

Question
TME SERES DALY ENERGY # Imports. Do not add any external libraries other than NumPy and Matplotlib import numpy as np import matplotlib.pyplot as plt
TME SERES DALY ENERGY
# Imports. Do not add any external libraries other than NumPy and Matplotlib import numpy as np import matplotlib.pyplot as plt
------ next IN []: (as in the images)
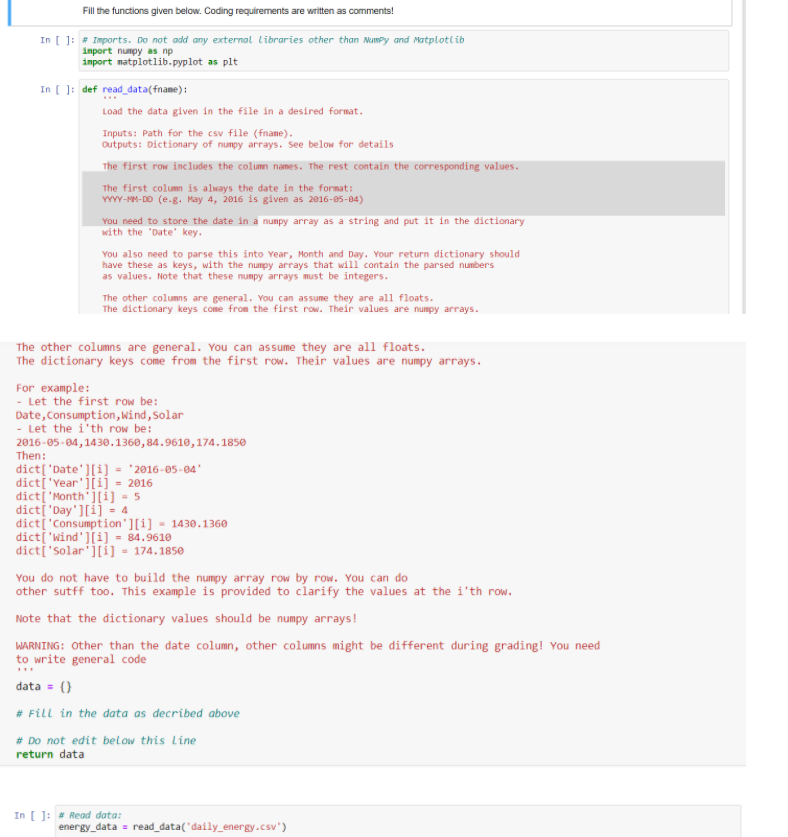
def read_data(fname): ''' Load the data given in the file in a desired format. Inputs: Path for the csv file (fname). Outputs: Dictionary of numpy arrays. See below for details The first row includes the column names. The rest contain the corresponding values. The first column is always the date in the format: YYYY-MM-DD (e.g. May 4, 2016 is given as 2016-05-04) You need to store the date in a numpy array as a string and put it in the dictionary with the 'Date' key. You also need to parse this into Year, Month and Day. Your return dictionary should have these as keys, with the numpy arrays that will contain the parsed numbers as values. Note that these numpy arrays must be integers. The other columns are general. You can assume they are all floats. The dictionary keys come from the first row. Their values are numpy arrays. For example: - Let the first row be: Date,Consumption,Wind,Solar - Let the i'th row be: 2016-05-04,1430.1360,84.9610,174.1850 Then: dict['Date'][i] = '2016-05-04' dict['Year'][i] = 2016 dict['Month'][i] = 5 dict['Day'][i] = 4 dict['Consumption'][i] = 1430.1360 dict['Wind'][i] = 84.9610 dict['Solar'][i] = 174.1850 You do not have to build the numpy array row by row. You can do other sutff too. This example is provided to clarify the values at the i'th row. Note that the dictionary values should be numpy arrays! WARNING: Other than the date column, other columns might be different during grading! You need to write general code ''' data = {} # Fill in the data as decribed above # Do not edit below this line return data
-------
# Read data: energy_data = read_data('daily_energy.csv')
# Simple tests: desired_keys = ['Date', 'Year', 'Month', 'Day', 'Consumption', 'Wind', 'Solar'] desired_num_cols = 1096 averages = {'Consumption':1383.146247, 'Wind':234.620880, 'Solar':96.124640}
for key in desired_keys: if key not in energy_data.keys(): print(f'Missing key {key} in the dictionary')
for key in energy_data.keys(): if not isinstance(energy_data[key],np.ndarray): print(f'The value corresponding to the key, {key}, in the dictionary is not a numpy array') elif energy_data[key].shape[0] != desired_num_cols: print(f'The numpy array corresponding to {key} does not have the correct number of elements {desired_num_cols} vs {averages[key].shape[0]}') for key, item in averages.items(): tmp = energy_data[key].mean() if abs(tmp-averages[key]) > 1e-6: print(f'The correct average ({averages[key]:.2f}) and the average of the dictionary ({tmp:.2f}) do not match.')
-----------
def plot_data(data, keys = None, date_range = None, ylabel = 'GWh', title = 'Germany Electricity'): ''' Plot the desired values given the keys. Input: - data: dictionary of data, at least containing the key 'Date' - keys: The list of keys whose values will be plotted. If None, all the keys of the dictionary should be plotted - date_range: Tuple of the first and last dates to plot. If None, use the date range given in the data. You can assume that the date is always increasing. An example: ('2015-01-01', '2017-12-31') - ylabel: The desired ylabel of the figure - title: The desired title of the figure Output: The handle of the plotted figure (done for you, do not change it!) Plotting requirements: - This should be a line plot (plt.plot(...)). The x's are the days, the y's are the values in the numpy arrays given by the keys. The style of the lines should be left as defaults - x-axis: The data within the given range. The plot will be for each day (entry) within the range. The ticks and their labels will be different (see below) You can assume the limits are already within the data (e.g. no 2014 or 2018 for the given example file) - y-axis: the numpy values corresponding to keys - The y-ticks should be left as default. - The x-ticks should be on the first day of March, June, September and December with the label "MarYY", "JunYY", "SepYY" and "AugYY" respectively where YY is the last two digits of the year. For example Jun16, Aug17 ... - The tick labelsize should be 12 for both axes. - xlabel: Should be 'Date'. Should have a fontsize of 18 - ylabel and title: Given as an input. Both should have a fontsize of 18 - Legend: The legend should have the keys corresponding to the lines. It should have a fontsize of 18 - Extra Text: Write the mean and standard deviation of the keys within the given time range somewhere on the figure. If there are multiple keys, write this for all of them. Play around with the placement to make sure the rest of the plot is visible! Hint: To set the fontsizes, look at the HistogramApplication.ipynb. For the legend, it is set the same way as the labels ''' plt.figure(figsize=(12,8)) # Your code goes below this line # Do not edit below this line return plt.gcf()
----------
all_data_plot = plot_data(energy_data) all_data_plot.savefig('alldata.png',dpi=300)
---------
subset_plot = plot_data(energy_data,['Wind','Solar']) subset_plot.savefig('subset.png',dpi=300)
----------
shorter_date_plot = plot_data(energy_data,date_range=('2015-07-01','2017-01-31')) shorter_date_plot.savefig('shorter.png',dpi=300)
------------
shorter_date_subset_plot = plot_data(energy_data,['Consumption','Wind'],date_range=('2016-01-01','2017-06-30')) shorter_date_subset_plot.savefig('shortersubset.png',dpi=300)
-------------
def fit_line(data, key1, key2): ''' Fit a line between the values given by key1 and key2. Return the coefficients and the R2 score. Input: - data: dictionary of data - key1: The key of the first column (x) - key2: The key of the second column (y) Output: - coef: A list of values that correspond to the linear fit between x and y. i.e. y = coef[0]*x+coef[1] - r2: The R2 value. Note that you can calculate this using the residuals which can be obtained using the lstsq function of the numpy linear algebra module ''' coef = [0,0] r2 = 0 # Fill in the coef and the r2 variables with their correct values # Your code goes below this line # Do not edit below this line return coef, r2
-----------
print(''' Expected Output (close to): [ -0.14 128.93] [0.15] [-1.41e-01 2.92e+02] [0.14] [ 0.11 88.49] [0.0097] ''')
coefWS,r2WS = fit_line(energy_data, 'Wind', 'Solar') print(coefWS,r2WS) coefCS,r2CS = fit_line(energy_data, 'Consumption', 'Solar') print(coefCS,r2CS) coefCW,r2CW = fit_line(energy_data, 'Consumption', 'Wind') print(coefCW,r2CW)
---------------
def plot_xy_line(data, key1, key2, coef): ''' Plot the key1 vs key2 and the line defined by the coef Input: - data: dictionary of data - key1: The key of the first column (x) - key2: The key of the second column (y) - coef: The coefficients of the linear function between the keys (coef[0]*x+coef[1]) Output: The handle of the plotted figure (done for you, do not change it!) Plotting requirements: - This should be a line plot (plt.plot(...)). The key1 vs key2 should only be diamond markers (hint: 'd'). The line should have the default parameters - xlabel: Should be key1. Should have a fontsize of 18 - ylabel: Should be key2. Should have a fontsize of 18 - Legend: Should be f'{key1} vs {key2}' and 'Fit' ''' plt.figure(figsize=(12,8)) # Your code goes below this line # Do not edit below this line return plt.gcf()
------------------
ws_plot = plot_xy_line(energy_data,'Wind','Solar',coefWS)
-------------------
cs_plot = plot_xy_line(energy_data,'Consumption','Solar',coefCS)
------------------
cw_plot = plot_xy_line(energy_data,'Consumption','Wind',coefCW)
-----------------
def plot_hist(data, key, bin_width = None, date_range = None): ''' Plot the histogram of the values corresponding to the given key, in the given date_range. Input: - data: dictionary of data - key: The key of the values we want to plot - bin_width: The approximate width of each bin. When you are calculating the bin number, round the number up. If None, use 10 bins by default. - date_range: Tuple of the first and last dates to plot. If None, use the date range given in the data. You can assume that the date is always increasing. Output: - The handle of the plotted figure (done for you, do not change it!) - The number of items in each bin (set the counts variable) - The bin edges (set the edges variable) Hint: The last two are the outputs of the hist function ''' counts = 0 bins = 0 plt.figure(figsize=(12,8)) # Your code below this line # Do not edit below this line return plt.gcf(), counts, bins
----------------------
wh, whc, whe = plot_hist(energy_data,'Wind')
-----------
sh, shc, she = plot_hist(energy_data,'Solar')
----------
ssh, sshc, sshe = plot_hist(energy_data,'Solar',25,('2017-06-01','2017-08-30'))
----------
if(len(sshc)!=8): print('Check how you calculate the number of bins given bin width!')
------------
def energy_generation_pie(data, date_range = None): ''' This function is specific to the given file. You should plot the pie chart of energy generation through wind, solar and other means. The other means can be calculated as Consumption - (Wind + Solar). This should be based on the averages in the given date range. Each slice/wedge should include the key name! Input: - data: dictionary of data - date_range: Tuple of the first and last dates to plot. If None, use the date range given in the data. You can assume that the date is always increasing. Output: - The handle of the plotted figure (done for you, do not change it!) - The averages of each key as a dictionary ''' # Fill this correctly avg_dict = {'Other':-1,'Wind':-1,'Solar':-1} plt.figure(figsize=(12,8)) # Your code below this line # Do not edit below this line return plt.gcf(), avg_dict
------------------
pc, avgs = energy_generation_pie(energy_data)
---------------
#We expect Solar contribution to increase pcs, avgss = energy_generation_pie(energy_data,('2017-06-01','2017-08-30'))
DATA (HAD TO DELETE SOME BECAUSE T SAYS TOO LONG)
Date,Consumption,Wind,Solar 2015-01-01,1111.3360,325.1280,17.0790 2015-01-02,1300.8840,603.5580,7.7580 2015-01-03,1265.2710,462.9530,7.2360 2015-01-04,1198.8540,385.0240,19.9840 2015-01-05,1449.8610,216.5430,26.5240 2015-01-06,1452.8910,117.2310,32.8880 2015-01-07,1569.8720,227.2080,17.1130 2015-01-08,1586.9740,440.3200,8.5970 2015-01-09,1563.2930,641.7300,6.8230 2015-01-10,1331.4480,634.6750,20.4770 2015-01-11,1262.1610,630.3790,19.8110 2015-01-12,1582.0660,631.8330,11.0250 2015-01-13,1574.3020,511.7330,50.2820 2015-01-14,1593.6820,406.9860,18.1050 2015-01-15,1602.4040,556.4710,17.1560 2015-01-16,1565.3200,249.3290,22.8170 2015-01-17,1354.8010,137.7190,21.4050 2015-01-18,1267.4890,127.2170,31.2610 2015-01-19,1594.8690,31.6210,23.6830 2015-01-20,1629.7300,16.7370,10.7900 2015-01-21,1632.1460,50.3650,22.1210 2015-01-22,1636.9780,62.2940,12.1190 2017-12-25,1111.2834,587.8100,15.7650 2017-12-26,1130.1168,717.4530,30.9230 2017-12-27,1263.9409,394.5070,16.5300 2017-12-28,1299.8640,506.4240,14.1620 2017-12-29,1295.0875,584.2770,29.8540 2017-12-30,1215.4490,721.2470,7.4670 2017-12-31,1107.1149,721.1760,19.9800
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Modern Database Management
Authors: Jeff Hoffer, Ramesh Venkataraman, Heikki Topi
12th edition
133544613, 978-0133544619