

Question: This is an assignment that needs to be completed in ocaml. Thank you in advance! I have posted the code necessary to complete it below.
This is an assignment that needs to be completed in ocaml. Thank you in advance! I have posted the code necessary to complete it below. Just copy it into a .ml file and use a text editor to edit it. I don't know what other details I can provide. This is all the information the teacher provided us with. Please help!




The .ml files are thus:
regExpr.ml
(* Turning a string into a regular expression *)
(* Tokens (substrings that make up regular expressions) *) type tok = | LP | RP | U | DOT | Ch of char
(* turn a string into a list of regex tokens *) let rec tokenize st i = (* string -> int -> tok list *) if String.length st = i then [] else if st.[i] = '\\' then read_escape st (i+1) else (match st.[i] with '.' -> DOT | '*' -> ST | c -> Ch c)::(tokenize st (i+1)) and read_escape st i = (* string -> int -> tok list *) if String.length st = i then failwith "trailing backslash" else (match st.[i] with | '(' -> [LP] | ')' -> [RP] | '|' -> [U] | '.' | '[' | ']' -> [Ch st.[i]] | c -> [Ch '\\'; Ch c]) @ (tokenize st (i+1))
type regexp = Union of regexp * regexp | Concat of regexp * regexp | Char of char | Wild | NullSet (* matches no strings at all *)
(* parse a list of tokens into a regexp *) (* each function takes a list of tokens, tries to parse a kind of regex from the list, and returns the list of unused tokens *)
(* parse a "Base" Case regexp: Empty, NullSet, Bracket, Wild, or Char *) let rec parse_base_case token_list = match token_list with | [] -> (NullSet, []) | DOT::tl -> (Wild,tl) | LP::tl -> let (re,tl') = parse_regex tl in (match tl' with RP::tl'' -> (re,tl'') | _ -> failwith "expected close paren") | (Ch c)::tl -> (Char c,tl) | _ -> failwith "unexpected token" and term_helper tl re = match tl with (* parse a "factor" in a regex of the form r1 r2 (r3 ...) *) | RP::tl' -> (re,tl) | U::tl' -> (re,tl) | [] -> (re,[]) | _ -> let (re_next,tl') = parse_base_case tl in term_helper tl' (Concat (re,re_next)) and parse_terms tl = match parse_base_case tl with (* parse a regex in the form r1 r2 (r3...) *) | (t,RP::tl') -> (t, RP::tl') | (t,U::tl') -> (t, U::tl') | (t,[]) -> (t, []) | (t,tl')-> term_helper tl' t and regex_helper tl re = (* helper for parsing union of terms *) let (t_next,tl') = parse_terms tl in match tl' with | U::tl'' -> regex_helper tl'' (Union (re,t_next)) | _ -> (Union (re, t_next), tl') and parse_regex tl = match parse_terms tl with (* parse a regex *) | (t,U::tl') -> regex_helper tl' t | (t,tl') -> t,tl'
let rex_parse s = let n = String.length s in let s' = if n > 1 && s.[0] = '^' then String.sub s 1 (n-1) else (".*"^s) in let n' = String.length s' in let s'' = if n' > 1 && s'.[n'-1] = '$' then String.sub s' 0 (n'-1) else (s'^".*") in let tok_list = tokenize s'' 0 in match parse_regex tok_list with | (re,[]) -> re | _ -> failwith ("regular expression string "^s^" is unbalanced")
(* Check if an exploded string matches a regex - a helper function *) (* uses "continuation"-style search: k is a "continuation function" that checks the rest of the string *) let rec re_match re s k = match (re,s) with (* If the first character matches Char c, continue checking the rest of the string with k *) | (Char c, []) -> false | (Char c, c2::t) -> (c=c2) && (k t) (* Wild always eats a char *) | (Wild, []) -> false | (Wild, _::t) -> (k t) (* Check r1|r2 by first continuing with r1, and if that fails, continue with r2 *) | (Union (r1,r2), _) -> (re_match r1 s k) || (re_match r2 s k) (* Check r1 r2 by checking r1, and if that succeeds, "continue" with r2 *) | (Concat (r1,r2), _) -> (re_match r1 s (fun s' -> re_match r2 s' k)) | NullSet, _ -> false
let explode s = let n = String.length s in let rec exphelp i acc = if i = n then acc else exphelp (i+1) (s.[i]::acc) in List.rev (exphelp 0 [])
(* given a regexp and string, decide if the string matches *) let regex_match r s = re_match r (explode s) ((=) [])
(* Common ocaml idiom: other files will call the regexp type RegExpr.t *) type t = regexp;;
ogrep.ml
(* ogrep.ml - OCaml grep implementation for CSCI 2041 HW 2 *)
(* apply fn to each line of a file *) let for_each_line in_file (fn : string -> unit) = let rec loop () = let line = try Some (fn (input_line in_file)) with End_of_file -> None in match line with Some _ -> loop () | None -> () in loop ()
let grep_file (re : RegExpr.t) (filename : string) = let fh = if filename = "-" then "" else (filename ^ ":") in let in_f = if filename = "-" then stdin else open_in filename in let () = for_each_line in_f (fun s -> if RegExpr.regex_match re s then print_endline (fh^s) else ()) in close_in in_f
let rec grep_file_list (re : RegExpr.t) (flist : string list) = match flist with | [] -> () | fname::tl -> let () = grep_file re fname in grep_file_list re tl
let _ = if Array.length (Sys.argv) ["-"] | _ -> argl in grep_file_list rex argl'
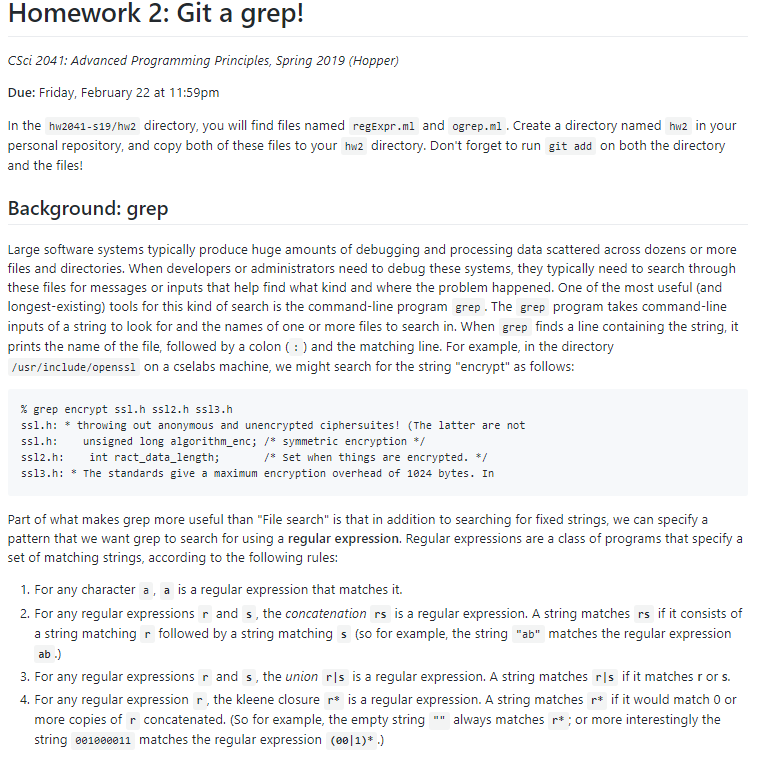
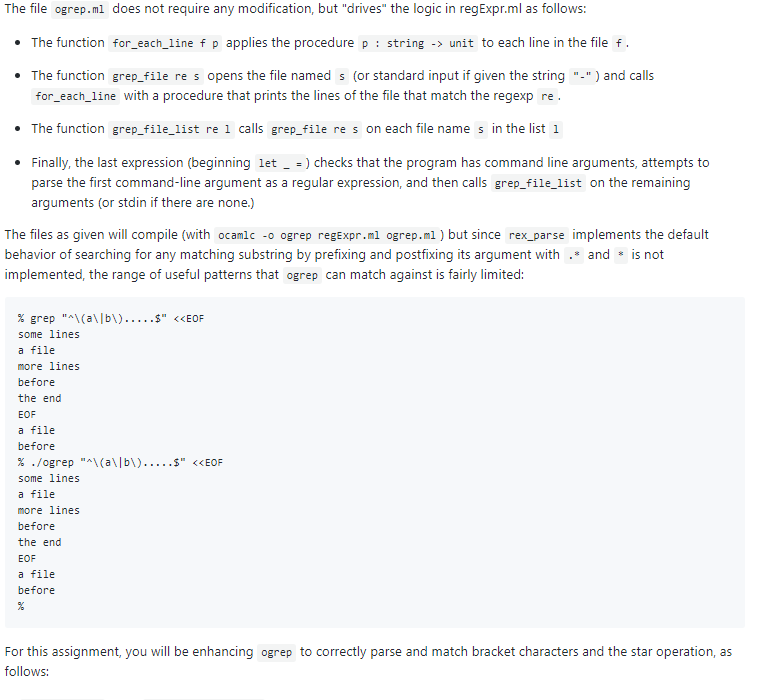
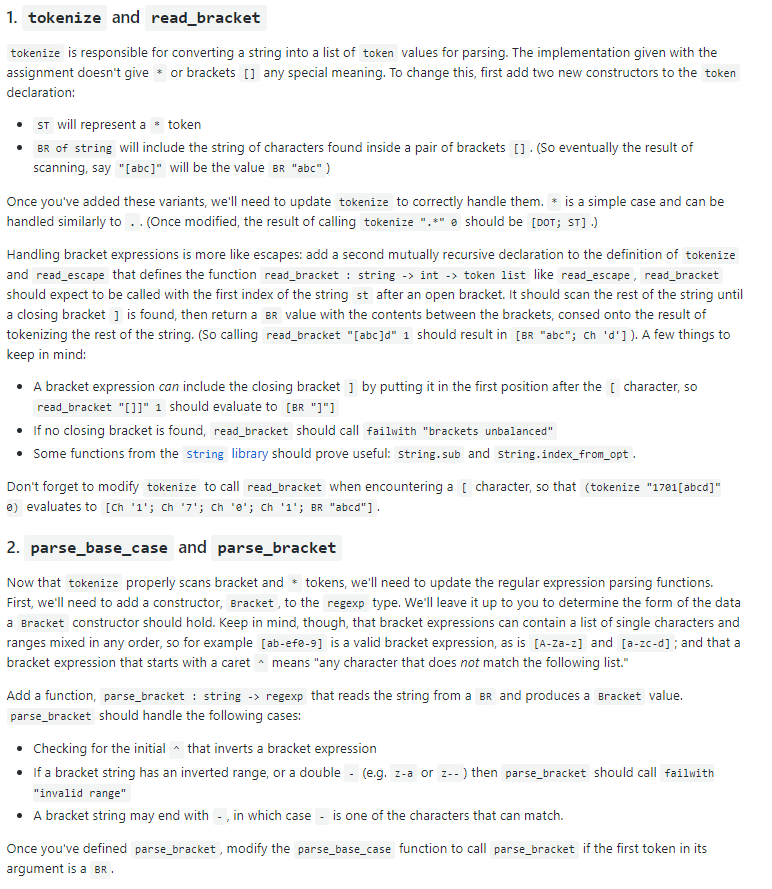
Homework 2: Git a grep! CSci 2041: Advanced Programming Principles, Spring 2019 (Hopper) Due: Friday, February 22 at 11:59pm in the hw2841-s19/hw2 directory, you will find files named regExpr.n1 and ogrep.nl. Create a directory named hW2 In your personal repository, and copy both of these files to your hw2 directory. Don't forget to run git add on both the directory and the files! Background: grep Large software systems typically produce huge amounts of debugging and processing data scattered across dozens or more files and directories. When developers or administrators need to debug these systems, they typically need to search through these files for messages or inputs that help find what kind and where the problem happened. One of the most useful (and longest-existing) tools for this kind of search is the command-line program grep. The grep program takes command-line inputs of a string to look for and the names of one or more files to search in. When grep finds a line containing the string, it prints the name of the file, followed by a colon () and the matching line. For example, in the directory /usr/include/openssl on a cselabs machine, we might search for the string "encrypt" as follows: % grep encrypt ssl.h ss12.h ss13.h ssl.h: throwing out anonymous and unencrypted ciphersuites! (The latter are not ssl.h unsigned long algorithm_enc; / symmetric encryption*/ Ss12.h: int ract_data_length; ss13.h: The standards give a maximum encryption overhead of 1024 bytes. In /* Set when things are encrypted. */ Part of what makes grep more useful than "File search" is that in addition to searching for fixed strings, we can specify a pattern that we want grep to search for using a regular expression. Regular expressions are a class of programs that specify a set of matching strings, according to the following rules: 1. For any character s a regular expression that matches it. 2. For any regular expressions r and s, the concatenation rs is a regular expression. A string matches rs if it consists of a string matching r followed by a string matching s so for example, the string "ab" matches the regular expression ab 3. For any regular expressions r and s, the union rls is a regular expression. A string matches rls if it matches r or s. 4. For any regular expression r, the kleene closurer is a regular expression. A string matches r if it would match 0 or more copies of r concatenated. (So for example, the empty stringalays matches r; or more interestingly the string e01000011 matches the regular expression (00|1)* .) The regular expressions supported by grep have a few extra features The wildcard. matches any single character Bracket expressions give a list of characters or character ranges to match against a single character, for instance [abc] matches a single a, b, or c character, [a-z] matches any single lower case character, and [123a-z] matches any lower case character or a 1 , 2 , or 3 . Additionally, if a bracket begins with a caret ( ^ ), this indicates that it matches any character not included in the bracket, so e-9] matches any non-digit character. .Because we might want to search for a string with a parenthesis,)),pipe (I), asterisk(or period (.) in it, there are some escaping rules: L ( , and ( need to be "escaped" with a \ in order to be regular expression operations (so alb matches the string "alb", but allb matches "a" or "b(a) only matches the string "(a)", but \(a) matches " Conversely, \. and* mean the characters ". and . Similarly, to make a bracket that includes ], we put the first, eg [Ja] matches "]" or "a to include we put it anywhere but the first position (so [a-] matches "a" or " ), and to include - in a bracket, it must be last: [a-] matches "a" or "- ) Grep implicitly searches for lines that contain a string matching the regular expression. To specify that the string must start at the beginning of a line, we can prefix the regular expression with a caret (), and to specify that the string must end at the end of a line, we can add a dollar sign (s) to the end of the regular expression (so aa matches any line that has one or more a characters but s only matches lines that consist only of a characters) Grep also supports "character classes" and "back-references", but for the purposes of this assignment, we'll ignore them. Here are a few concrete examples: Searching for all hexadecimal numbers starting with ex: grep "exte-9a-f]te-9a-f] Searching for declarations of public static accessor methods: grep "public staticl.Uget . Searching for all lines with "GET" or "POST" followed later by 400-404: grep "GET\POST.)40 [0-4]" In this assignment, we will write an Ocaml program that mimics the behavior of grep Regular Expressions, Lexing, and Parsing Regular expressions are a fundamental computational tool, used in programs from web applications, databases and network security to genome sequencing and computational linguistics. In order to process regular expressions, we first have to obtain them from input, and we usually do this from strings (in the case of grep, the string specifying a regular expression comes from a command line argument). In this homework, we'll write code to convert strings that represent grep-syntax regular expressions into data structures representing these expressions, and code that checks whether a string matches a regular expression. Lexing Reading structures like expressions or programs is usually separated into two phases, lexing and parsing. In lexing, a string is converted into a list of tokens, which are the important lexical components of a program. Here, the important components are: Opening and Closing parentheses, and \) Asterisks, *, representing the "star" operation, Pipes, representing the union operation, Brackets, and ], representing bracket characters, The wild-card character. And ordinary characters. Parsing In parsing, a list of tokens is converted to a structured representation of an expression, often called an "abstract syntax tree." In order to do this, we need to define the syntax of regular expressions and their abstract representation. We do so inductively, as follows. A regular expression is either: e a single character, or a wildcard character, or . a bracket character, or a star operator applied to a regular expression, or The concatenation of two regular expressions, consisting of tokens or The union of two regular expressions, consisting of tokens U When parsing a sequence of tokens into a syntax tree, we will often need to read sub-expressions from the sequence, and keep track of the remaining tokens after this sub-expression, e.g. after parsing the above we'll need to know the remaining sequence of tokens after the u nion token to parse char list converts a string into a list of characters regex_match regexp - string -> bool converts its second input into a char list and calls the continuation-search function re_match : regexp -char list -> (char list -> bool) -bool with an "initial continuation" that says that if we reach the end of the regexp at the end of the string, then the regexp and string match. Notice that re_match doesn't currently know how to handle in a regexp nor does it know how to handle bracket characters. The file ogrep.ml does not require any modification, but "drives" the logic in regExpr.ml as follows: The function for_each_line f p applies the procedure p : string unit to each line in the file f The function grep_file re s opens the file named s (or standard input if given the string and calls for_each_line with a procedure that prints the lines of the file that match the regexp re The function grep_file_list re 1 calls grep_file re s on each file name s in the list 1 Finally, the last expression (beginning let_-) checks that the program has command line arguments, attempts to parse the first command-line argument as a regular expression, and then calls grep_file_list on the remaining arguments (or stdin if there are none.) The files as given will compile (with ocamlc -o ogrep regExpr.ml ogrep.ml) but since rex_parse implements the default behavior of searching for any matching substring by prefixing and postfixing its argument with and is not implemented, the range of useful patterns that ogrep can match against is fairly limited: % grep "^ab some lines a file more lines before the end EOF a file before S" int -> token list like read escape, read bracket should expect to be called with the first index of the string st after an open bracket. It should scan the rest of the string until a closing bracket ] is found, then return a BR value with the contents between the brackets, consed onto the result of tokenizing the rest of the string. (So calling read_bracket "[abc]d" 1 should result in [BR "abc" Ch 'd']). A few things to keep in mind: A bracket expression can include the closing bracket 1 by putting it in the first position after the read-bracket "[]]" 1 should evaluate to [BR "]"] character, so If no closing bracket is found, read_bracket should call failwith "brackets unbalanced" Some functions from the string library should prove useful: string.sub and string.index_from_opt Don't forget to modify tokenize to call read_bracket when encountering a e) evaluates to [Ch '1'; Ch 7' Ch e' Ch '1'; BR "abcd"] character, so that (tokenize "17e1[abcd]" 2. parse base case and parse bracket Now that tokenize properly scans bracket and tokens, we'll need to update the regular expression parsing functions. First, we'll need to add a constructor, Bracket, to the regexp type. We'll leave it up to you to determine the form of the data a Bracket constructor should hold. Keep in mind, though, that bracket expressions can contain a list of single characters and ranges mixed in any order, so for example [ab-efe-9] is a valid bracket expression, as is [A-Za-z] and [a-zc-d]; and that a bracket expression that starts with a caret means "any character that does not match the following list. Add a function, parse_bracket string regexp that reads the string from a BR and produces a Bracket value parse_bracket should handle the following cases: Checking for the initial that inverts a bracket expression If a bracket string has an inverted range, or a double- (e.g. z-a or z-) then parse-bracket should call failwith "invalid range" A bracket string may end with - , in which case is one of the characters that can match. Once you've defined parse_bracket , modify the parse_base_case function to call parse_bracket if the first token in its argument is a BR 3. Star and parse starred_base Next, to support the star() operator, you'll need to add another constructor to the regexp type, Star of regexp. Once you've done that, you'll need to update the parser functions to correctly parse expressions containing a*.Add a function parse_starred_base to the mutually recursive group of parser functions (and parse_starred_base token_list- . You'll need to replace calls to parse_base with calls to parse_starred_base in the other parser functions, and parse_starred_base will make a call to parse_base_case. If parse_starred_base finds a ST token immediately following a base case, it should wrap the base case regexp in a star and otherwise just return the results of parse_base_case . Once you've finished with this step, it should be the case that parse_starred_base [DOT; ST] evaluates to (star wild, [), parse_starred_base [Ch 'a'; Ch 'b"; ch ''1 evaluates to (Char a, [Ch "b"; ch 'c']), and parse-regex [Ch a; ST; Ch 'b'] evaluates to (concat (star (Char 'a'), Char 'b'), [1) 4. bracket match In preparation for the final step, add the function bracket_match regexp -> char - bool which takes as input a Bracket value and a character c and checks whether c belongs to the range of characters the bracket expression represents. Thus bracket, match (parse-bracket "a-fe-9") should evaluate to true, and bracket-match (parse-bracket "ng-9") should evaluate to false . If bracket_match is called with a variant of regexp other than Bracket, it should call invalid_arg "bracket match" S. re match Finally, we need to modify re_match to handle mtching against star and Bracket regexp values. Add two cases to the match statement that handle the Bracket variant underneath the char cases in the provided implementation. These cases will look quite similar to the char cases but involve calling bracket_match instead of a simple equality check. Once this is done, you should find that, for instance regex_match (Concat (parse_bracket "e-9", parse_bracket "a-z")) "aevaluates to true Add another case to the match statement in re_match to handle star r. This is the trickiest case, but keep in mind that a string matches the regular expression* if it would match 0 or more concatenations of r. So we can match star r to s if we can continue matching s with k, or if we can match r to part of s and continue trying to match star r to the remaining portion of s.(This second possibility will look a lot like the concat case.) Once you have this case correctly implemented, you should find that, for example regex-match (Star (char )) "" evaluates to true, and so does regex-match (Star (Char a')) "aaa", but regex-match (Star (Char 'b')) "a" evaluates to false Homework 2: Git a grep! CSci 2041: Advanced Programming Principles, Spring 2019 (Hopper) Due: Friday, February 22 at 11:59pm in the hw2841-s19/hw2 directory, you will find files named regExpr.n1 and ogrep.nl. Create a directory named hW2 In your personal repository, and copy both of these files to your hw2 directory. Don't forget to run git add on both the directory and the files! Background: grep Large software systems typically produce huge amounts of debugging and processing data scattered across dozens or more files and directories. When developers or administrators need to debug these systems, they typically need to search through these files for messages or inputs that help find what kind and where the problem happened. One of the most useful (and longest-existing) tools for this kind of search is the command-line program grep. The grep program takes command-line inputs of a string to look for and the names of one or more files to search in. When grep finds a line containing the string, it prints the name of the file, followed by a colon () and the matching line. For example, in the directory /usr/include/openssl on a cselabs machine, we might search for the string "encrypt" as follows: % grep encrypt ssl.h ss12.h ss13.h ssl.h: throwing out anonymous and unencrypted ciphersuites! (The latter are not ssl.h unsigned long algorithm_enc; / symmetric encryption*/ Ss12.h: int ract_data_length; ss13.h: The standards give a maximum encryption overhead of 1024 bytes. In /* Set when things are encrypted. */ Part of what makes grep more useful than "File search" is that in addition to searching for fixed strings, we can specify a pattern that we want grep to search for using a regular expression. Regular expressions are a class of programs that specify a set of matching strings, according to the following rules: 1. For any character s a regular expression that matches it. 2. For any regular expressions r and s, the concatenation rs is a regular expression. A string matches rs if it consists of a string matching r followed by a string matching s so for example, the string "ab" matches the regular expression ab 3. For any regular expressions r and s, the union rls is a regular expression. A string matches rls if it matches r or s. 4. For any regular expression r, the kleene closurer is a regular expression. A string matches r if it would match 0 or more copies of r concatenated. (So for example, the empty stringalays matches r; or more interestingly the string e01000011 matches the regular expression (00|1)* .) The regular expressions supported by grep have a few extra features The wildcard. matches any single character Bracket expressions give a list of characters or character ranges to match against a single character, for instance [abc] matches a single a, b, or c character, [a-z] matches any single lower case character, and [123a-z] matches any lower case character or a 1 , 2 , or 3 . Additionally, if a bracket begins with a caret ( ^ ), this indicates that it matches any character not included in the bracket, so e-9] matches any non-digit character. .Because we might want to search for a string with a parenthesis,)),pipe (I), asterisk(or period (.) in it, there are some escaping rules: L ( , and ( need to be "escaped" with a \ in order to be regular expression operations (so alb matches the string "alb", but allb matches "a" or "b(a) only matches the string "(a)", but \(a) matches " Conversely, \. and* mean the characters ". and . Similarly, to make a bracket that includes ], we put the first, eg [Ja] matches "]" or "a to include we put it anywhere but the first position (so [a-] matches "a" or " ), and to include - in a bracket, it must be last: [a-] matches "a" or "- ) Grep implicitly searches for lines that contain a string matching the regular expression. To specify that the string must start at the beginning of a line, we can prefix the regular expression with a caret (), and to specify that the string must end at the end of a line, we can add a dollar sign (s) to the end of the regular expression (so aa matches any line that has one or more a characters but s only matches lines that consist only of a characters) Grep also supports "character classes" and "back-references", but for the purposes of this assignment, we'll ignore them. Here are a few concrete examples: Searching for all hexadecimal numbers starting with ex: grep "exte-9a-f]te-9a-f] Searching for declarations of public static accessor methods: grep "public staticl.Uget . Searching for all lines with "GET" or "POST" followed later by 400-404: grep "GET\POST.)40 [0-4]" In this assignment, we will write an Ocaml program that mimics the behavior of grep Regular Expressions, Lexing, and Parsing Regular expressions are a fundamental computational tool, used in programs from web applications, databases and network security to genome sequencing and computational linguistics. In order to process regular expressions, we first have to obtain them from input, and we usually do this from strings (in the case of grep, the string specifying a regular expression comes from a command line argument). In this homework, we'll write code to convert strings that represent grep-syntax regular expressions into data structures representing these expressions, and code that checks whether a string matches a regular expression. Lexing Reading structures like expressions or programs is usually separated into two phases, lexing and parsing. In lexing, a string is converted into a list of tokens, which are the important lexical components of a program. Here, the important components are: Opening and Closing parentheses, and \) Asterisks, *, representing the "star" operation, Pipes, representing the union operation, Brackets, and ], representing bracket characters, The wild-card character. And ordinary characters. Parsing In parsing, a list of tokens is converted to a structured representation of an expression, often called an "abstract syntax tree." In order to do this, we need to define the syntax of regular expressions and their abstract representation. We do so inductively, as follows. A regular expression is either: e a single character, or a wildcard character, or . a bracket character, or a star operator applied to a regular expression, or The concatenation of two regular expressions, consisting of tokens or The union of two regular expressions, consisting of tokens U When parsing a sequence of tokens into a syntax tree, we will often need to read sub-expressions from the sequence, and keep track of the remaining tokens after this sub-expression, e.g. after parsing the above we'll need to know the remaining sequence of tokens after the u nion token to parse char list converts a string into a list of characters regex_match regexp - string -> bool converts its second input into a char list and calls the continuation-search function re_match : regexp -char list -> (char list -> bool) -bool with an "initial continuation" that says that if we reach the end of the regexp at the end of the string, then the regexp and string match. Notice that re_match doesn't currently know how to handle in a regexp nor does it know how to handle bracket characters. The file ogrep.ml does not require any modification, but "drives" the logic in regExpr.ml as follows: The function for_each_line f p applies the procedure p : string unit to each line in the file f The function grep_file re s opens the file named s (or standard input if given the string and calls for_each_line with a procedure that prints the lines of the file that match the regexp re The function grep_file_list re 1 calls grep_file re s on each file name s in the list 1 Finally, the last expression (beginning let_-) checks that the program has command line arguments, attempts to parse the first command-line argument as a regular expression, and then calls grep_file_list on the remaining arguments (or stdin if there are none.) The files as given will compile (with ocamlc -o ogrep regExpr.ml ogrep.ml) but since rex_parse implements the default behavior of searching for any matching substring by prefixing and postfixing its argument with and is not implemented, the range of useful patterns that ogrep can match against is fairly limited: % grep "^ab some lines a file more lines before the end EOF a file before S" int -> token list like read escape, read bracket should expect to be called with the first index of the string st after an open bracket. It should scan the rest of the string until a closing bracket ] is found, then return a BR value with the contents between the brackets, consed onto the result of tokenizing the rest of the string. (So calling read_bracket "[abc]d" 1 should result in [BR "abc" Ch 'd']). A few things to keep in mind: A bracket expression can include the closing bracket 1 by putting it in the first position after the read-bracket "[]]" 1 should evaluate to [BR "]"] character, so If no closing bracket is found, read_bracket should call failwith "brackets unbalanced" Some functions from the string library should prove useful: string.sub and string.index_from_opt Don't forget to modify tokenize to call read_bracket when encountering a e) evaluates to [Ch '1'; Ch 7' Ch e' Ch '1'; BR "abcd"] character, so that (tokenize "17e1[abcd]" 2. parse base case and parse bracket Now that tokenize properly scans bracket and tokens, we'll need to update the regular expression parsing functions. First, we'll need to add a constructor, Bracket, to the regexp type. We'll leave it up to you to determine the form of the data a Bracket constructor should hold. Keep in mind, though, that bracket expressions can contain a list of single characters and ranges mixed in any order, so for example [ab-efe-9] is a valid bracket expression, as is [A-Za-z] and [a-zc-d]; and that a bracket expression that starts with a caret means "any character that does not match the following list. Add a function, parse_bracket string regexp that reads the string from a BR and produces a Bracket value parse_bracket should handle the following cases: Checking for the initial that inverts a bracket expression If a bracket string has an inverted range, or a double- (e.g. z-a or z-) then parse-bracket should call failwith "invalid range" A bracket string may end with - , in which case is one of the characters that can match. Once you've defined parse_bracket , modify the parse_base_case function to call parse_bracket if the first token in its argument is a BR 3. Star and parse starred_base Next, to support the star() operator, you'll need to add another constructor to the regexp type, Star of regexp. Once you've done that, you'll need to update the parser functions to correctly parse expressions containing a*.Add a function parse_starred_base to the mutually recursive group of parser functions (and parse_starred_base token_list- . You'll need to replace calls to parse_base with calls to parse_starred_base in the other parser functions, and parse_starred_base will make a call to parse_base_case. If parse_starred_base finds a ST token immediately following a base case, it should wrap the base case regexp in a star and otherwise just return the results of parse_base_case . Once you've finished with this step, it should be the case that parse_starred_base [DOT; ST] evaluates to (star wild, [), parse_starred_base [Ch 'a'; Ch 'b"; ch ''1 evaluates to (Char a, [Ch "b"; ch 'c']), and parse-regex [Ch a; ST; Ch 'b'] evaluates to (concat (star (Char 'a'), Char 'b'), [1) 4. bracket match In preparation for the final step, add the function bracket_match regexp -> char - bool which takes as input a Bracket value and a character c and checks whether c belongs to the range of characters the bracket expression represents. Thus bracket, match (parse-bracket "a-fe-9") should evaluate to true, and bracket-match (parse-bracket "ng-9") should evaluate to false . If bracket_match is called with a variant of regexp other than Bracket, it should call invalid_arg "bracket match" S. re match Finally, we need to modify re_match to handle mtching against star and Bracket regexp values. Add two cases to the match statement that handle the Bracket variant underneath the char cases in the provided implementation. These cases will look quite similar to the char cases but involve calling bracket_match instead of a simple equality check. Once this is done, you should find that, for instance regex_match (Concat (parse_bracket "e-9", parse_bracket "a-z")) "aevaluates to true Add another case to the match statement in re_match to handle star r. This is the trickiest case, but keep in mind that a string matches the regular expression* if it would match 0 or more concatenations of r. So we can match star r to s if we can continue matching s with k, or if we can match r to part of s and continue trying to match star r to the remaining portion of s.(This second possibility will look a lot like the concat case.) Once you have this case correctly implemented, you should find that, for example regex-match (Star (char )) "" evaluates to true, and so does regex-match (Star (Char a')) "aaa", but regex-match (Star (Char 'b')) "a" evaluates to false
Step by Step Solution
There are 3 Steps involved in it

Get step-by-step solutions from verified subject matter experts