

Question
This is a manual implementation of k-means algorithm to cluster a scattered data points 2D please edit this code: (don't use the built in k
This is a manual implementation of k-means algorithm to cluster a scattered data points 2D please edit this code: (don't use the built in k means function) only edit the provided code to do the following:
Define two Arrays x [from 1 to 10] and y [from 1 to 10] . choose 4 centroids random or preferably (2.5 and 7.5) for x and y. apply k means clustering. Thank you.
from sklearn.metrics import pairwise_distances_argmin def find_clusters(X, n_clusters, rseed=2): # 1. Randomly choose clusters rng = np.random.RandomState(rseed) i = rng.permutation(X.shape[0])[:n_clusters] centers = X[i] while True: # 2a. Assign labels based on closest center labels = pairwise_distances_argmin(X, centers) # 2b. Find new centers from means of points new_centers = np.array([X[labels == i].mean(0) for i in range(n_clusters)]) # 2c. Check for convergence if np.all(centers == new_centers): break centers = new_centers return centers, labels centers, labels = find_clusters(X, 4) plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis');
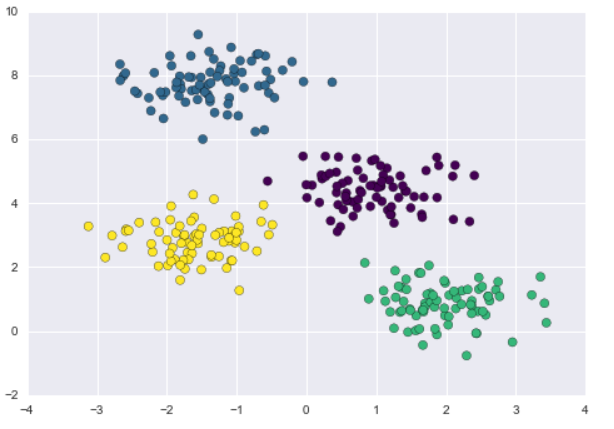
Result should be something like this:
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Essentials of Database Management
Authors: Jeffrey A. Hoffer, Heikki Topi, Ramesh Venkataraman
1st edition
133405680, 9780133547702 , 978-0133405682