

Answered step by step
Verified Expert Solution
Question
1 Approved Answer
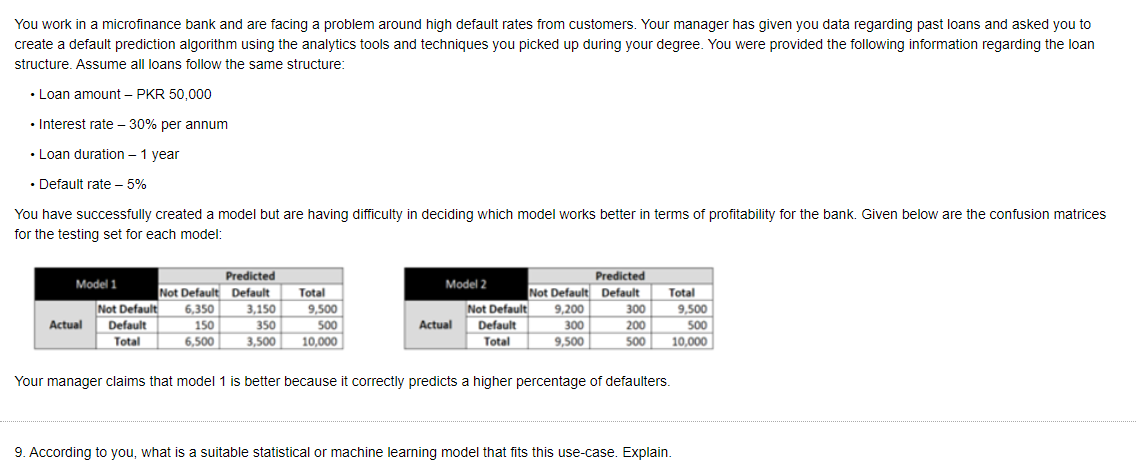
You work in a microfinance bank and are facing a problem around high default rates from customers. Your manager has given you data regarding past
Step by Step Solution
There are 3 Steps involved in it
Step: 1

Get Instant Access to Expert-Tailored Solutions
See step-by-step solutions with expert insights and AI powered tools for academic success
Step: 2

Step: 3
Ace Your Homework with AI
Get the answers you need in no time with our AI-driven, step-by-step assistance
Get Started
Survey Of Accounting
Authors: Thomas Edmonds, Christopher Edmonds, Philip Olds
6th Edition
1260575292, 978-1260575293