

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
This question is related to machine learning 1. Gradient descent - Logistic regression In this question we are going to experiment with logistic regression. This
This question is related to machine learning 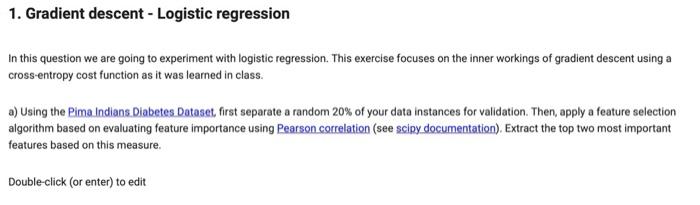


1. Gradient descent - Logistic regression In this question we are going to experiment with logistic regression. This exercise focuses on the inner workings of gradient descent using a cross-entropy cost function as it was learned in class. a) Using the Pima Indians. Diabetes Dataset first separate a random 20% of your data instances for validation. Then apply a feature selection algorithm based on evaluating feature importance using Pearson correlation (see sciny documentation). Extract the top two most important features based on this measure. Double-click (or enter) to edit b) We want to train a logistic regression model to predict the target feature Outcome. It's important that no other external package is used (pandas, numpy are ok) for this question part. We want to find the weights for the logistic regression using a hand made gradient descent algorithm. We will use cross-entropy as the cost function, and the logistic cross-entropy to compute the weight update during gradient descent It is OK to reuse as much as you need from the code you developed for Assignment 1. Differently from what we did for Assignment 1, we are now using a random 20% of your data instances for validation Your function should be able to return the updated weights and bias after every iteration of the gradient descent algorithm. Your function should be defined as follows: def LeGradDescl data, target, weight_init, bias_init, learning_rate, max_iter): And it should print lines as indicated below (note the last line with the weights): Iteration 0: (initial_train cost], [train accuracyl, validation accuracy] Iteration 1: [train cost after first iteration), (train accuracy after first iteration), (validation accuracy after first iteration) Iteration 2: [weights after second iteration), (train cost after second iteration), train accuracy after second iteration), (validation accuracy after second iteration) Iteration max_iter : [weights after max_iter iteration), Itrain cost after max_iter iteration), (train accuracy after max_iter iteration), Ivalidation accuracy after max_iter iterations] Final weights: [bias], [w_01, [w_11 Note that you may want to print every 100 or every 1000 iterations if max_iter is a fairly large number (but you shouldn't have more iterations than the indicated in max_iter). c) Discuss how the choice of learning_rate affects the fitting of the model. d) Compare your model with one using a machine learning library to compute logistic regression. e) Retrain your model using three features of your choice. Compare both models using an ROC curve (you can use code from here to draw the ROC curve). 1. Gradient descent - Logistic regression In this question we are going to experiment with logistic regression. This exercise focuses on the inner workings of gradient descent using a cross-entropy cost function as it was learned in class. a) Using the Pima Indians. Diabetes Dataset first separate a random 20% of your data instances for validation. Then apply a feature selection algorithm based on evaluating feature importance using Pearson correlation (see sciny documentation). Extract the top two most important features based on this measure. Double-click (or enter) to edit b) We want to train a logistic regression model to predict the target feature Outcome. It's important that no other external package is used (pandas, numpy are ok) for this question part. We want to find the weights for the logistic regression using a hand made gradient descent algorithm. We will use cross-entropy as the cost function, and the logistic cross-entropy to compute the weight update during gradient descent It is OK to reuse as much as you need from the code you developed for Assignment 1. Differently from what we did for Assignment 1, we are now using a random 20% of your data instances for validation Your function should be able to return the updated weights and bias after every iteration of the gradient descent algorithm. Your function should be defined as follows: def LeGradDescl data, target, weight_init, bias_init, learning_rate, max_iter): And it should print lines as indicated below (note the last line with the weights): Iteration 0: (initial_train cost], [train accuracyl, validation accuracy] Iteration 1: [train cost after first iteration), (train accuracy after first iteration), (validation accuracy after first iteration) Iteration 2: [weights after second iteration), (train cost after second iteration), train accuracy after second iteration), (validation accuracy after second iteration) Iteration max_iter : [weights after max_iter iteration), Itrain cost after max_iter iteration), (train accuracy after max_iter iteration), Ivalidation accuracy after max_iter iterations] Final weights: [bias], [w_01, [w_11 Note that you may want to print every 100 or every 1000 iterations if max_iter is a fairly large number (but you shouldn't have more iterations than the indicated in max_iter). c) Discuss how the choice of learning_rate affects the fitting of the model. d) Compare your model with one using a machine learning library to compute logistic regression. e) Retrain your model using three features of your choice. Compare both models using an ROC curve (you can use code from here to draw the ROC curve) Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Data Management Databases And Organizations
Authors: Richard T. Watson
2nd Edition
0471180742, 978-0471180746