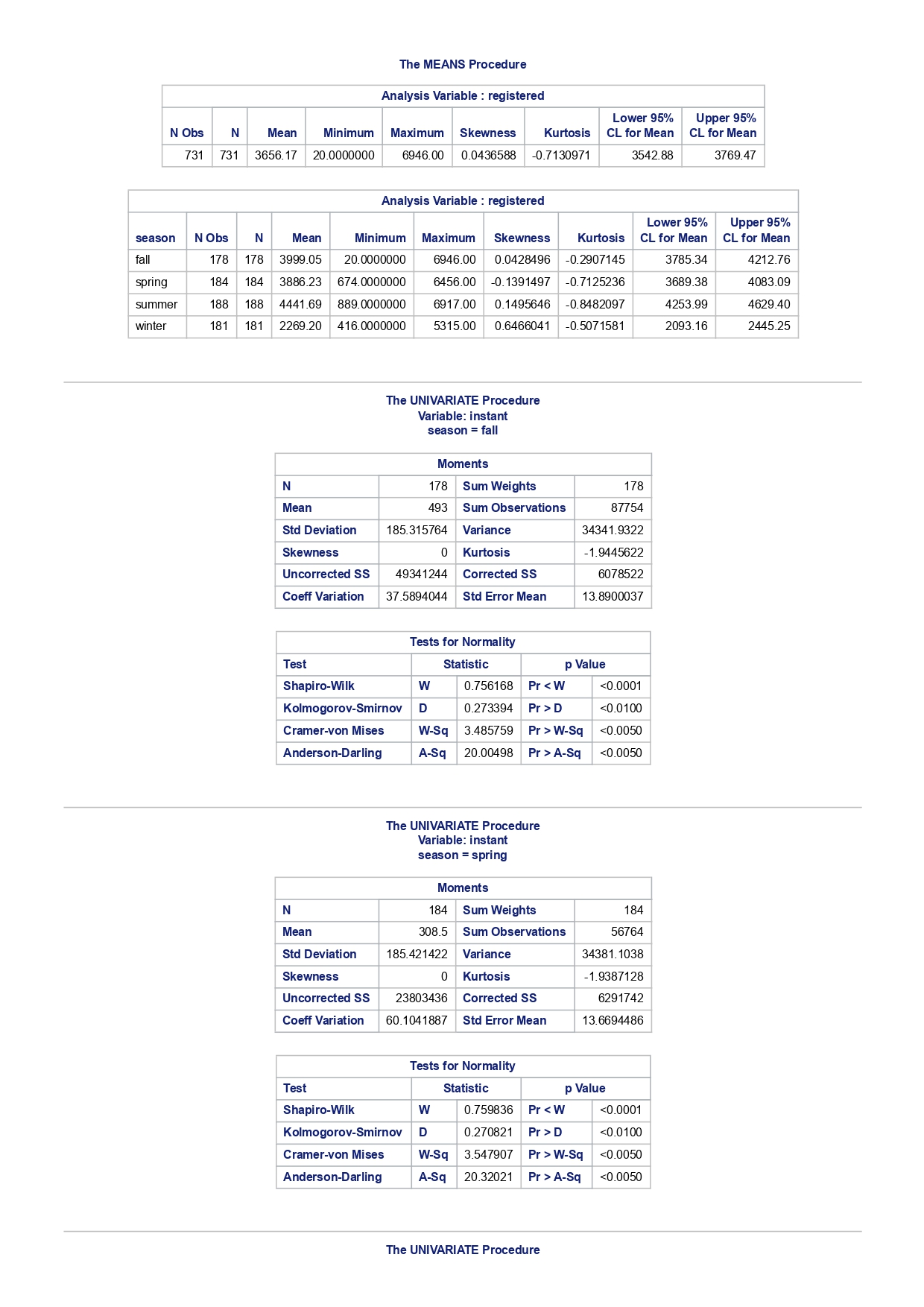
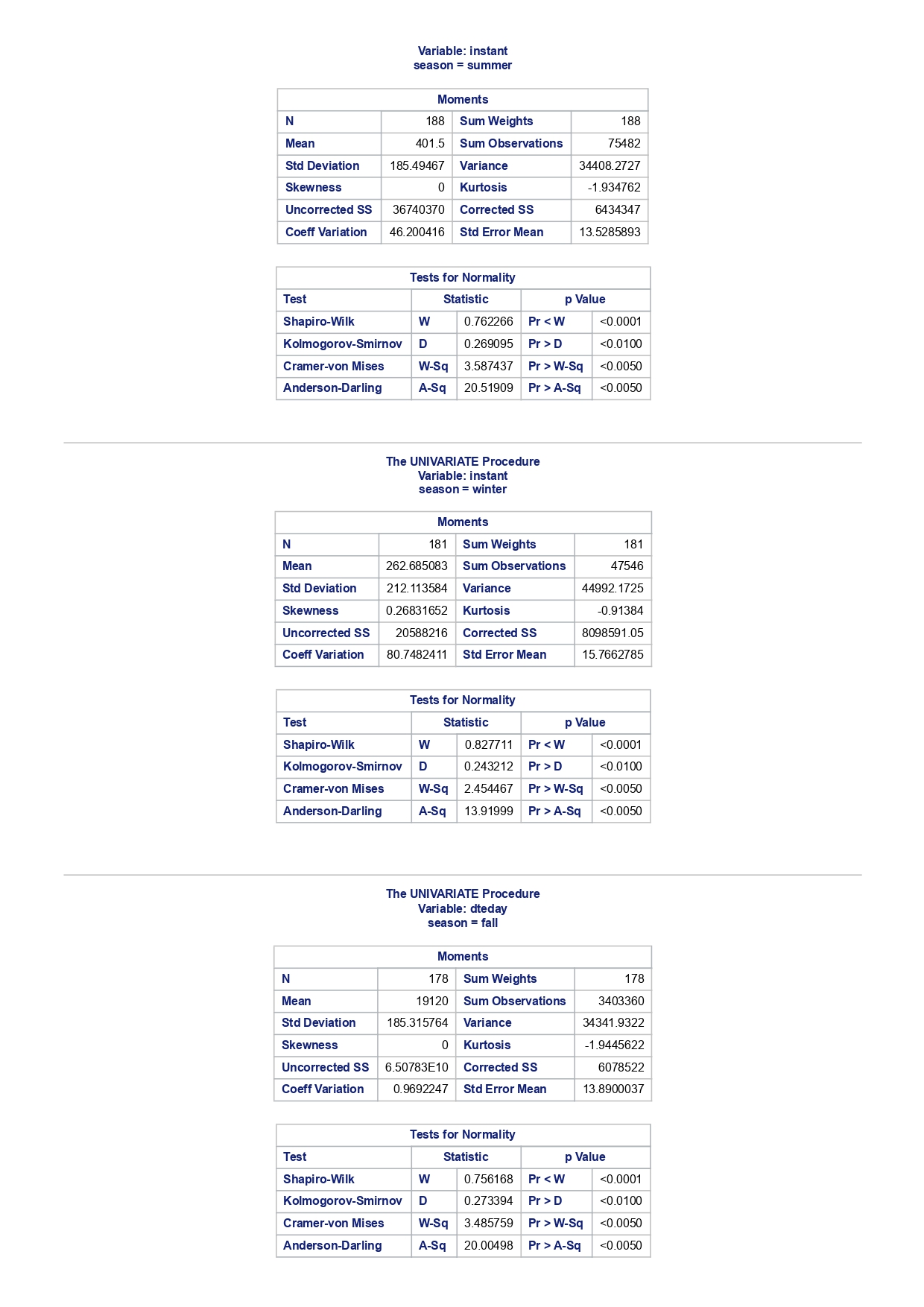
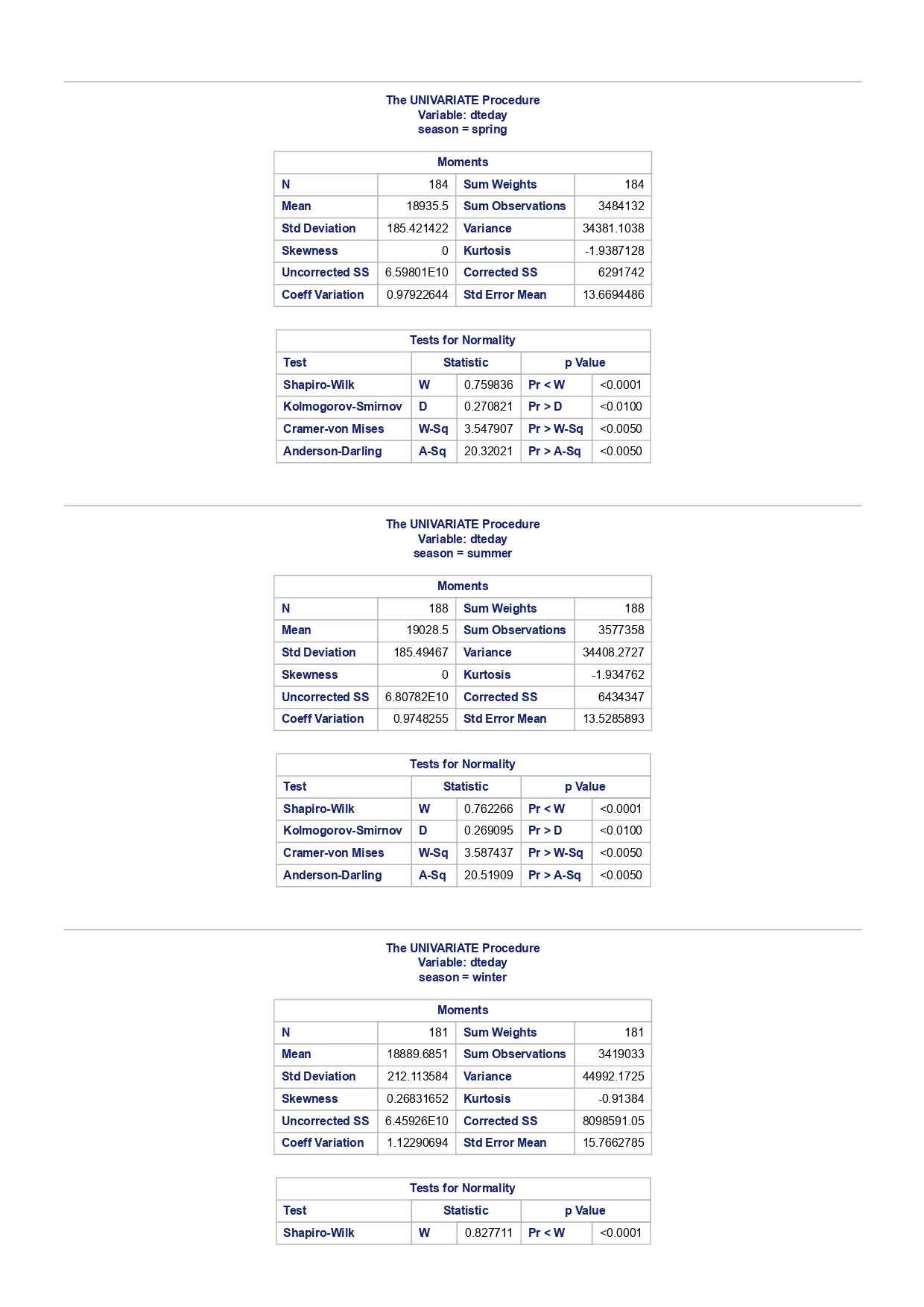
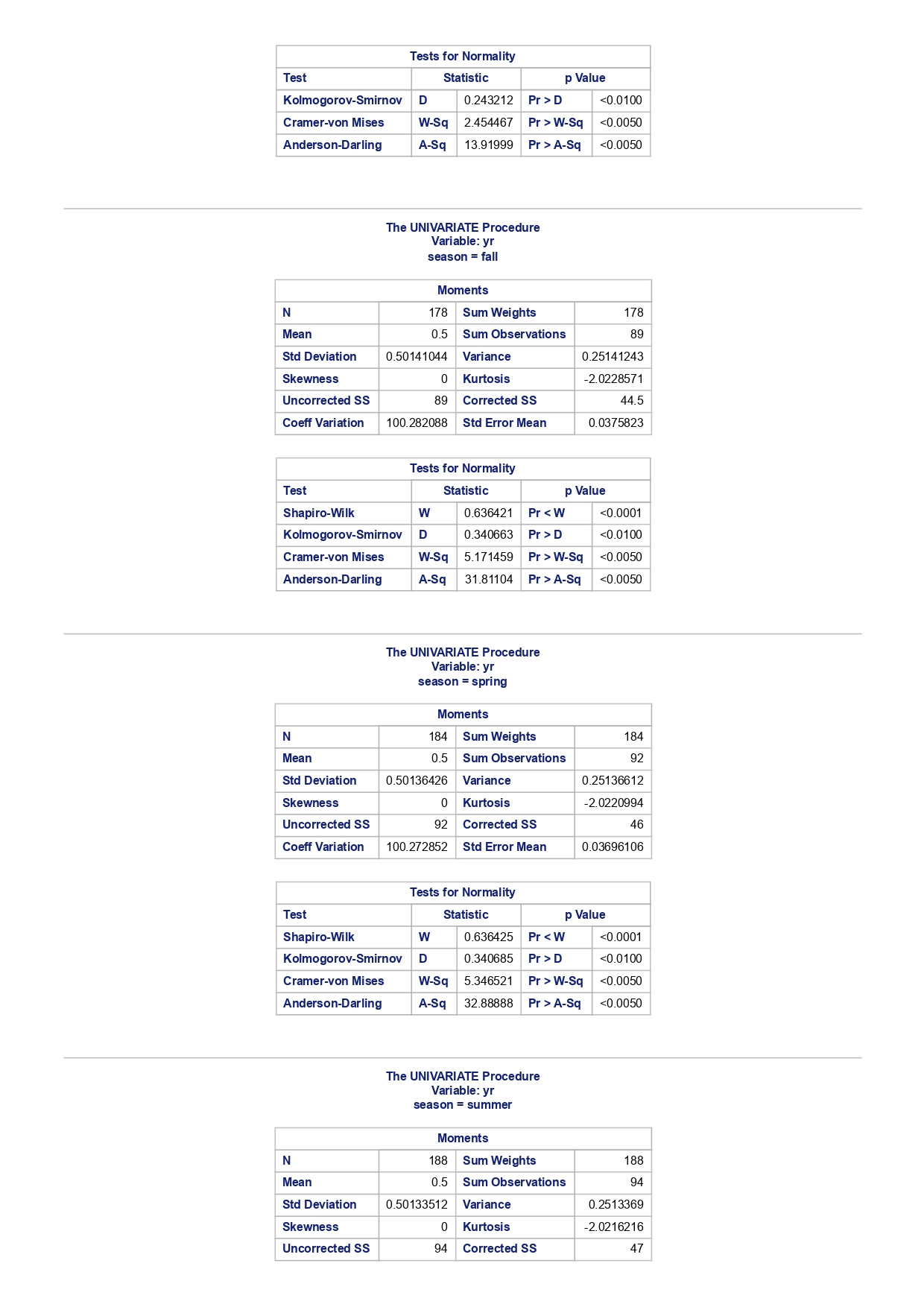
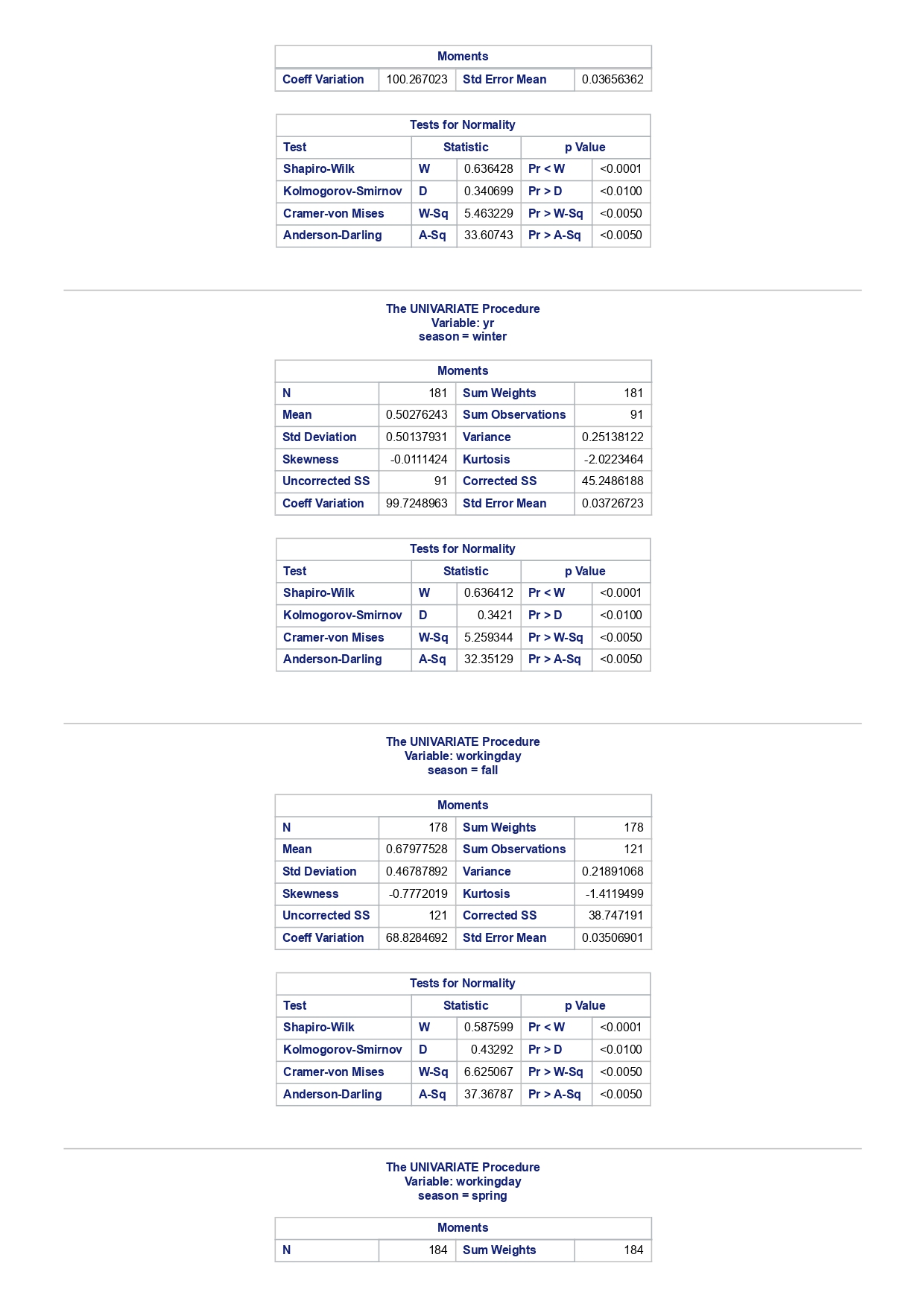
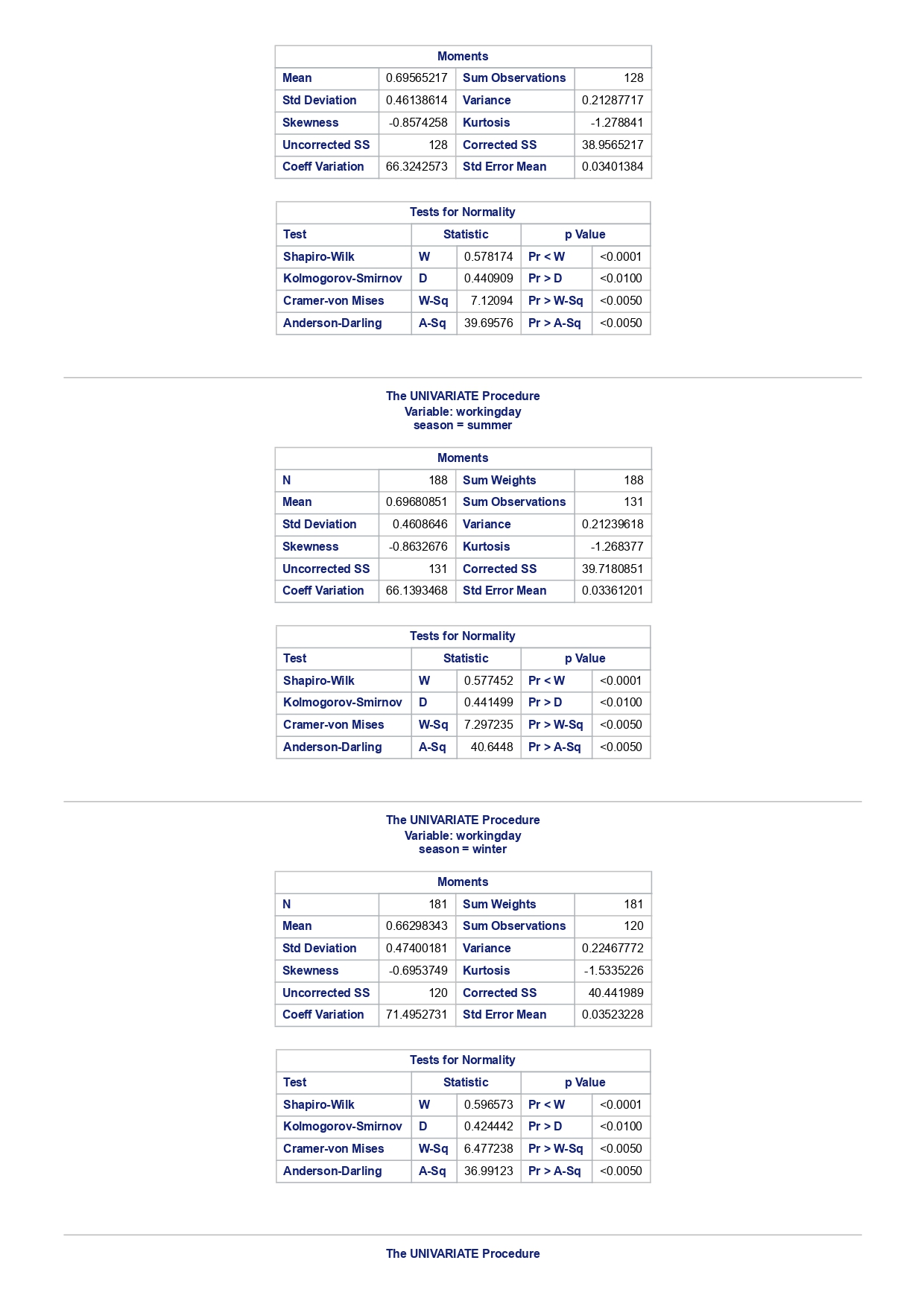
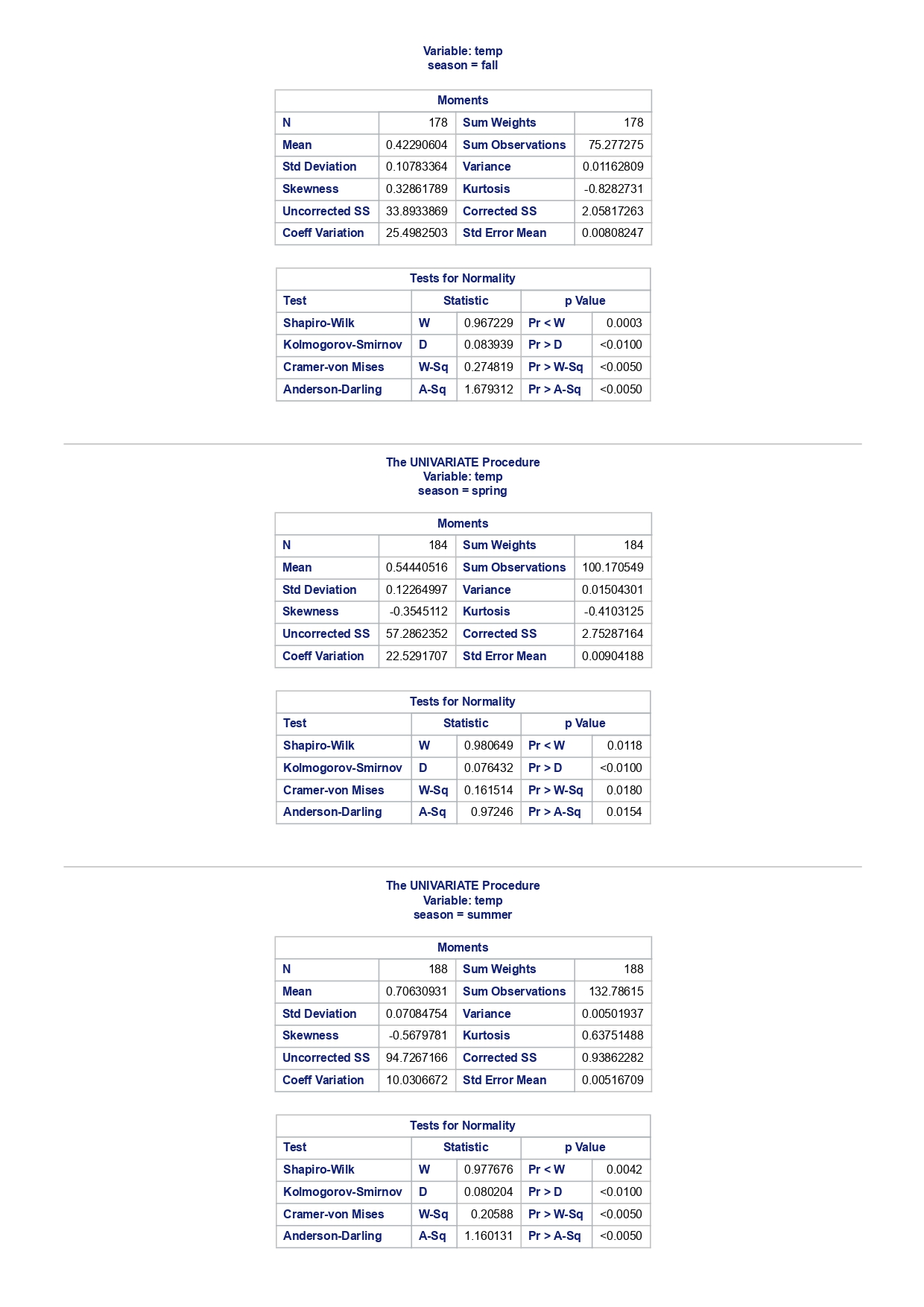
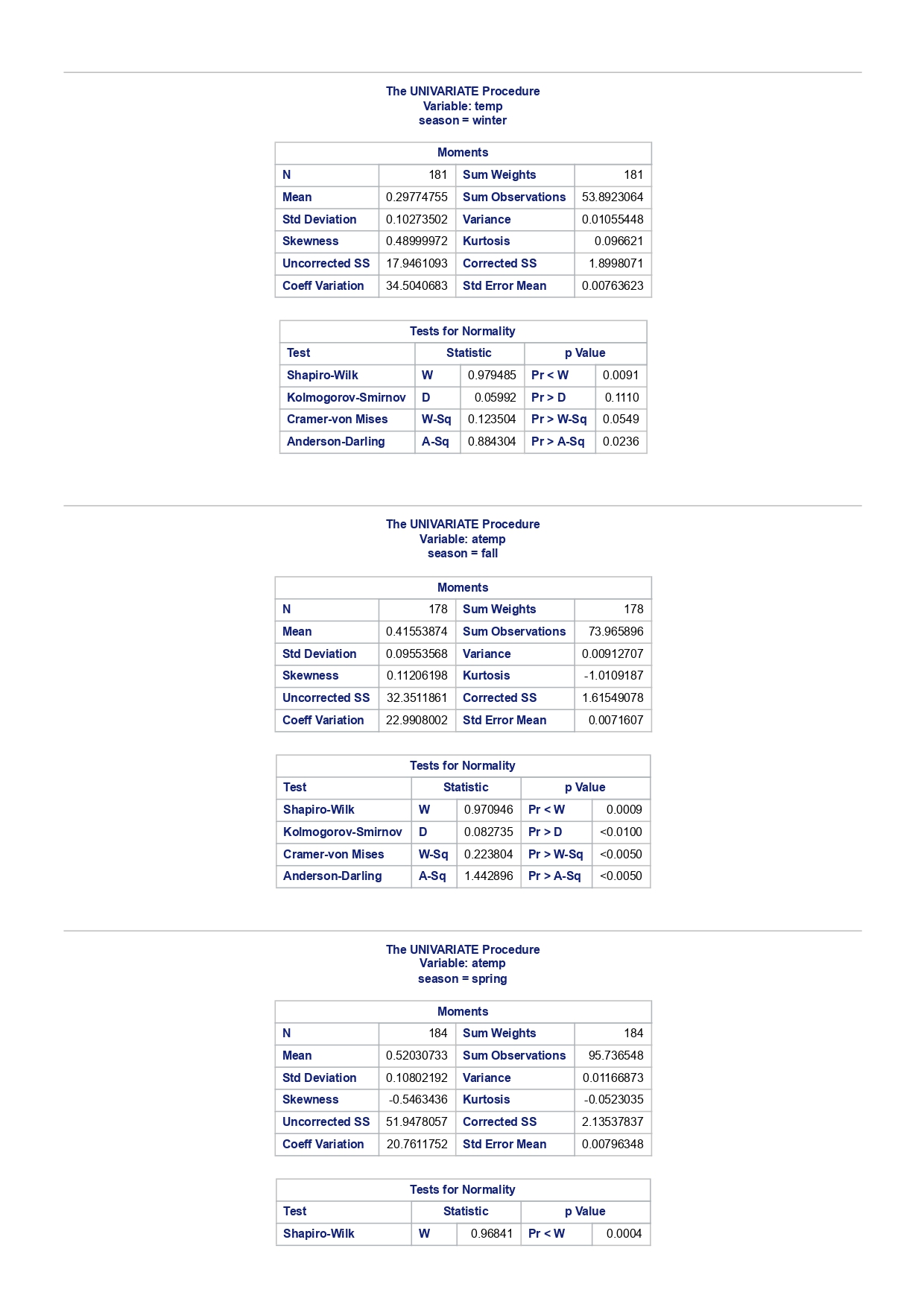
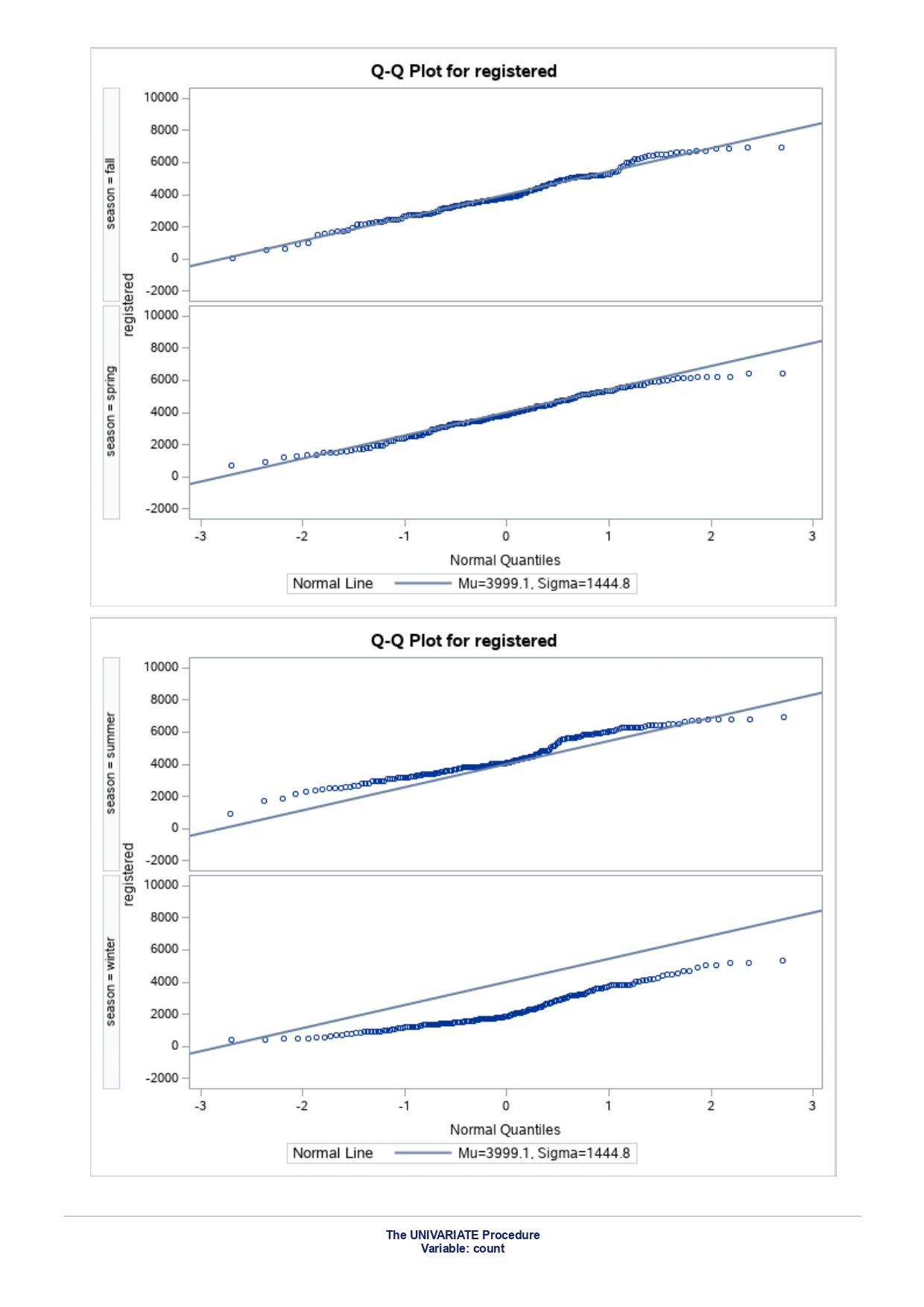
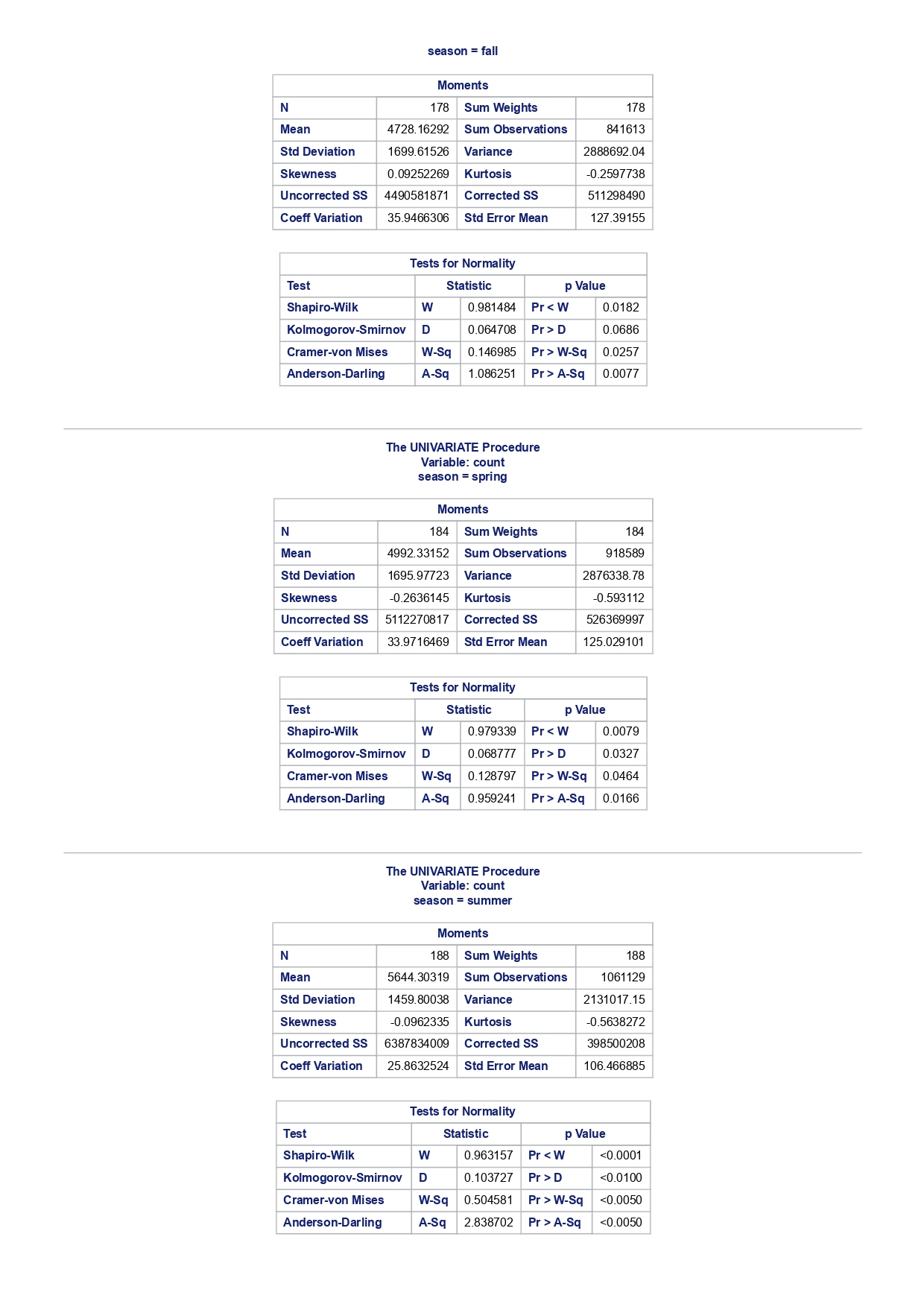
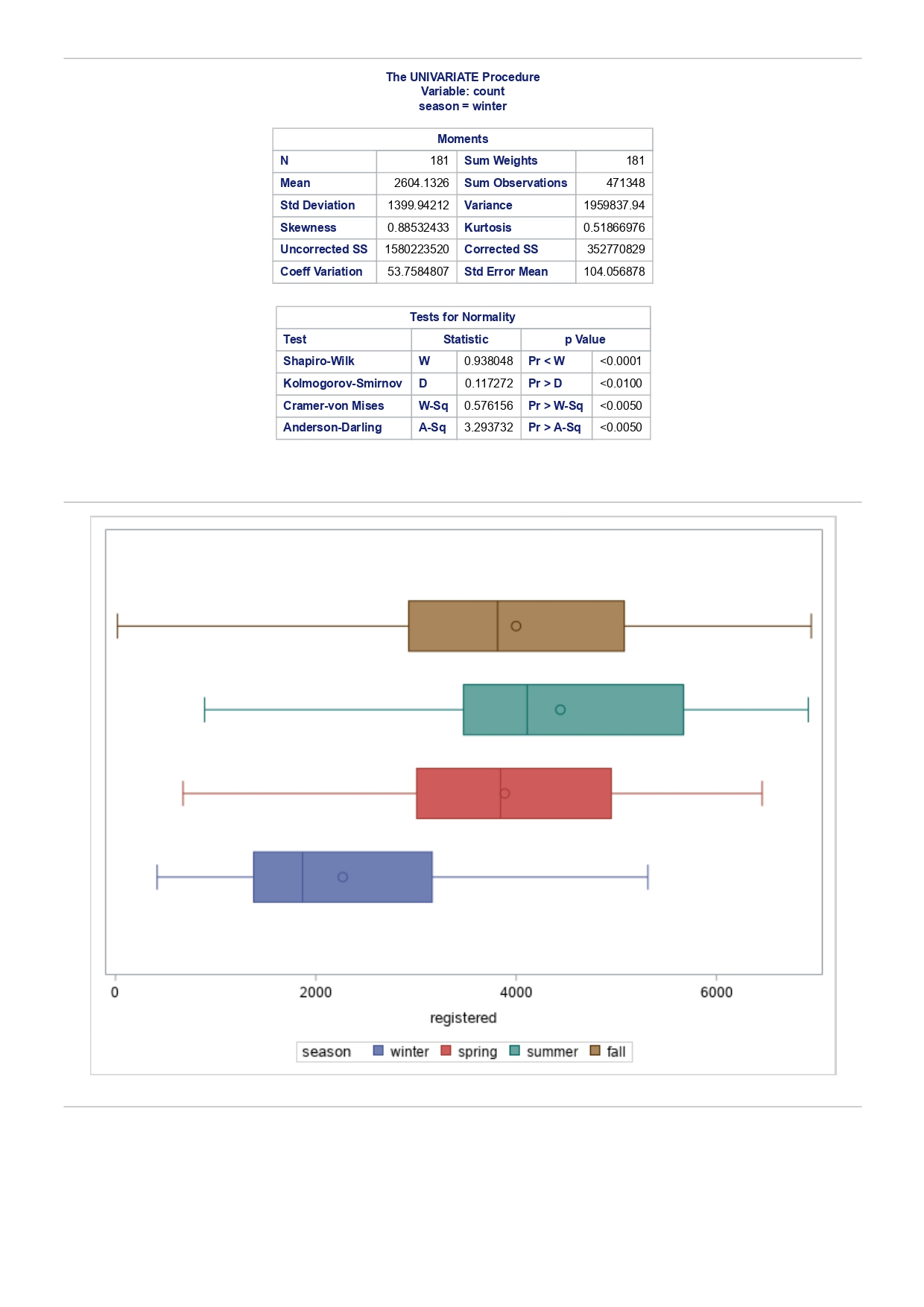
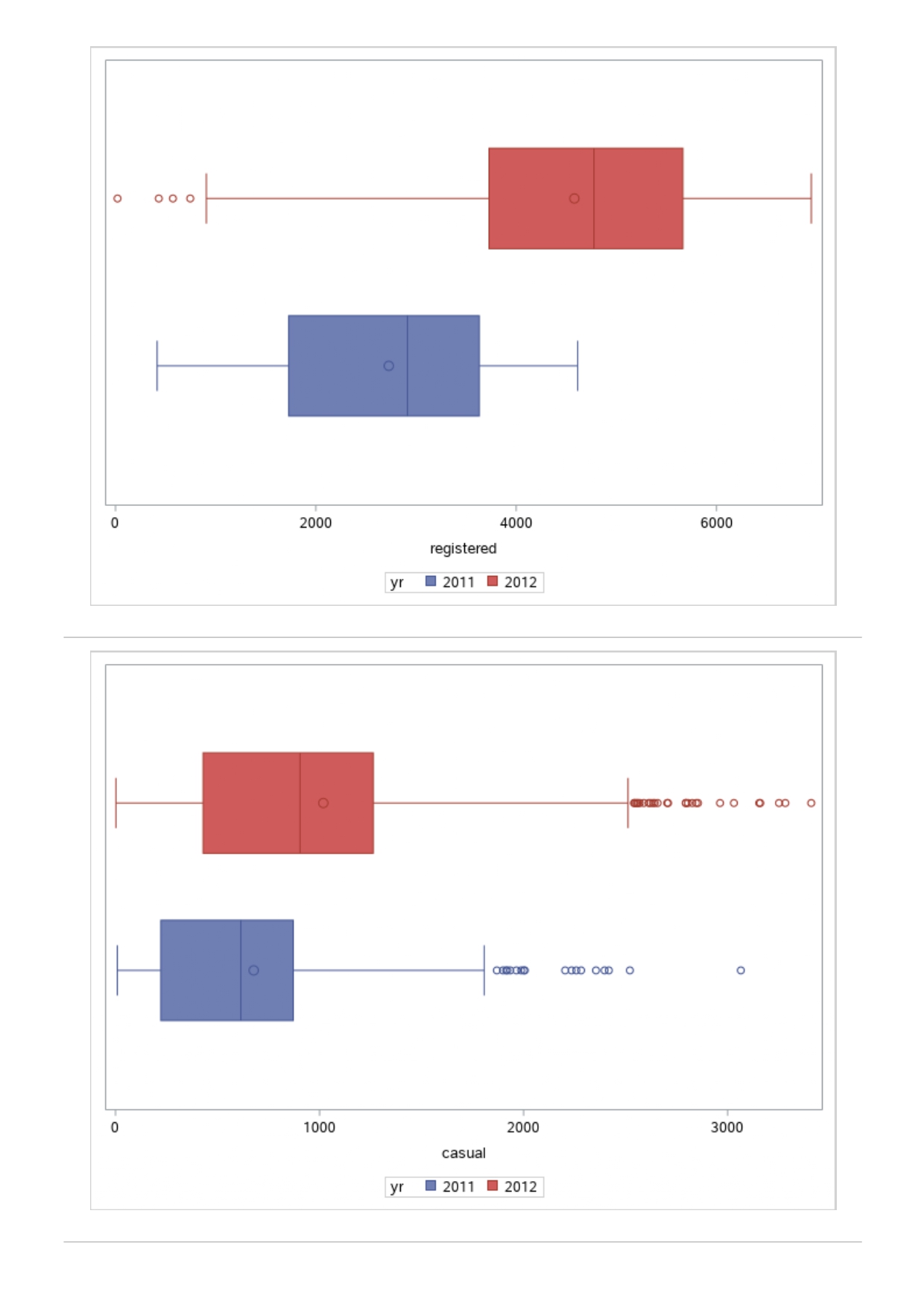
The MEANS Procedure Analysis Variable : registered Lower 95% Upper 95% N Obs N Mean Minimum Maximum Skewness Kurtosis CL for Mean CL for Mean 731 731 3656.17 20.000000 6946.00 0.0436588 -0.7130971 3542.88 3769.47 Analysis Variable : registered Lower 95% Upper 95% season N Obs N Mean Minimum Maximum Skewness Kurtosis CL for Mean CL for Mean fall 178 178 3999.05 20.0000000 6946.00 0.0428496 -0.2907145 3785.34 4212.76 spring 184 184: 674.0000000 6456.00 -0. 1391497 -0.7125236 3689.38 083.09 summer 188 188 4441.69 889.0000000 6917.00 0.1495646 -0.8482097 4253.99 629.40 winter 181 181 2269.20 416.0000000 5315.00 0.6466041 -0.507 1581 2093.16 2445.25 The UNIVARIATE Procedure Variable: instant season = fall Moments N 8 Sum Weights 178 Mean 493 Sum Observations 87754 Std Deviation 185.315764 Variance 34341.9322 Skewness Kurtosis -1.9445622 Uncorrected SS 49341244 Corrected SS 6078522 Coeff Variation 37.5894044 Std Error Mean 13.8900037 Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.756168 Pr D 0.0100 Cramer-von Mises W-Sq 3.485759 Pr > W-Sq A-Sq -0.0100 Cramer-von Mises W-Sq 3.547907 Pr > W-Sq A-Sq D 0.0100 Cramer-von Mises W-Sq 3.587437 Pr > W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D -0.0100 Cramer-von Mises W-Sq 3.547907 Pr > W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq W-Sq A-Sq D W-Sq A-Sq W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D 0.0100 Cramer-von Mises W-Sq 0.161514 Pr > W-Sq 0.0180 Anderson-Darling A-Sq 0.97246 Pr > A-Sq 0.0154 The UNIVARIATE Variable: temp season = summer Moments N 188 Sum Weight 188 Mean 0.70630931 Sum Observations 132.78615 Std Deviation 0.07084754 Variance 0.00501937 Skewness 0.5679781 Kurtosis 0.63751488 Uncorrected SS 94.7267166 Corrected SS 0.93862282 Coeff Variation 10.0306672 Std Error Mean 0.00516709 Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.977676 Pr D -0.0100 Cramer-von Mises N-Sq 0.20588 Pr > W-Sq A-Sq D 0. 1110 Cramer-von Mises W-Sq 0.123504 Pr > W-Sq 0.0549 Anderson-Darling A-Sq 0.884304 Pr > A-Sq 0.0236 The UNIVARIATE Procedure Variable: atem season = fal Moments N 178 Sum Weights 178 Mean 0.41553874 Sum Observations 73.965896 Std Deviation 0.09553568 Variance 0.00912707 Skewness 0.11206198 Kurtosis 1.0109187 Uncorrected SS 32.3511861 Corrected SS 1.61549078 Coeff Variation 22.9908002 Std Error Mean 0. 007 1607 Tests for Normality Test Statistic P Value Shapiro-Wilk N 0.970946 Pr D 0.0100 Cramer-von Mises W-Sq 0.223804 Pr > W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D 0. 1118 Cramer-von Mises W-Sq 0.131444 Pr > W-Sq 0.0434 Anderson-Darling A-Sq 0.828766 Pr> A-Sq 0.0334 The UNIVARIATE Procedure Variable: hum season = fall Moments N 178 Sum Weights 178 Mean 0.66871917 Sum Observations 119.032013 Std Deviation 0.13124796 Variance 0.01722603 Skewness 0.25281553 Kurtosis -0.43757 17 Uncorrected SS 82.6479961 Corrected SS 3.04900664Moments Coeff Variation 19.6267674 Std Error Mean 0.00983745 Tests for Normality Test Statistic P Value Shapiro-Wilk W 0.985581 Pr D >0.1500 Cramer-von Mises W-Sq 0.090705 Pr > W-Sq 0.1502 Anderson-Darling A-Sq 0.679666 Pr > A-Sq 0.0787 The UNIVARIATE Procedure Variable: hum season = spring Moments N 184 Sum Weights 184 Mean 0.62694833 Sum Observations 115.358493 Std Deviation 0. 15284075 Variance 0.02336029 Skewness 0.2444059 Kurtosis -0.685712 Uncorrected SS 76.5987485 Corrected SS 4.27493381 Coeff Variation 24.3785237 Std Error Mean 0.01126757 Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.980278 Pr D 0.0323 Cramer-von Mises W-Sq 0.167746 Pr > W-Sq 0.0149 Anderson-Darling A-Sq 0.98228 Pr > A-Sq 0.0145 The UNIVARIATE Procedure Variable: hum season = summer Moments N 188 Sum Weights 188 Mean 0.63348206 Sum Observations 119.094627 Std Deviation 0. 11934864 Variance 0.0142441 Skewness 0.16268524 Kurtosis 0.2458592 Uncorrected SS 78.1079558 Corrected SS 2.66364633 Coeff Variation 18.840098 Std Error Mean 0.00870439 Tests for Normality Test Statistic p Value Shapiro-Wilk 0.992206 Pr D >0.1500 Cramer-von Mises W-Sq 0.023287 Pr > W-Sq >0.2500 Anderson-Darling A-Sq 0.239351 Pr > A-Sq >0.2500 The UNIVARIATE Procedure Variable: hum season = winter Moments N 181 Sum Weights 181Moments Mean 0.58290291 Sum Observations 105.505427 Std Deviation 0. 15187972 Variance 0.02306745 Skewness 0.03011946 Kurtosis 0.36874169 Uncorrected SS 65.6515616 Corrected SS 4.152141 Coeff Variation 26.0557494 Std Error Mean 0.01128913 Tests for Normality Test Statistic p Value Shapiro-Wilk 0.971589 Pr W-Sq A-Sq D 0.0602 Cramer-von Mises W-Sq 0.162758 Pr > W-Sq 0.0174 Anderson-Darling A-Sq 1.1587 13 Pr > A-Sq D 0.0248 Cramer-von Mises W-Sq 0.247881 Pr > W-Sq A-Sq D 0.0100 Cramer-von Mises W-Sq 0.227581 Pr > W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D -0.0100 Cramer-von Mises W-Sq 1.38942 Pr > W-Sq A-Sq D W-Sq A-Sq D W-Sq A-Sq D 0.0660 Cramer-von Mises W-Sq 0.108452 Pr > W-Sq 0.0892 Anderson-Darling A-Sq 0.718851 Pr > A-Sq 0.0624 The UNIVARIATE Procedure Variable: registered season = spring Moments N Sum Weights 184 Mean 3886.2337 Sum Observations 15067 Std Deviation 1353.37563 Variance 1831625.59 Skewness 0.1391497 Kurtosis -0.7125236 Uncorrected SS 3114104953 Corrected SS 335187483 Coeff Variation 34.8248647 Std Error Mean 99.772175 Tests for Normality Test Statistic p Value Shapiro-Wilk N 0.982232 Pr D >0.1500 Cramer-von Mises W-Sq 0.065815 Pr > W-Sq >0.2500 Anderson-Darling A-Sq 0.600269 Pr > A-Sq 0.1202 The UNIVARIATE Procedure Variable: registered season = summer Moments N Sum Weights 188 Mean 4441.69149 Sum Observations 835038 Std Deviation 1304.62695 Variance 1702051.48 Skewness 0. 14956463 Kurtosis -0.8482097 Uncorrected SS 4027264804 Corrected SS 318283626Moments Coeff Variation 29.3723 Std Error Mean 95.1496994 Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.958596 Pr D W-Sq A-Sq W-Sq A-Sq D 0.0686 Cramer-von Mises W-Sq 0.146985 Pr > W-Sq 0.0257 Anderson-Darling A-Sq 1.086251 Pr > A-Sq 0.0077 The UNIVARIATE Procedure Variable: count season = spring Moments N 184 Sum Weights 184 Mean 4992.33152 Sum Observations 918589 Std Deviation 1695.97723 Variance 2876338.78 Skewness 0.2636145 Kurtosis -0.593112 Uncorrected SS 5112270817 Corrected SS 526369997 Coeff Variation 33.9716469 Std Error Mean 125.029101 Tests for Normality Test Statistic p Value Shapiro-Wilk W 0.979339 Pr D 0.0327 Cramer-von Mises W-Sq 0.128797 Pr > W-Sq 0.0464 Anderson-Darling A-Sq 0.959241 Pr > A-Sq 0.0166 The UNIVARIATE Procedure Variable: count season = summer Moments N 188 Sum Weights 188 Mean 5644.30319 Sum Observations 1061129 Std Deviation 1459.80038 Variance 2131017.15 Skewness -0.0962335 Kurtosis -0.5638272 Uncorrected SS 6387834009 Corrected SS 398500208 Coeff Variation 25.8632524 Std Error Mean 106.466885 Tests for Normality Test Statistic p Value Shapiro-Wilk N 0.963157 Pr D W-Sq A-Sq D -0.0100 Cramer-von Mises W-Sq 0.576156 Pr > W-Sq A-Sq [r| under HO: Rho=0 registered temp atemp hum windspeed registered 1.00000 0.54001 0.54419 -0.09109 0.21745 <.0001 temp atemp hum windspeed statistics for data sciences assignment description cb capital bikeshare online shop how> Bike Sharing Systems Bike sharing systems are a new generation of bike rentals where the whole process from membership, rental and return has become automatic. Through these systems, a user is able to easily rent a bike from a particular position and return the bike at another posi- tion. Currently, there are over 500 bike-sharing programs around the world, with some of the best and largest found in Hangzhou (China), Paris (France), London (England), New York City (US) and Montreal (Canada). Great interest in these systems exists due to their role in addressing traffic congestion, environmental impact and population health issues in big cities. The data for this assignment comes from one such program, called Capital Bikeshare, operating in Washington in the US. It has over 3000 bicycles that can be rented from over 350 stations across Washington, D.C., Arlington and Alexandria, VA and Montgomery County, MD. Their website encourages users to check out bikes for a trip to work, to run errands, go shopping, or visit friends and family. Users can join Capital Bikeshare for one to three days (casual membership), or for a month or a year (registered membership). Access to the Capital Bikeshare fleet of bikes is available 24 hours a day, 365 days a year. The first 30 minutes of each trip are free. You will use data derived from Capital Bikeshare trip records to build a statistical model for the purposes of predicting the total number of rentals per day. References and Data Sources: . Bache, K. & Lichman, M. (2013). UCI Machine Learning Repository http:MATH 4044 Statistics for Data Sciences Assignment 1 / /archive. ics . uci . edu/ml Irvine, CA: University of California, School of In- formation and Computer Science. . Fanace-T, Hadi, and Gama, Joao, 'Event labeling combining ensemble detectors and background knowledge', Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg. . http://capitalbikeshare . com/system-data Data file for this assignment The data file for this assignment is called daily . sas7bdat and contains daily counts of bike rentals for 2011 and 2012, derived from Capital Bikeshare trip history data, with additional weather and seasonal information. The data was downloaded from the UCI Machine Learning Repository. Variables in that file are: Variable Description instant Record index dteday Date season winter, spring summer, autumn (northern hemisphere) yr 0-2011, 1=2012 month Month (January to December) weekday Day of the week (Monday to Sunday) workingday Working day=1, weekend and public holiday = 0 temp Normalised temperature in degrees Celsius; observed temperature di- vided by 41 (max) atemp Normalised 'feels like' temperature in degrees Celsius; values divided by 50 (max) hum Normalised humidity; observed values divided by 100 (max) windspeed Normalised wind speed; observed values divided by 67 (max) casual Count of casual users registered Count of registered users count Total count of bike rentals (casual and registered).MATH 4044 Statistics for Data Sciences Assignment 1 Assignment Tasks Question 1 (20 marks) (a) (10 marks) Use SAS to study the distribution of the number of registered users per day (registered) by season. Obtain measures of location, disper- sion, skewness and kurtosis. Obtain a boxplot, histogram and a quantile- quantile plot. Also carry out Normal Goodness-of-fit tests. What are the key features of these distributions? (b) (10 marks) Now use SAS to obtain boxplots of registered by season, and by yr, respectively. Similarly, obtain boxplots of casual by season and yr. What do the boxplots suggests about the pattern and trend, if any, of bike rentals? Question 2 (60 marks) (a) (8 marks) Obtain a Pearson correlation matrix relating variables registered, atemp, temp, hum and windspeed. Also obtain a scatterplot matrix of the same variables. Discuss the relationships. (b) (12 marks) In this question, we investigate observations where workingday=1. Fit a simple regression model relating registered on working days to atemp, with registered as the dependent variable. Discuss the fitted relationship and the goodness of fit. Examine residual plots and influence diagnostics and comment on the residual patterns. (c) (20 marks) In this question, we investigate observations where workingday=1. Extend your multiple regression model for registered on working day by in- cluding the numerical and categorical predictors. In building your model consider as many potential explanatory variables as possible (you may need to define additional dummy variables). You can use stepwise selection to help you find the most parsimonious (simplest) model with the highest R-square. Be sure to check for collinearity and keep in mind that neither casual nor count should be used as explanatory variables for the total number of users. Summarise how your final model was obtained, including rationale for any modelling decisions you have made, and indicate why that final was considered the 'best'. Report and interpret your final model in detail, including a discussion of model diagnostics. Are there any observations that may require further in- spection due to their influence on the model? (d) (20 marks) In this question, we investigate observations where workingday=0. Build a multiple regression model for registered on non-working day, similar to question ()MATH 4044 Statistics for Data Sciences Assignment 1 Summarise how your final model was obtained, including rationale for any modelling decisions you have made. Report and interpret the final model. Compare and contrast the model with that obtained in question (c), and compare the effects of the predictors on registered for working and non- working day. Question 3 (20 marks) Write a summary of your findings from Questions 1 and 2. Keep the technical details of the analyses that led you to these conclusions to the absolute minimum. Rather, focus on practical significance and present your findings in non-specialist terms. One to two paragraphs (up to a page) will be sufficient. Hints: In order to study the regression for a specific group of observations, we can use the where statement. In particular, to build a regression model for working days, we can use proc reg data=. . . model . . . where workingday=1; run
Step by Step Solution
There are 3 Steps involved in it
Step: 1
Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2
Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance