Using Java:

Sample Corpus File:
English: https://drive.google.com/file/d/1iYpf3brEDu8ePDFGXHuATC5YaHNrYHr9/view?usp=sharing
***** You can assume corpus files are of the form .corpus.
Sample Results form the Command Line:
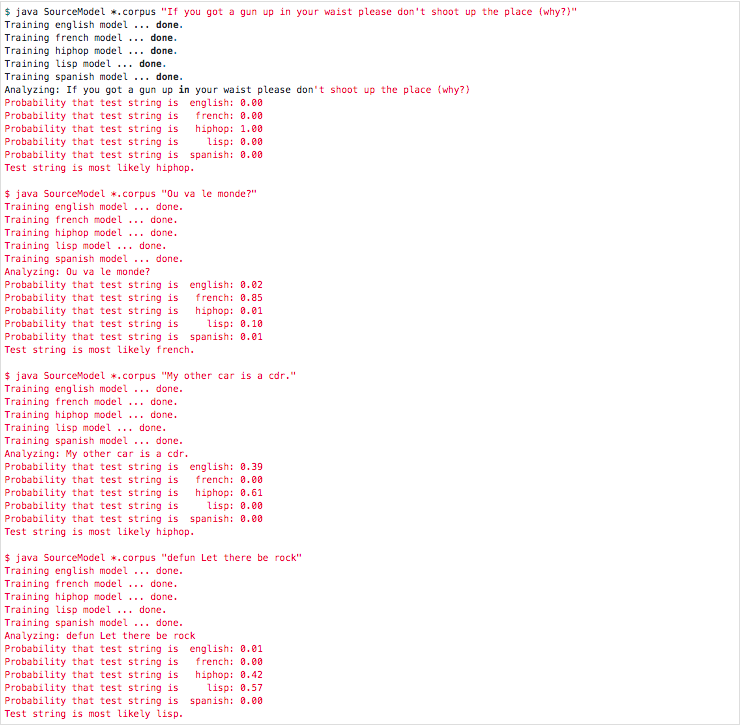
Specific Requirements Write a class called SourceModel with the following constructors and methods: .A single constructor with two String parameters, where the first parameter is the name of the source model and the second is the file name of the corpus file for the model. The constructor should create a letter-letter transition matrix using this recommended algorithm sketch: o Initialize a 26x26 matrix for character counts o Print "Training (name model" o Read the corpus file one character at a time, converting all characters to lower case and ignoring any non-alphabetic character. o For each character, increment the corresponding (row, col) in your counts matrix. The row is the for the previous character, the col is for the current character. (You could also think of this in terms of bigrams.) After you read the entire corpus file, you'll have a matrix of counts. From the matrix of counts, create a matrix of probabilities- each row of the transition matrix is a probability distribution. o o -A probabilities in a distribution must sum to 1. To turn counts into probabilities, divide each count by the sum of all the counts in a row o Print "done." followed by a newline character .A getName method with no parameters which returns the name of the SourceModel. A toString method which returns a string representation of the model like the one shown below under Running Your Program in JShell. A probability method which takes a String and returns a double which indicates the probability that the test string was generated by the source model, using the transition probability matrix created in the constructor. Here's a recommended algorithm: Initialize the probability to 1.0 For each two-character sequences of characters in the test string test, ci and ci+1 for i = 0 to test. length()-1, multiply the probability by the entry in the transition probability matrix for the C1 to c2 transition, which should be found in row ci an column ci+1 n the matrix. (You could also think of the indices as ci-1,4 for 1-1 to test. length()-1.) o o .A main method that makes SourceModel runnable from the command line. You program should take 1 or more corpus file names as command line arguments followed by a quoted string as the last argument. The program should create models for all the corpora and test the string with all the corpora. Here's an algorithm sketch: The first n-1 arguments to the program are corpus file names to use to train models. Corpus files are of the form .corpus The last argument to the program is a quoted string to test. Create a SourceModel object for each corpus Use the models to compute the probability that the test text was produced by the model Probabilities will be very small. Normalize the probabilities of all the model predictions to a probability distribution (so they sum to 1) o o o o o (closed-world assumption -we only state probabilities relative to models we have) o Print results of analysis Specific Requirements Write a class called SourceModel with the following constructors and methods: .A single constructor with two String parameters, where the first parameter is the name of the source model and the second is the file name of the corpus file for the model. The constructor should create a letter-letter transition matrix using this recommended algorithm sketch: o Initialize a 26x26 matrix for character counts o Print "Training (name model" o Read the corpus file one character at a time, converting all characters to lower case and ignoring any non-alphabetic character. o For each character, increment the corresponding (row, col) in your counts matrix. The row is the for the previous character, the col is for the current character. (You could also think of this in terms of bigrams.) After you read the entire corpus file, you'll have a matrix of counts. From the matrix of counts, create a matrix of probabilities- each row of the transition matrix is a probability distribution. o o -A probabilities in a distribution must sum to 1. To turn counts into probabilities, divide each count by the sum of all the counts in a row o Print "done." followed by a newline character .A getName method with no parameters which returns the name of the SourceModel. A toString method which returns a string representation of the model like the one shown below under Running Your Program in JShell. A probability method which takes a String and returns a double which indicates the probability that the test string was generated by the source model, using the transition probability matrix created in the constructor. Here's a recommended algorithm: Initialize the probability to 1.0 For each two-character sequences of characters in the test string test, ci and ci+1 for i = 0 to test. length()-1, multiply the probability by the entry in the transition probability matrix for the C1 to c2 transition, which should be found in row ci an column ci+1 n the matrix. (You could also think of the indices as ci-1,4 for 1-1 to test. length()-1.) o o .A main method that makes SourceModel runnable from the command line. You program should take 1 or more corpus file names as command line arguments followed by a quoted string as the last argument. The program should create models for all the corpora and test the string with all the corpora. Here's an algorithm sketch: The first n-1 arguments to the program are corpus file names to use to train models. Corpus files are of the form .corpus The last argument to the program is a quoted string to test. Create a SourceModel object for each corpus Use the models to compute the probability that the test text was produced by the model Probabilities will be very small. Normalize the probabilities of all the model predictions to a probability distribution (so they sum to 1) o o o o o (closed-world assumption -we only state probabilities relative to models we have) o Print results of analysis




